
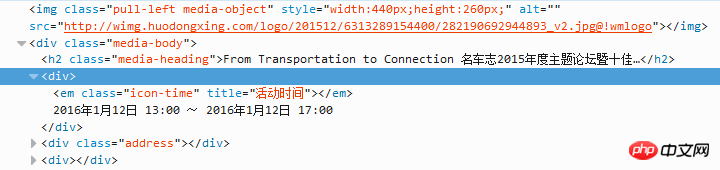
如图,爬取途中的时间部分,网址在此:http://sh.huodongxing.com/event/6313289154400?utm_source=%E5%8F%91%E7%8E%B0%E6%B4%BB%E5%8A%A8%E5%88%97%E8%A1%A8%E9%A1%B5&utm_medium=&utm_campaign=eventspage
我用的是scrapy的selector(基于lxml),
用的xpath语句是://p[1]/p/p[1]/text())[7]
在火狐的xpath checker上测试都可以定位到时间部分,但在爬取时都是\R\N等空字符,后来看到网友的办法:
sel = Selector(response, response.body_as_unicode().replace('\r','').replace('\n',''), 'html')尝试了下,依然有问题(只是把\r\n换成了空格),想请问到底是在哪里出了问题呢



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 1
1 514
514

















用 chrome dev 看到的是最终的页面效果。
你试试查看源代码,在里面找找。因为这段 html 可能是 javascript 处理后的。
如果确认源码里面有,可以:右键 --> Copy --> Copy XPath