
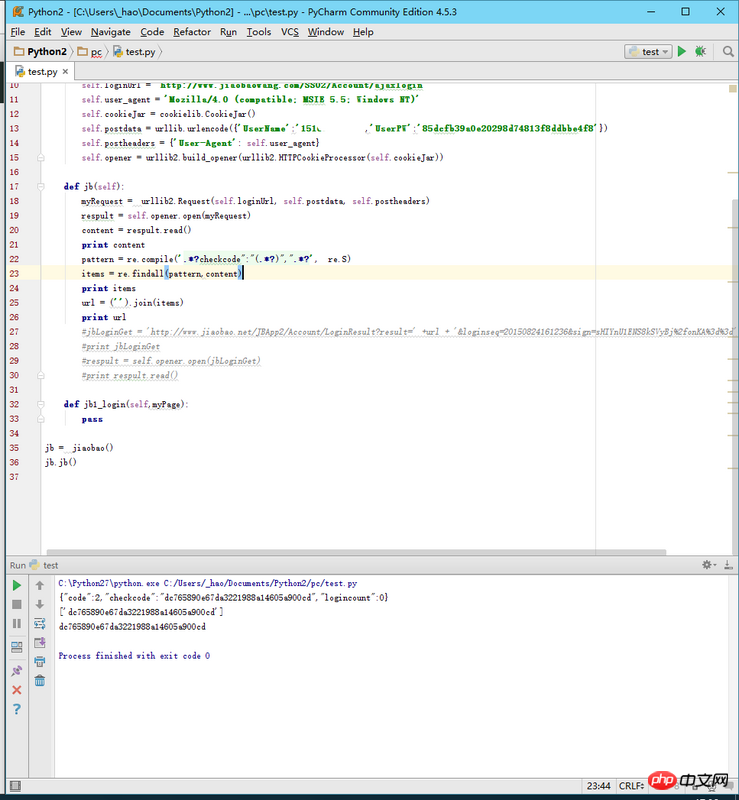
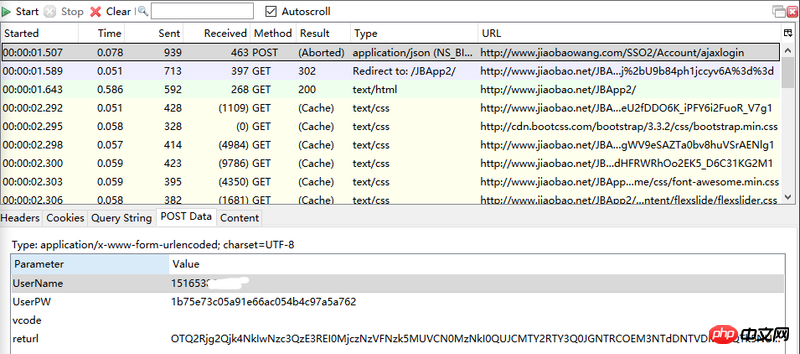
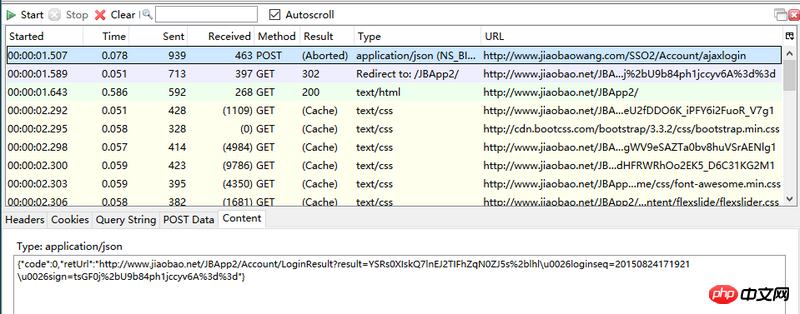
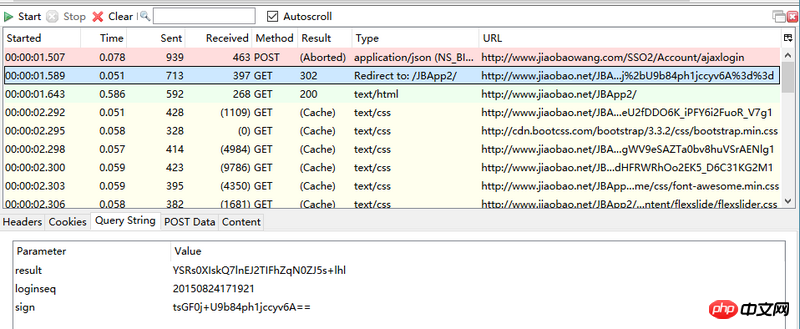
想模拟登陆网站,但登陆网站的页面post发送的密码是经过加密的,并且每次都不重复,post会得到retUrl,里面含有get所需要的信息,但是通过爬虫所获取的并没有retUrl,请问如何获取所需信息
ps:菜鸟一枚,发问题时候才发现了都是随机的,所以代码不对,请勿吐槽,只是想问如何获取到retUrl,而不是图上信息



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 1
1 553
553

















你说的restUrl是你request的data啊,不是response的data,你搞错了。
你说得每次登录都不同,其实是因为它的js中有一个checkcode变量,每次登录失败,都会重置checkcode, js在发起post请求前,都会把密码加密下。你把html爬下来,看里面的源码,在js中有一个checkcode的变量,值用正则匹配出来(存下来),然后把你的密码 + checkcode 用md5 加密下。加密后的十六进制结果就是post的UserPw参数值。如果登录失败了,在response中有一个checkcode字段,把你存的checkcode用返回来的那个替换掉。
我是参考了那网站的js源代码得出的。部分代码