
有什么办法可以获取到这部分数据:
网页链接:http://xxfb.hydroinfo.gov.cn/...
网页截图: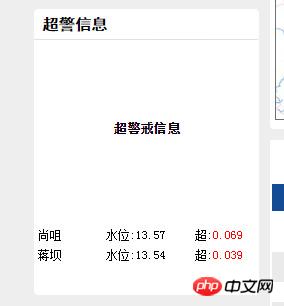
大概思路是使用如下方法获取class为sqjbstyle的td数目,再取出来表格td的内容
但这样打印出来的长度为0,不知道该怎么弄了,请大神指教下,感谢。
代码截图: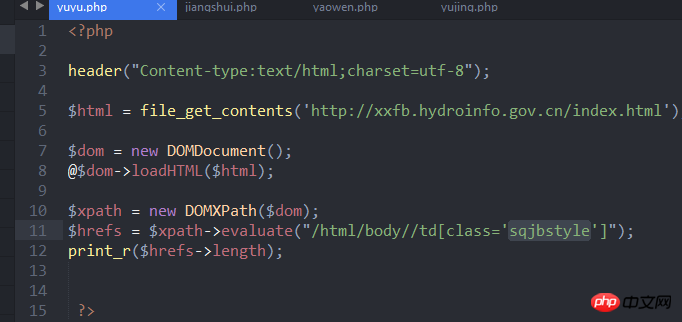



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 3
3 493
493

















提供一个思路:
看看是否可以用iframe来加载,如果可以的话,监听iframe的加载状态,等iframe 加载完毕,获取其HTML内容(此时页面 上的JS已经执行完毕),然后在做内容分解。
也可以看一下他的代码是怎么写的,然后想办法在WEBServer里面跑JS。
http://xxfb.hydroinfo.gov.cn/...
这里面定义了一堆xhr方法,可以看一下他调用了哪些接口,每个接口返回类型是什么,就此写一个文档。
具体代码我就不看了,睡觉去了。
你这样的写法,没办法获取到超警戒信息的表格的。
他应该是通过二次加载的超警信息,有做了防御机制。没办法直接获取,我也不懂。0 0哪个大神能解决下?
超警戒信息链接:

http://xxfb.hydroinfo.gov.cn/...