
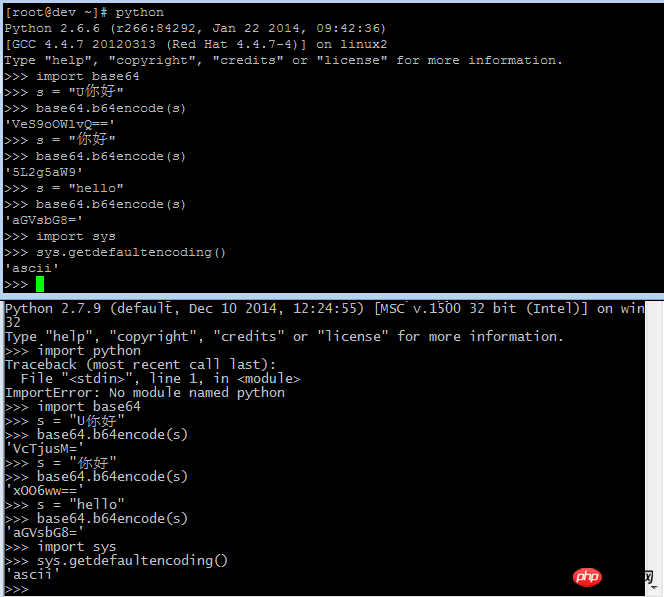
注意,“U你好”只是中英文混写而已,不是写错了。



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 2
2 469
469

















因为你的两个终端的字符编码不同,而不是 Python 的问题。
上面的
s是一个str而u是一个unicode对象。s的值是根据终端的字符编码转换的结果,在 GBK 的终端下>>> s得到'\xc4\xe3\xba\xc3',在 UTF8 的终端下>>> s得到'\xe4\xbd\xa0\xe5\xa5\xbd',但>>> u总是u'\u4f60\u597d'是因为你终端使用的编码不一致造成的
图1,linux终端,是UTF-8编码,验证方法:
应该可以正确(不报错)显示转化成unicode字符了
图2,windows CMD终端,中文100%非utf-8编码,具体什么编码不清楚,身边没有win电脑可以验证