
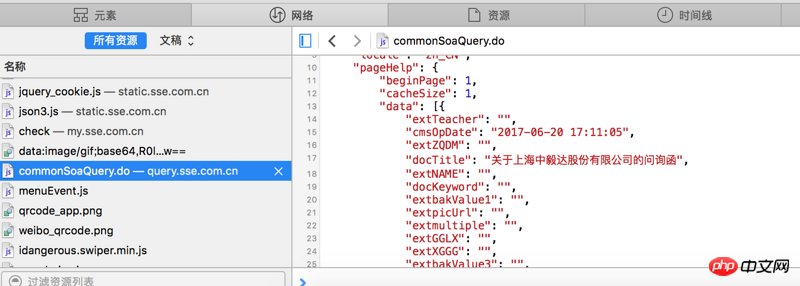
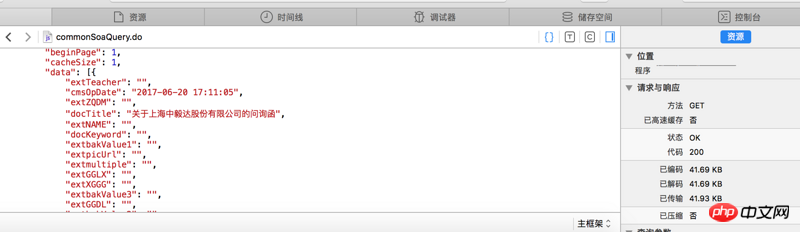
看不清的话 网站地址是http://www.sse.com.cn/disclos...
红字是我需要的内容 但是我提取不出来
求教怎么操作



Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 2
2 879
879
 赞 +0
赞 +0



















