
1.在为表创建索引的过程中,发现当在一个现有的索引最右添加一列后,按照筛选条件看,能缩小查询的范围。然后从explain执行后结果发现,其实扫描的rows有时候反而比加上新的一列后会增多。
而某些情况下,rows的大小并不是和最后的查询时间成反比。
2.比如我的表结构如下:
CREATE TABLE `test` (
`flag` tinyint(4) NOT NULL DEFAULT '0',
`type` smallint(6) NOT NULL DEFAULT '0',
`poid` int(11) NOT NULL DEFAULT '0',
`new_nums` int(11) NOT NULL DEFAULT '0',
`addup_nums` int(11) NOT NULL DEFAULT '0',
`r_time` int(11) NOT NULL DEFAULT '0',
`event_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`dtype` tinyint(6) NOT NULL DEFAULT '1' COMMENT '1.day 2.week 3.month',
`dtime` char(10) NOT NULL DEFAULT '',
KEY `one` (`dtime`,`r_time`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;当我试图在索引one的最后添加一列poid后,我发现,explain执行后的rows反而增多了。
3.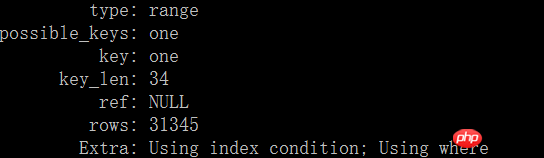
所以,rows究竟是怎么计算出来的呢?



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 1
1 596
596


















这个rows在官网的文档中有解释:
http://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain_rows
The rows column indicates the number of rows MySQL believes it must examine to execute the query.
这个rows就是mysql认为必须要逐行去检查和判断的记录的条数。
举个例子来说,假如有一个语句 select * from t where column_a = 1 and column_b = 2;
全表假设有100条记录,column_a字段有索引(非联合索引),column_b没有索引。
column_a = 1 的记录有20条, column_a = 1 and column_b = 2 的记录有5条。
那么最终查询结果应该显示5条记录。 explain结果中的rows应该是20. 因为这20条记录mysql引擎必须逐行检查是否满足where条件。