
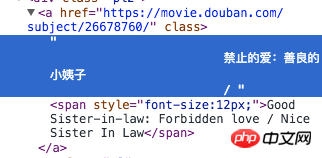
我要的是这个蓝色部分的内容,但是beautifulsoup里两个方法,一个.strings还有一个get_text()都不行,他们会把下面span里的string:Good Sister-in-lwa:Forbidden love这些都抓取。.string直接抓不到,因为这个方法无法判断该抓取哪个string。
所以我该怎么解决标签里内嵌标签的抓取字符串问题



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 4
4 615
615

















https://www.crummy.com/software/BeautifulSoup/bs4/doc/#contents-and-children
@洛克 的想法不錯,把不要的標籤淬出或是移除,再取字串:
或是像 @cloverstd 說的:
總之方法很多,任意組合囉...
我回答過的問題: Python-QA
试试pyquery
把下面标签先取出来,用bs4的函数删掉好象是remove()。
再取上面就行了