
我要匹配html的一个<p class>这个标签,但是这个网页里有很多其他的p标签,比如<p class='article'>这样的标签。我不需要其他的p,我就要匹配p class,那么该如何匹配?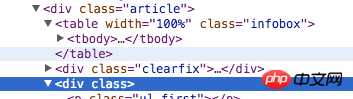



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 6
6 454
454

















可以试试 beautifulsoup
BeautifulSoup指哪打哪.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,"lxml")
art = soup.find("p",attrs={"class":"article"})
print art
建议使用XPath
额,你用的解析库是什么呢?不是直接用正则解析整个页面吧?把问题描述详细点
利用行首、行尾限定符来精确匹配即可。