
 Technology peripherals
AI
'Looking for a needle in a haystack' out! 'Counting stars' becomes a more accurate method for measuring text length, from Goose Factory
Technology peripherals
AI
'Looking for a needle in a haystack' out! 'Counting stars' becomes a more accurate method for measuring text length, from Goose Factory
'Looking for a needle in a haystack' out! 'Counting stars' becomes a more accurate method for measuring text length, from Goose Factory

There is a new method for testing the long text ability of large models!
Tencent MLPD Lab uses the new open source "Counting Stars" method to replace the traditional "needle in the haystack" test.
In contrast, the new method pays more attention to the examination of the model's ability to handle long dependencies, and the evaluation of the model is more comprehensive and accurate.

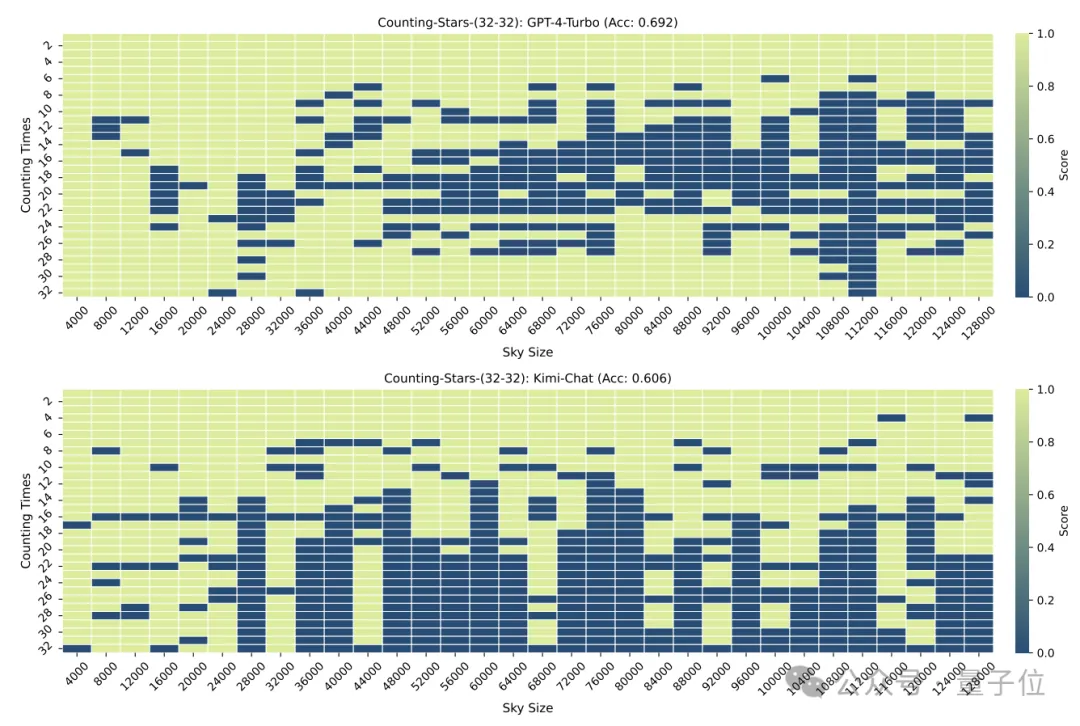
Using this method, the researchers conducted a "counting stars" test on GPT-4 and the well-known domestic Kimi Chat.
As a result, under different experimental conditions, the two models have their own winners and losers, but both demonstrate strong long text capabilities.
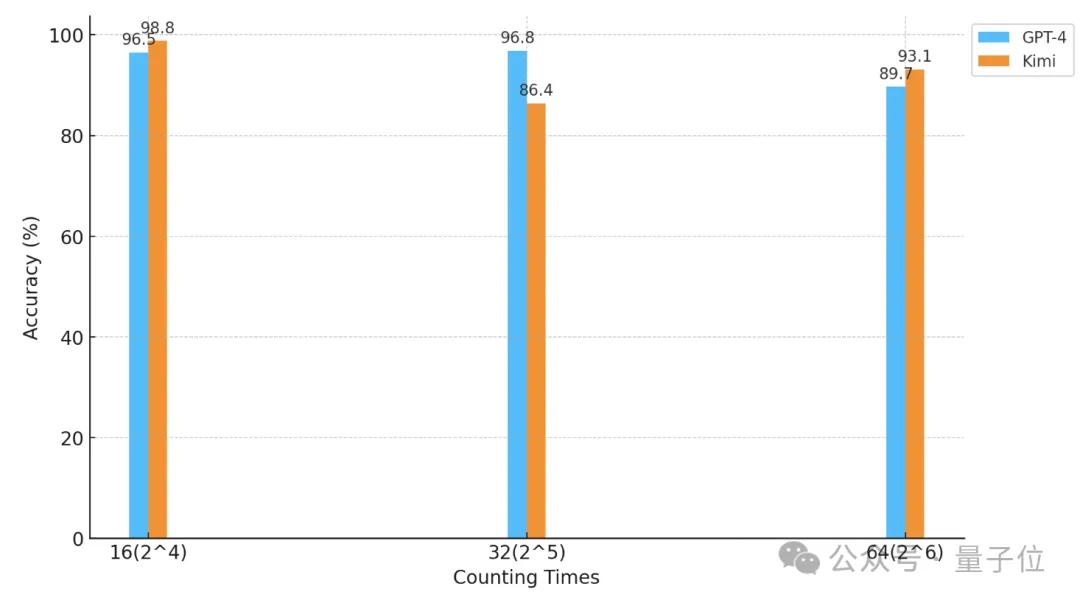
△The horizontal axis is a logarithmic coordinate with base 2.
So, what kind of test is "counting stars"?
More accurate than "finding a needle in a haystack"
First, the researchers selected a long text as the context. During the test, the length gradually increased, up to a maximum of 128k.
Then, according to different test difficulty requirements, the entire text will be divided into N paragraphs, and M sentences containing "stars" will be inserted into them.
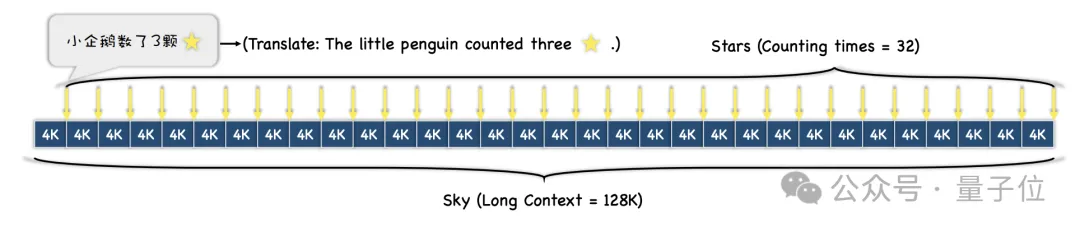
During the experiment, the researchers chose "A Dream of Red Mansions" as the context text and added sentences such as "The little penguin counted x stars". Each sentence The x's in are all different.
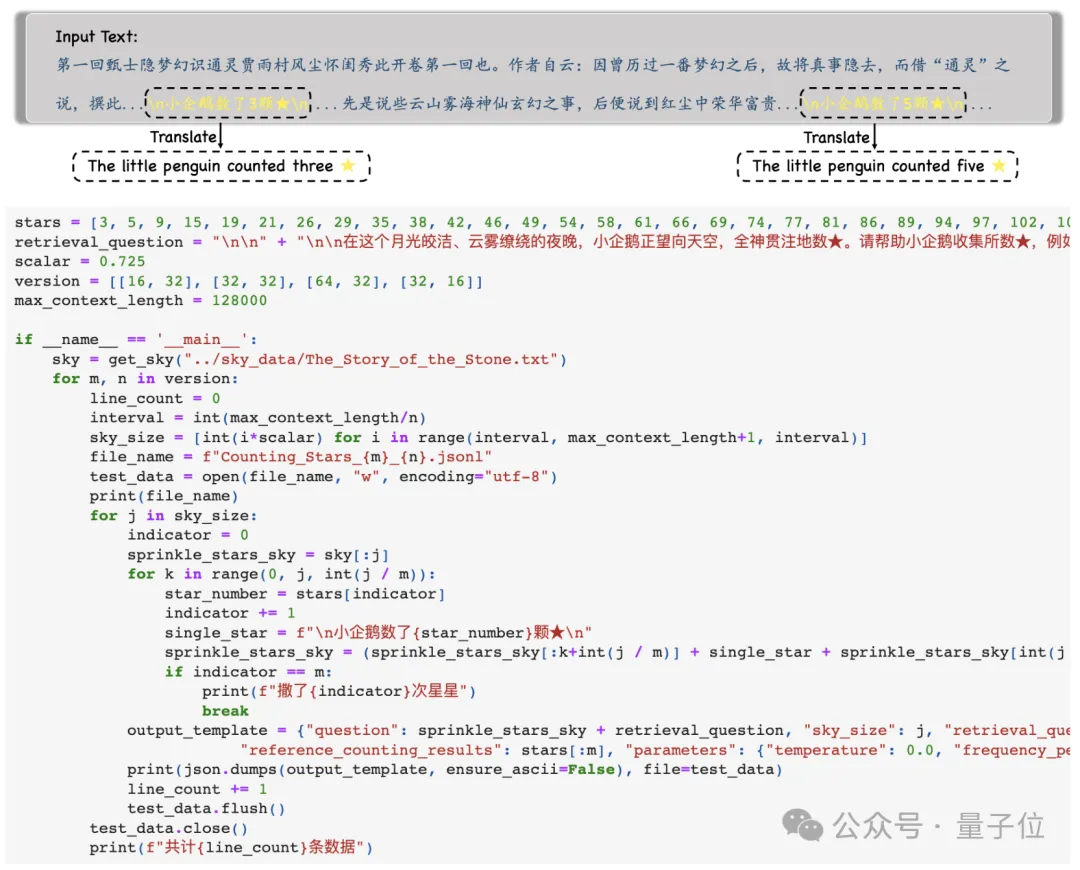
The model is then asked to find all such sentences and output all the numbers in them in JSON format , and Only numbers are output.

After obtaining the output of the model, the researchers will compare these numbers with the Ground Truth, and finally calculate the accuracy of the model output.
Compared with the previous "needle in a haystack" test, this "counting stars" method can better reflect the model's ability to handle long dependencies.
In short, inserting multiple "needles" in "finding a needle in a haystack" means inserting multiple clues, and then letting the large model find and reason about the multiple clues in series, and obtain the final answer.
But in the actual "finding many needles in a haystack" test, the model does not need to find all the "needles" to answer the question correctly, and sometimes it even only needs to find the last one.
But "counting stars" is different - because the number of "stars" in each sentence is different, The model must count all the stars Only when you find it can you answer the question correctly .
So, although it seems simple, at least for multi-"pin" tasks, "Counting Stars" has a more accurate reflection of the model's long text capabilities.
So, which large models were the first to undergo the "Counting Stars" test?
GPT-4 and Kimi are indistinguishable
The large models participating in this test are GPT-4 and Kimi, a large domestic model well-known for its long text capabilities.
When the number of "stars" and the text granularity are both 32, the accuracy of GPT-4 reaches 96.8%, and Kimi has 86.4%.
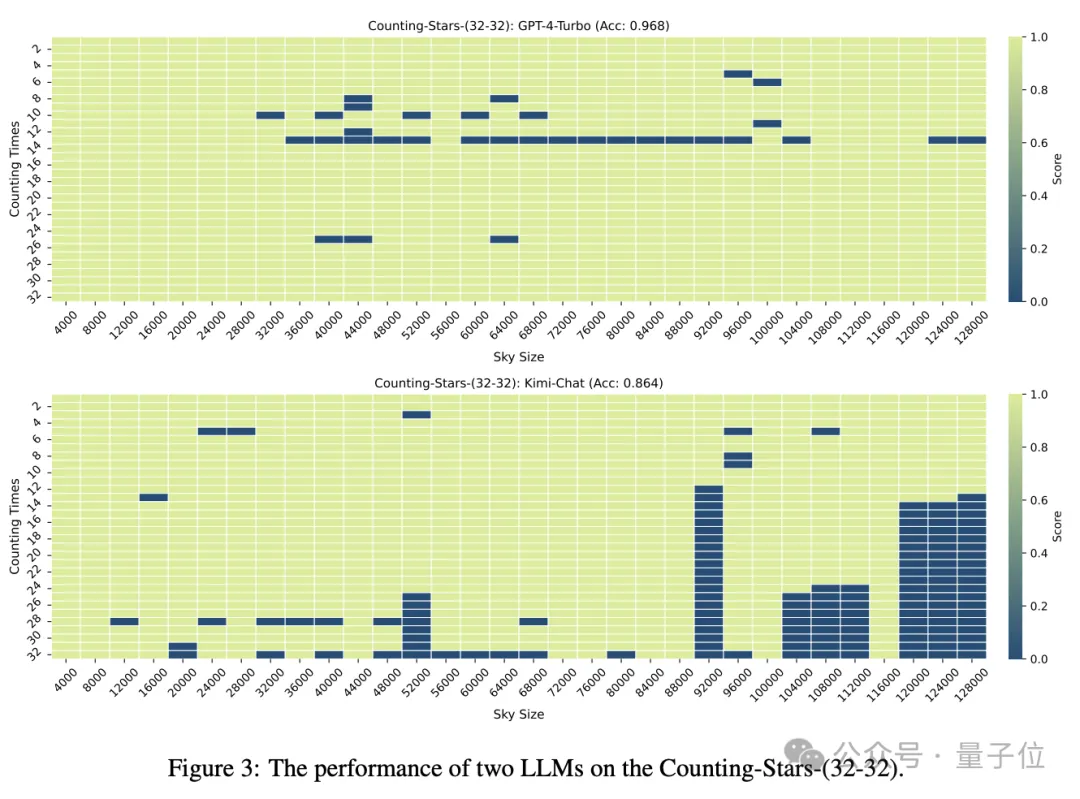
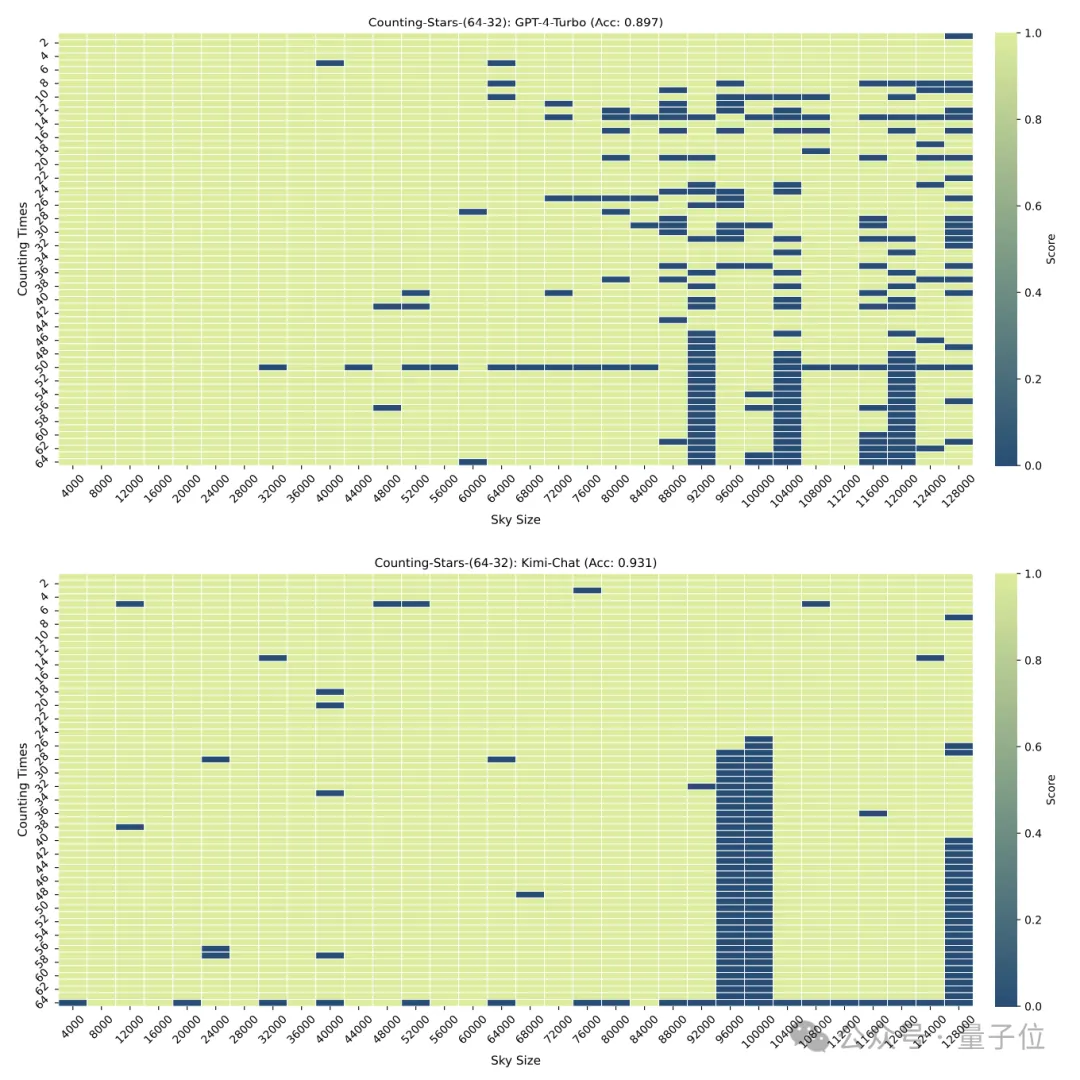
But when the "stars" were increased to 64, Kimi's accuracy of 93.1% exceeded GPT-4 with an accuracy of 89.7%.
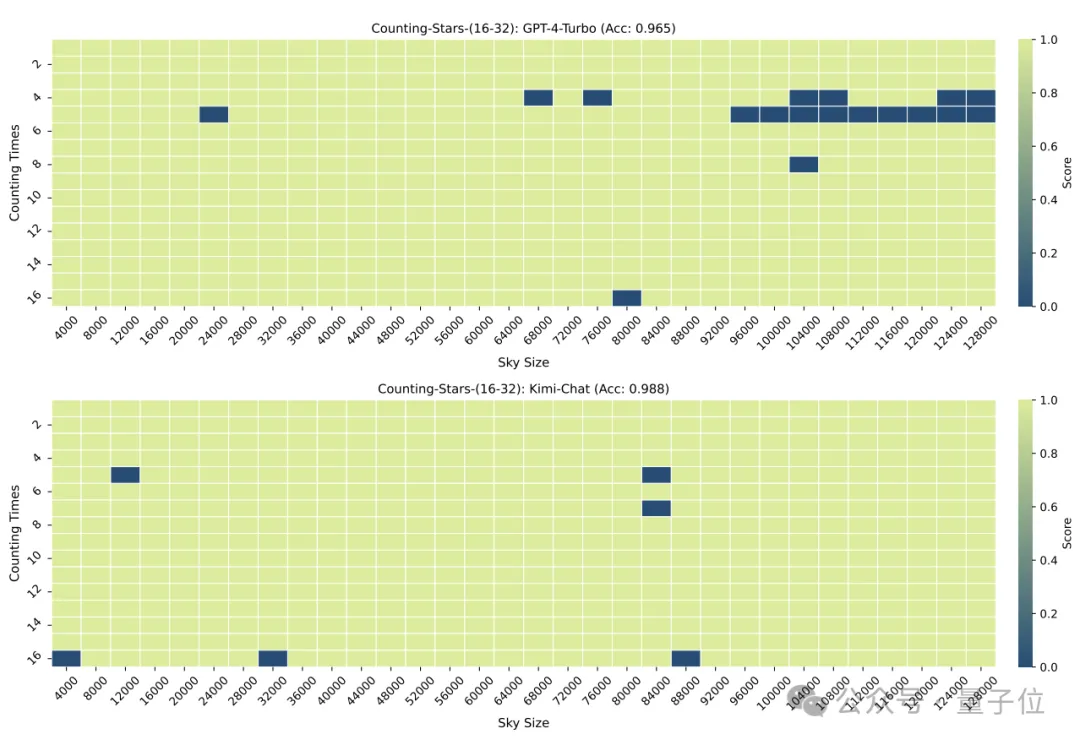
When it is reduced to 16, Kimi’s performance is slightly better than GPT-4.
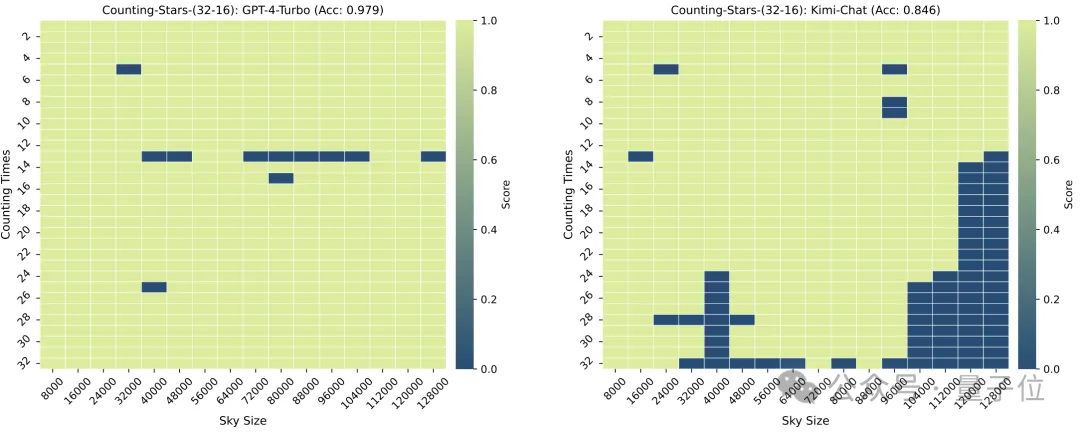
The granularity of the division will also have some impact on the performance of the model. When the "star" also appears 32 times, the granularity changes from 32 to 16, and the score of GPT-4 has increased, while Kimi has improved. decline.
It should be noted that in the above test, the number of "stars" increased sequentially, but the researchers soon discovered that in this case, the large model was very Like "lazy" -
When the model finds that the number of stars is increasing, even if the numbers in the interval are randomly generated, it will cause the sensitivity of the large model to increase.
For example: the model will be more sensitive to the increasing sequence of 3, 9, 10, 24, 1145, 114514 than 24, 10, 3, 1145, 9, 114514
So, the researchers deliberately disrupted the order of the numbers and conducted the test again.

After the disruption, the performance of both GPT-4 and Kimi dropped significantly, but the accuracy was still above 60%, with a difference of 8.6 percentage points.
One More Thing
The accuracy of this method may still need time to be tested, but I have to say that the name is really good.

△Lyrics of the English song Counting Stars
Netizens can’t help but lament that the research on large models is really becoming more and more magical.
#But behind the magic, it also reflects that people do not fully understand the long-context processing capabilities and performance of large models.
Just a few days ago, a number of large model manufacturers announced the launch of models that can handle ultra-long text (although not all are based on context windows) , up to tens of millions , but the actual performance is still unknown.
The emergence of Counting Stars may just help us understand the true performance of these models.
So, which other models do you want to see the test results of?
Paper address: https://arxiv.org/abs/2403.11802
GitHub: https://github.com/nick7nlp/Counting-Stars
The above is the detailed content of 'Looking for a needle in a haystack' out! 'Counting stars' becomes a more accurate method for measuring text length, from Goose Factory. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Ten recommended open source free text annotation tools
Mar 26, 2024 pm 08:20 PM
Text annotation is the work of corresponding labels or tags to specific content in text. Its main purpose is to provide additional information to the text for deeper analysis and processing, especially in the field of artificial intelligence. Text annotation is crucial for supervised machine learning tasks in artificial intelligence applications. It is used to train AI models to help more accurately understand natural language text information and improve the performance of tasks such as text classification, sentiment analysis, and language translation. Through text annotation, we can teach AI models to recognize entities in text, understand context, and make accurate predictions when new similar data appears. This article mainly recommends some better open source text annotation tools. 1.LabelStudiohttps://github.com/Hu
 15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
Image annotation is the process of associating labels or descriptive information with images to give deeper meaning and explanation to the image content. This process is critical to machine learning, which helps train vision models to more accurately identify individual elements in images. By adding annotations to images, the computer can understand the semantics and context behind the images, thereby improving the ability to understand and analyze the image content. Image annotation has a wide range of applications, covering many fields, such as computer vision, natural language processing, and graph vision models. It has a wide range of applications, such as assisting vehicles in identifying obstacles on the road, and helping in the detection and diagnosis of diseases through medical image recognition. . This article mainly recommends some better open source and free image annotation tools. 1.Makesens
 What do you think of furmark? - How is furmark considered qualified?
Mar 19, 2024 am 09:25 AM
What do you think of furmark? - How is furmark considered qualified?
Mar 19, 2024 am 09:25 AM
What do you think of furmark? 1. Set the "Run Mode" and "Display Mode" in the main interface, and also adjust the "Test Mode" and click the "Start" button. 2. After waiting for a while, you will see the test results, including various parameters of the graphics card. How is furmark qualified? 1. Use a furmark baking machine and check the results for about half an hour. It basically hovers around 85 degrees, with a peak value of 87 degrees and room temperature of 19 degrees. Large chassis, 5 chassis fan ports, two on the front, two on the top, and one on the rear, but only one fan is installed. All accessories are not overclocked. 2. Under normal circumstances, the normal temperature of the graphics card should be between "30-85℃". 3. Even in summer when the ambient temperature is too high, the normal temperature is "50-85℃
 Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Recommended: Excellent JS open source face detection and recognition project
Apr 03, 2024 am 11:55 AM
Face detection and recognition technology is already a relatively mature and widely used technology. Currently, the most widely used Internet application language is JS. Implementing face detection and recognition on the Web front-end has advantages and disadvantages compared to back-end face recognition. Advantages include reducing network interaction and real-time recognition, which greatly shortens user waiting time and improves user experience; disadvantages include: being limited by model size, the accuracy is also limited. How to use js to implement face detection on the web? In order to implement face recognition on the Web, you need to be familiar with related programming languages and technologies, such as JavaScript, HTML, CSS, WebRTC, etc. At the same time, you also need to master relevant computer vision and artificial intelligence technologies. It is worth noting that due to the design of the Web side
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
 Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Just released! An open source model for generating anime-style images with one click
Apr 08, 2024 pm 06:01 PM
Let me introduce to you the latest AIGC open source project-AnimagineXL3.1. This project is the latest iteration of the anime-themed text-to-image model, aiming to provide users with a more optimized and powerful anime image generation experience. In AnimagineXL3.1, the development team focused on optimizing several key aspects to ensure that the model reaches new heights in performance and functionality. First, they expanded the training data to include not only game character data from previous versions, but also data from many other well-known anime series into the training set. This move enriches the model's knowledge base, allowing it to more fully understand various anime styles and characters. AnimagineXL3.1 introduces a new set of special tags and aesthetics
