
描述你的问题
爬我们学校的门户网站,不知道哪里出了问题,post完最后还是返回到了原页面,没有跳转
贴上相关代码
#!/usr/bin/python
#coding=utf-8
import os
import requests
import webbrowser
from bs4 import BeautifulSoup
#登录的主页面
url = 'https://portal.cug.edu.cn/zfca/login'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0',
'Referer':'https://portal.cug.edu.cn/zfca/login'
}
s = requests.session()
#抓取表单中的一个数据
r = s.get(url, verify=False)
soup=BeautifulSoup(r.content)
input=soup.find_all('input')
lt=input[8]['value']
#抓取验证码
captcha_url = 'https://portal.cug.edu.cn/zfca/captcha.htm?random=0.7590469735536657'
captcha = s.get(captcha_url,verify=False)
f = open('e:/captcha2.jpg', 'wb')
for line in captcha.iter_content():
f.write(line)
f.close()
webbrowser.open('E:\captcha2.jpg')
print u'输入验证码:'
captcha = raw_input()
#构造Post数据
postData = {
'useValidateCode': '0',
'isremenberme': '0',
'usename': '20141002570',
'password': '*******',
'j_captcha_response': captcha,
'losetime':'',
'lt':lt,
'_eventId':'submit',
'submit':'%B5%C7%A1%A1%C2%BC'
}
res=s.post(url,data=postData,headers=headers,verify=False)
print res.headers
print res.status_code
#写入文件
BASE_DIR = os.path.dirname(__file__) #获取当前文件夹的绝对路径
file_path = os.path.join(BASE_DIR, 'cug.txt')
file=open(file_path,'w')
file.write(res.text.encode('gbk'))
file.close()贴上报错信息
贴上相关截图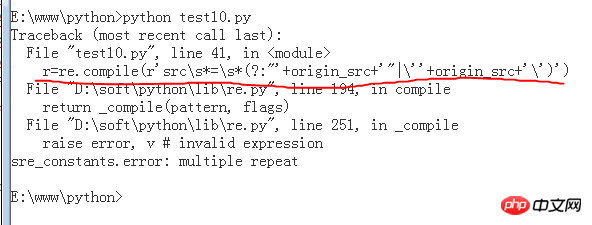
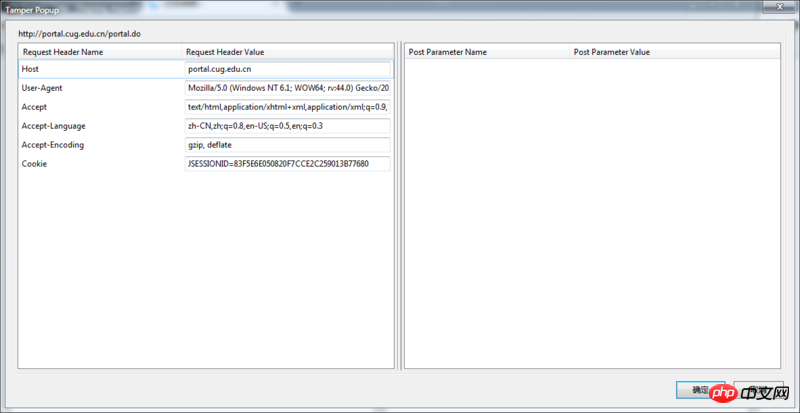
用Tamper抓到的数据



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 2
2 378
378


















找到问题了。。。。。。。。。搞了这么多天,疯了。。。就是因为表单里usename缺了一个r
应该是你没有携带cookie的问题吧。看看下面这个问题吧。
模拟登陆网站如何跳转。