
 Technology peripherals
AI
Break the curse 36 years ago! Meta launches reverse training method to eliminate the 'reversal curse' of large models
Technology peripherals
AI
Break the curse 36 years ago! Meta launches reverse training method to eliminate the 'reversal curse' of large models
Break the curse 36 years ago! Meta launches reverse training method to eliminate the 'reversal curse' of large models

The "reversal curse" of the large language model has been solved!
This curse was first discovered in September last year, which immediately caused exclamations from LeCun, Karpathy, Marcus and other big guys.

Because the large model with unique scenery and arrogance actually has an "Achilles heel": one in "A is B" The language model trained on the above model cannot correctly answer "whether B is A".
For example, the following example: LLM knows clearly that "Tom Cruise's mother is Mary Lee Pfeiffer", but cannot answer "Mary Lee Pfeiffer's child is Tom" "Cruise".

#——This was the most advanced GPT-4 at the time. As a result, even children could have normal logical thinking, but LLM could not do it.
Based on massive data, I have memorized knowledge that surpasses almost all human beings, yet behaves so dullly. I have obtained the fire of wisdom, but am forever imprisoned in this curse. .

Paper address: https://arxiv.org/pdf/2309.12288v1.pdf
As soon as this happened, the entire network was in an uproar.
On the one hand, netizens said that the big model is really stupid, really. Knowing only "A is B" but not knowing "B is A", I finally retained my dignity as a human being.
On the other hand, researchers have also begun to study this and are working hard to solve this major challenge.
Recently, researchers from Meta FAIR launched a reverse training method to solve the "reversal curse" of LLM in one fell swoop.
Paper address: https://arxiv.org/pdf/2403.13799.pdf
Research We first observed that LLMs train in an autoregressive manner from left to right—which may be responsible for the reversal curse.
So, if you train LLM (reverse training) in the right-to-left direction, it is possible for the model to see the facts in the reverse direction.
Reverse text can be treated as a second language, leveraging multiple different sources through multitasking or cross-language pre-training.
The researchers considered 4 types of reversal: token reversal, word reversal, entity-preserving reversal and random segment reversal.
Token and word reversal, by splitting a sequence into tokens or words respectively, and reversing their order to form a new sequence.
Entity-preserving reverse finds entity names in a sequence and preserves left-to-right word order within them while doing word reversal.
Random segment inversion splits the tokenized sequence into blocks of random length and then preserves the left-to-right order within each block.
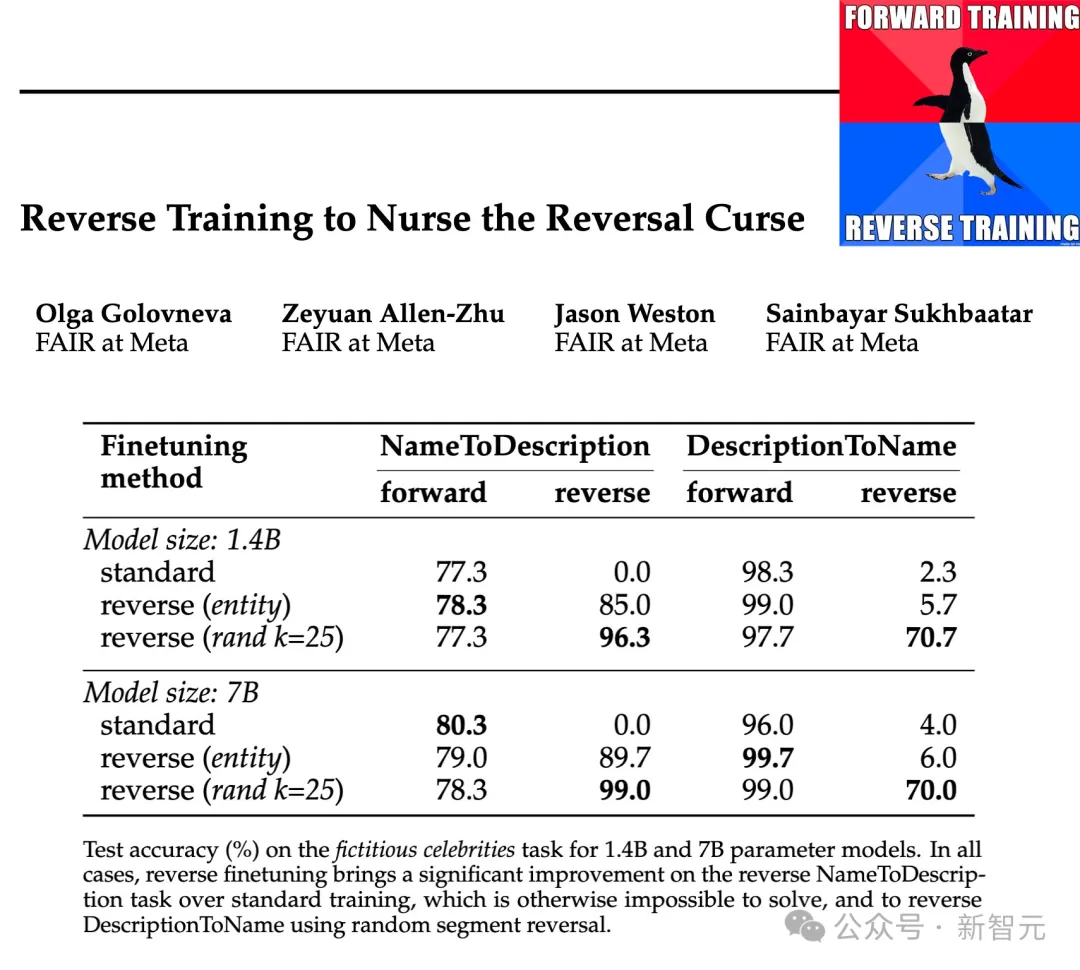
The researchers tested the effectiveness of these inversion types at parameter scales of 1.4B and 7B and showed that entity-preserving and randomized piecewise reverse training can mitigate the inverse curse. , or even eliminate it entirely in some cases.
In addition, the researchers also found that reversing before training improved the performance of the model compared to standard left-to-right training - so reverse training can as a general training method.
Reverse training method
Reverse training includes obtaining a training data set with N samples and constructing a reverse sample set REVERSE (x ).
The function REVERSE is responsible for reversing the given string. The specific method is as follows:
Word reverse: each example is first split for words, then reverse the strings at the word level, concatenating them with spaces.
Entity Preserving Inversion: Run an entity detector on a given training sample, splitting non-entities into words as well. Then the non-entity words are reversed, while the words representing entities retain their original word order.
Random segment inversion: Instead of using an entity detector, we try to use uniform sampling to randomly divide the sequence into segments with a size between 1 and k tokens, and then After reversing the segments but maintaining the word order within each segment, the segments are connected using the special token [REV].
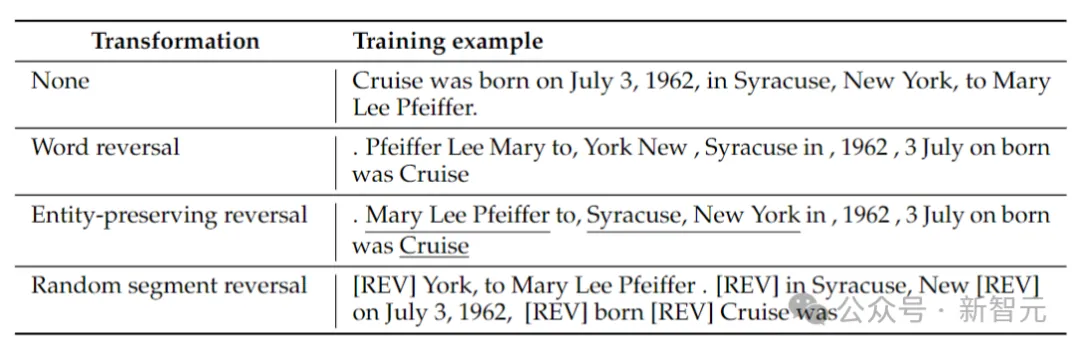
#The above table gives examples of different types of reversal on a given string.
At this time, the language model is still trained from left to right. In the case of word reversal, it is equivalent to predicting sentences from right to left.
Reverse training involves training on standard and reverse examples, so the number of training tokens is doubled, while both forward and reverse training samples are mixed together.
Inverse transformation can be seen as a second language that the model must learn. Please note that during the inversion process, the relationship between facts remains unchanged, and the model can learn from the grammar. to determine whether it is in forward or reverse language prediction mode.
Another perspective of reverse training can be explained by information theory: the goal of language modeling is to learn the probability distribution of natural language
Reverse Task training and testing
Entity pair mapping
First create a simple symbol-based data set to study the inversion curse in a controlled environment.
Randomly pair entities a and b in a one-to-one manner. The training data contains all (a→b) mapping pairs, but only half of the (b→a) mapping pairs, and the other Half is used as test data.
The model must infer the rule a→b ⇔ b→a from the training data and then generalize it to the pairs in the test data.
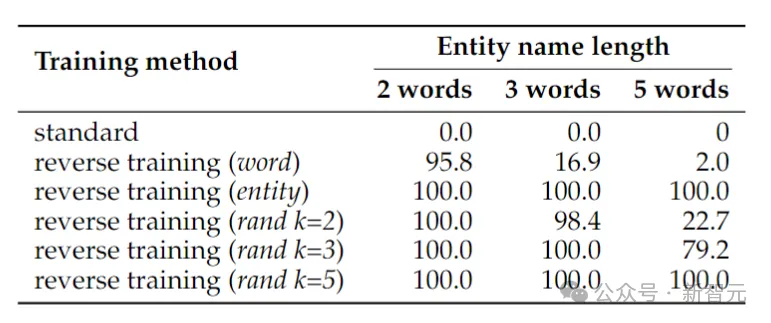
The above table shows the test accuracy (%) of the symbolic reversal task. Despite the simplicity of the task, standard language model training fails completely, suggesting that scaling alone is unlikely to solve it.
In contrast, reverse training can almost solve the problem of two word entities, but its performance drops rapidly as the entities get longer.
Word reversal works fine for shorter entities, but for entities with more words, entity-preserving inversion is necessary. Random segment reversal performs well when the maximum segment length k is at least as long as the entity.
Restore the name
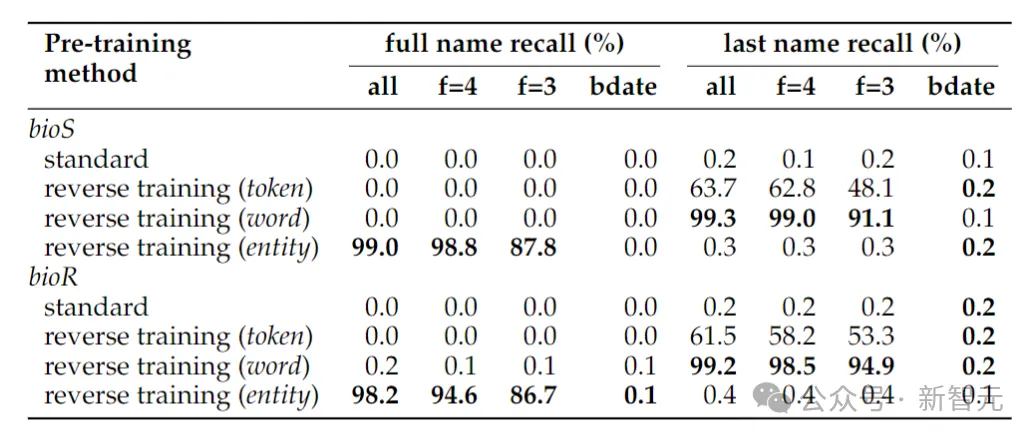
##The above table shows For the inversion task of determining a person's full name, when only the date of birth is given to determine a person's full name, the accuracy of the inversion task is still close to zero - this is because in the entity detection method used in this article, the date Treated as three entities, so their order is not preserved in the inversion.
If the inversion task is reduced to just determining a person's last name, word-level inversion is sufficient.
Another phenomenon that may come as a surprise is that the entity retention method can determine the person's full name, but not the person's last name.
This is a known phenomenon: language models may be completely unable to retrieve late tokens of knowledge fragments (such as last names).
Real World Facts
Here the author trained a Llama-2 with 1.4 billion parameters Model, train a baseline model of 2 trillion tokens in the left-to-right direction.
In contrast, inverse training uses only 1 trillion tokens, but uses the same subset of data to train in both directions, left-to-right and right-to-left. ——The total number of tokens in the two directions is 2 trillion, ensuring fairness and justice in terms of computing resources.
To test reversal of real-world facts, the researchers used a celebrity task that included questions such as "Who is a celebrity's mother?" along with more challenging Reverse questions, such as "Who are the children of a certain celebrity's parents?"
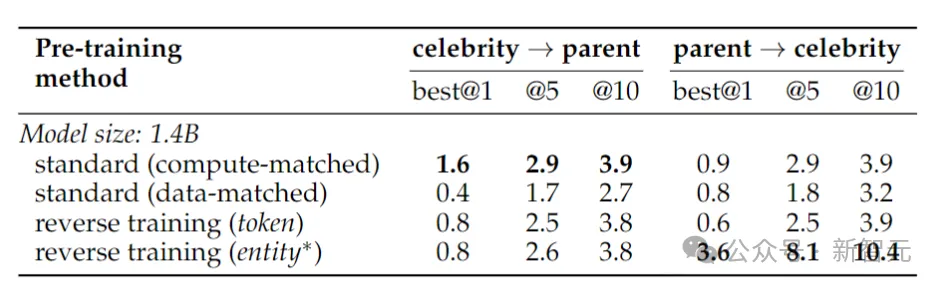
The results are shown in the table above. The researchers sampled the models multiple times for each question and considered it a success if any of them contained the correct answer.
Generally speaking, since the model is small in terms of number of parameters, has limited pre-training, and lacks fine-tuning, the accuracy is usually relatively low. However, reverse training performed even better.
Prophecy 36 years ago
In 1988, Fodor and Pylyshyn published an article about the thinking system in the journal "Cognition" Sexual articles.

If you really understand this world, then you should be able to understand the relationship between a relative to b, and also understand the relative relationship between b relationship to a.
Even non-verbal cognitive creatures should be able to do this.
The above is the detailed content of Break the curse 36 years ago! Meta launches reverse training method to eliminate the 'reversal curse' of large models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1654
1654
 14
1413
52
1306
25
1252
29
1225
24
14
1413
52
1306
25
1252
29
1225
24

 What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
The top ten digital currency exchanges such as Binance, OKX, gate.io have improved their systems, efficient diversified transactions and strict security measures.
 Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
The top ten cryptocurrency trading platforms in the world include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, KuCoin and Poloniex, all of which provide a variety of trading methods and powerful security measures.
 Recommended reliable digital currency trading platforms. Top 10 digital currency exchanges in the world. 2025
Apr 28, 2025 pm 04:30 PM
Recommended reliable digital currency trading platforms. Top 10 digital currency exchanges in the world. 2025
Apr 28, 2025 pm 04:30 PM
Recommended reliable digital currency trading platforms: 1. OKX, 2. Binance, 3. Coinbase, 4. Kraken, 5. Huobi, 6. KuCoin, 7. Bitfinex, 8. Gemini, 9. Bitstamp, 10. Poloniex, these platforms are known for their security, user experience and diverse functions, suitable for users at different levels of digital currency transactions
 What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
Currently ranked among the top ten virtual currency exchanges: 1. Binance, 2. OKX, 3. Gate.io, 4. Coin library, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9. Bitcoin, 10. bit stamp.
 Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0 redefines crypto asset management through innovative architecture and performance breakthroughs. 1) It solves three major pain points: asset silos, income decay and paradox of security and convenience. 2) Through intelligent asset hubs, dynamic risk management and return enhancement engines, cross-chain transfer speed, average yield rate and security incident response speed are improved. 3) Provide users with asset visualization, policy automation and governance integration, realizing user value reconstruction. 4) Through ecological collaboration and compliance innovation, the overall effectiveness of the platform has been enhanced. 5) In the future, smart contract insurance pools, forecast market integration and AI-driven asset allocation will be launched to continue to lead the development of the industry.
 How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
Bitcoin’s price ranges from $20,000 to $30,000. 1. Bitcoin’s price has fluctuated dramatically since 2009, reaching nearly $20,000 in 2017 and nearly $60,000 in 2021. 2. Prices are affected by factors such as market demand, supply, and macroeconomic environment. 3. Get real-time prices through exchanges, mobile apps and websites. 4. Bitcoin price is highly volatile, driven by market sentiment and external factors. 5. It has a certain relationship with traditional financial markets and is affected by global stock markets, the strength of the US dollar, etc. 6. The long-term trend is bullish, but risks need to be assessed with caution.
 Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
The top ten cryptocurrency exchanges in the world in 2025 include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, KuCoin, Bittrex and Poloniex, all of which are known for their high trading volume and security.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
