

Transformer could be thinking ahead, but just doesn't do it

Will the language model plan for future tokens? This paper gives you the answer.
"Don't let Yann LeCun see it."
Yann LeCun said it was too late, he had already seen it. The question discussed in the "LeCun must-read" paper I will introduce today is: Is Transformer a thoughtful language model? When it performs inference at a certain location, does it anticipate subsequent locations?
The conclusion of this study is: Transformer has the ability to do this, but does not do so in practice.
We all know that humans think before they speak. Ten years of linguistic research shows that when humans use language, they mentally predict the upcoming language input, words or sentences.
Unlike humans, current language models allocate a fixed amount of calculation to each token when "speaking". So we can’t help but ask: Will language models think in advance like humans?
According to some recent research, it has been shown that the next token can be predicted by probing the hidden state of the language model. Interestingly, by using linear probes on the model's hidden states, the model's output on future tokens can be predicted to a certain extent, and future outputs can be modified predictably. Some recent research has shown that it is possible to predict the next token by probing the hidden states of a language model. Interestingly, by using linear probes on the model's hidden states, the model's output on future tokens can be predicted to a certain extent, and future outputs can be modified predictably.
These findings suggest that model activation at a given time step is at least partially predictive of future output.
However, we don't yet know why: is this just an accidental property of the data, or is it because the model deliberately prepares information for future time steps (but this affects the model's performance at the current location)?
In order to answer this question, three researchers from the University of Colorado Boulder and Cornell University recently published an article titled "Will Language Models Plan for Future Tokens?" 》Thesis.

Paper title: Do Language Models Plan for Future Tokens?
Paper address: https://arxiv.org/pdf/2404.00859.pdf
Research Overview
They observed that the gradient during training optimizes the weights both for the loss at the current token position and for tokens later in the sequence. They further asked: In what proportion will the current transformer weight allocate resources to the current token and future tokens?
They considered two possibilities: the pre-caching hypothesis and the breadcrumbs hypothesis.

The pre-caching hypothesis means that the transformer will calculate at time step t features that are irrelevant to the inference task of the current time step but may be useful for future time steps t τ , while breadcrumbs The assumption is that the features most relevant at time step t are already equivalent to the features that will be most useful at time step t τ .
To evaluate which hypothesis is correct, the team proposed a myopic training scheme that does not propagate the gradient of the loss at the current position to the hidden state at the previous position.
For the mathematical definition and theoretical description of the above assumptions and schemes, please refer to the original paper.
Experimental results
To understand whether it is possible for language models to directly implement precaching, they designed a synthetic scenario in which the task can only be accomplished through explicit precaching . They configured a task in which the model had to precompute information for the next token, otherwise it would not be able to accurately calculate the correct answer in a single pass.

# definition of the synthetic data set built by the team.
In this synthetic scene, the team found clear evidence that transformers can learn to pre-cache. Transformer-based sequence models do this when they must precompute information to minimize loss. They then explored whether natural language models (pretrained GPT-2 variants) would exhibit the breadcrumb hypothesis or the precaching hypothesis. Their experiments with myopic training schemes show that precaching occurs much less often in this setting, so the results are more biased towards the breadcrumb hypothesis.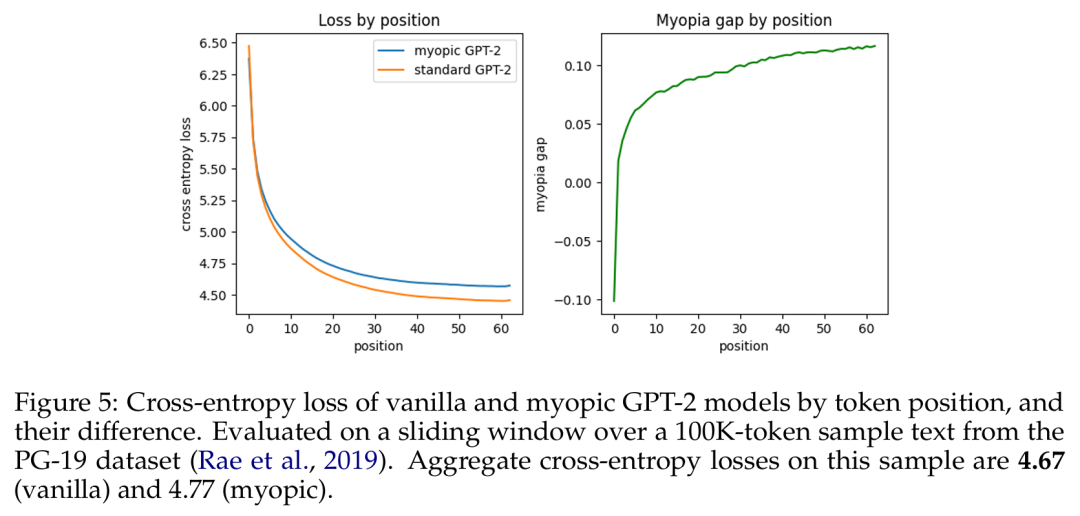
been been been made. The cross-entropy loss and differences between the original GPT-2 model based on token position and the short-sighted GPT-2 model.
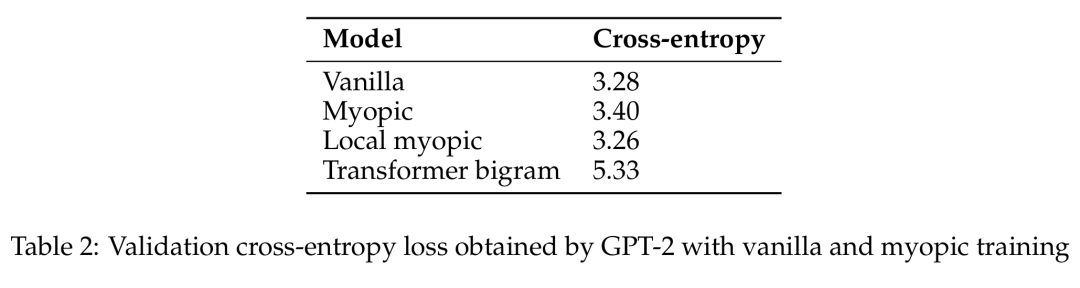
# .
So the team claims: On real language data, language models do not prepare future information to a significant extent. Instead, they are computing features that are useful for predicting the next token — which will also prove useful for future steps.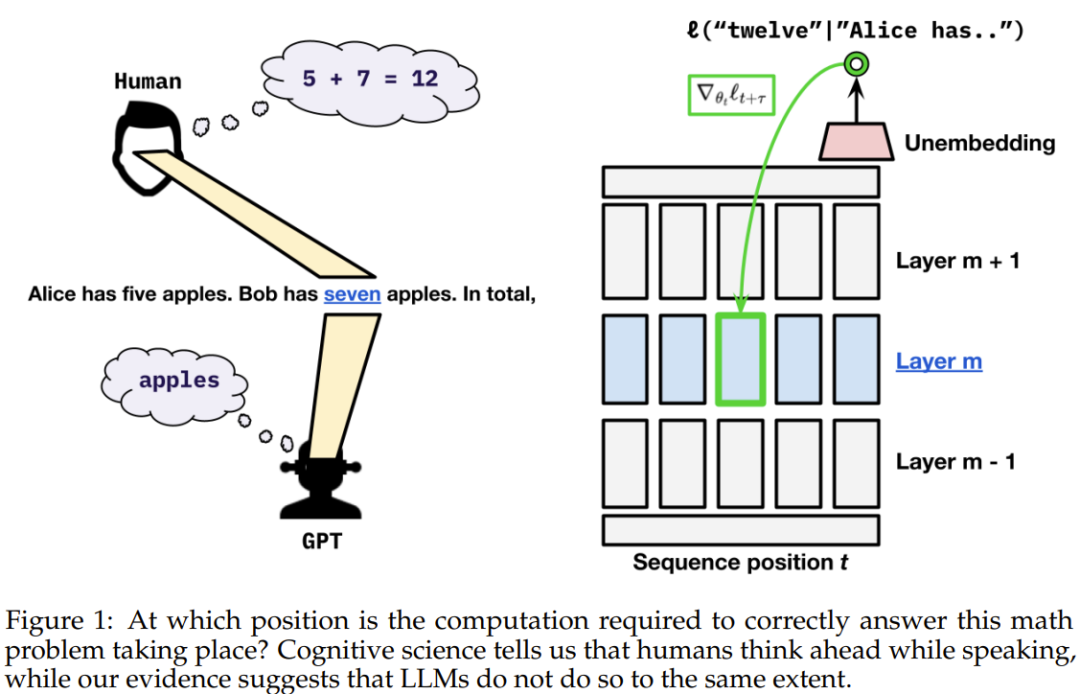

The above is the detailed content of Transformer could be thinking ahead, but just doesn't do it. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
Breaking through the boundaries of traditional defect detection, 'Defect Spectrum' achieves ultra-high-precision and rich semantic industrial defect detection for the first time.
Jul 26, 2024 pm 05:38 PM
In modern manufacturing, accurate defect detection is not only the key to ensuring product quality, but also the core of improving production efficiency. However, existing defect detection datasets often lack the accuracy and semantic richness required for practical applications, resulting in models unable to identify specific defect categories or locations. In order to solve this problem, a top research team composed of Hong Kong University of Science and Technology Guangzhou and Simou Technology innovatively developed the "DefectSpectrum" data set, which provides detailed and semantically rich large-scale annotation of industrial defects. As shown in Table 1, compared with other industrial data sets, the "DefectSpectrum" data set provides the most defect annotations (5438 defect samples) and the most detailed defect classification (125 defect categories
 NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
NVIDIA dialogue model ChatQA has evolved to version 2.0, with the context length mentioned at 128K
Jul 26, 2024 am 08:40 AM
The open LLM community is an era when a hundred flowers bloom and compete. You can see Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 and many other excellent performers. Model. However, compared with proprietary large models represented by GPT-4-Turbo, open models still have significant gaps in many fields. In addition to general models, some open models that specialize in key areas have been developed, such as DeepSeek-Coder-V2 for programming and mathematics, and InternVL for visual-language tasks.
 Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Training with millions of crystal data to solve the crystallographic phase problem, the deep learning method PhAI is published in Science
Aug 08, 2024 pm 09:22 PM
Editor |KX To this day, the structural detail and precision determined by crystallography, from simple metals to large membrane proteins, are unmatched by any other method. However, the biggest challenge, the so-called phase problem, remains retrieving phase information from experimentally determined amplitudes. Researchers at the University of Copenhagen in Denmark have developed a deep learning method called PhAI to solve crystal phase problems. A deep learning neural network trained using millions of artificial crystal structures and their corresponding synthetic diffraction data can generate accurate electron density maps. The study shows that this deep learning-based ab initio structural solution method can solve the phase problem at a resolution of only 2 Angstroms, which is equivalent to only 10% to 20% of the data available at atomic resolution, while traditional ab initio Calculation
 Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
Google AI won the IMO Mathematical Olympiad silver medal, the mathematical reasoning model AlphaProof was launched, and reinforcement learning is so back
Jul 26, 2024 pm 02:40 PM
For AI, Mathematical Olympiad is no longer a problem. On Thursday, Google DeepMind's artificial intelligence completed a feat: using AI to solve the real question of this year's International Mathematical Olympiad IMO, and it was just one step away from winning the gold medal. The IMO competition that just ended last week had six questions involving algebra, combinatorics, geometry and number theory. The hybrid AI system proposed by Google got four questions right and scored 28 points, reaching the silver medal level. Earlier this month, UCLA tenured professor Terence Tao had just promoted the AI Mathematical Olympiad (AIMO Progress Award) with a million-dollar prize. Unexpectedly, the level of AI problem solving had improved to this level before July. Do the questions simultaneously on IMO. The most difficult thing to do correctly is IMO, which has the longest history, the largest scale, and the most negative
 PRO | Why are large models based on MoE more worthy of attention?
Aug 07, 2024 pm 07:08 PM
PRO | Why are large models based on MoE more worthy of attention?
Aug 07, 2024 pm 07:08 PM
In 2023, almost every field of AI is evolving at an unprecedented speed. At the same time, AI is constantly pushing the technological boundaries of key tracks such as embodied intelligence and autonomous driving. Under the multi-modal trend, will the situation of Transformer as the mainstream architecture of AI large models be shaken? Why has exploring large models based on MoE (Mixed of Experts) architecture become a new trend in the industry? Can Large Vision Models (LVM) become a new breakthrough in general vision? ...From the 2023 PRO member newsletter of this site released in the past six months, we have selected 10 special interpretations that provide in-depth analysis of technological trends and industrial changes in the above fields to help you achieve your goals in the new year. be prepared. This interpretation comes from Week50 2023
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 The accuracy rate reaches 60.8%. Zhejiang University's chemical retrosynthesis prediction model based on Transformer was published in the Nature sub-journal
Aug 06, 2024 pm 07:34 PM
The accuracy rate reaches 60.8%. Zhejiang University's chemical retrosynthesis prediction model based on Transformer was published in the Nature sub-journal
Aug 06, 2024 pm 07:34 PM
Editor | KX Retrosynthesis is a critical task in drug discovery and organic synthesis, and AI is increasingly used to speed up the process. Existing AI methods have unsatisfactory performance and limited diversity. In practice, chemical reactions often cause local molecular changes, with considerable overlap between reactants and products. Inspired by this, Hou Tingjun's team at Zhejiang University proposed to redefine single-step retrosynthetic prediction as a molecular string editing task, iteratively refining the target molecular string to generate precursor compounds. And an editing-based retrosynthetic model EditRetro is proposed, which can achieve high-quality and diverse predictions. Extensive experiments show that the model achieves excellent performance on the standard benchmark data set USPTO-50 K, with a top-1 accuracy of 60.8%.
 Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Nature's point of view: The testing of artificial intelligence in medicine is in chaos. What should be done?
Aug 22, 2024 pm 04:37 PM
Editor | ScienceAI Based on limited clinical data, hundreds of medical algorithms have been approved. Scientists are debating who should test the tools and how best to do so. Devin Singh witnessed a pediatric patient in the emergency room suffer cardiac arrest while waiting for treatment for a long time, which prompted him to explore the application of AI to shorten wait times. Using triage data from SickKids emergency rooms, Singh and colleagues built a series of AI models that provide potential diagnoses and recommend tests. One study showed that these models can speed up doctor visits by 22.3%, speeding up the processing of results by nearly 3 hours per patient requiring a medical test. However, the success of artificial intelligence algorithms in research only verifies this
