
 Technology peripherals
AI
In addition to CNN, Transformer, and Uniformer, we finally have more efficient video understanding technology
Technology peripherals
AI
In addition to CNN, Transformer, and Uniformer, we finally have more efficient video understanding technology
In addition to CNN, Transformer, and Uniformer, we finally have more efficient video understanding technology

The core goal of video understanding is to accurately understand spatiotemporal representation, but it faces two main challenges: there is a large amount of spatiotemporal redundancy in short video clips, and complex spatiotemporal dependencies. Three-dimensional convolutional neural networks (CNN) and video transformers have performed well in solving one of these challenges, but they have certain shortcomings in addressing both challenges simultaneously. UniFormer attempts to combine the advantages of both approaches, but encounters difficulties in modeling long videos.
The emergence of low-cost solutions such as S4, RWKV and RetNet in the field of natural language processing has opened up new avenues for visual models. Mamba stands out with its Selective State Space Model (SSM), which achieves a balance of maintaining linear complexity while facilitating long-term dynamic modeling. This innovation drives its application in vision tasks, as demonstrated by Vision Mamba and VMamba, which exploit multi-directional SSM to enhance 2D image processing. These models are comparable in performance to attention-based architectures while significantly reducing memory usage.
Given that the sequences produced by videos are inherently longer, a natural question is: does Mamba work well for video understanding?
Inspired by Mamba, this article introduces VideoMamba, an SSM (Selective State Space Model) specifically tailored for video understanding. VideoMamba draws on the design philosophy of Vanilla ViT and combines convolution and attention mechanisms. It provides a linear complexity method for dynamic spatiotemporal background modeling, especially suitable for processing high-resolution long videos. The evaluation mainly focuses on four key capabilities of VideoMamba:
Scalability in the visual field: This article evaluates the scalability of VideoMamba The performance was tested and found that the pure Mamba model is often prone to overfitting when it continues to expand. This paper introduces a simple and effective self-distillation strategy, so that as the model and input size increase, VideoMamba can be used without the need for large-scale data sets. Achieve significant performance enhancements without pre-training.
Sensitivity to short-term action recognition: The analysis in this paper is extended to evaluate VideoMamba’s ability to accurately distinguish short-term actions, especially those with Actions with subtle motion differences, such as opening and closing. Research results show that VideoMamba exhibits excellent performance over existing attention-based models. More importantly, it is also suitable for mask modeling, further enhancing its temporal sensitivity.
Superiority in long video understanding: This article evaluates VideoMamba’s ability to interpret long videos. With end-to-end training, it demonstrates significant advantages over traditional feature-based methods. Notably, VideoMamba runs 6x faster than TimeSformer on 64-frame video and requires 40x less GPU memory (shown in Figure 1).

Compatibility with other modalities: Finally, this article evaluates the adaptability of VideoMamba with other modalities. Results in video text retrieval show improved performance compared to ViT, especially in long videos with complex scenarios. This highlights its robustness and multimodal integration capabilities.
In-depth experiments in this study reveal VideoMamba’s great potential for short-term (K400 and SthSthV2) and long-term (Breakfast, COIN and LVU) video content understanding. VideoMamba demonstrates high efficiency and accuracy, indicating that it will become a key component in the field of long video understanding. To facilitate future research, all code and models have been made open source.

- Paper address: https://arxiv.org/pdf/2403.06977.pdf
- Project address: https://github.com/OpenGVLab/VideoMamba
- Paper title: VideoMamba: State Space Model for Efficient Video Understanding
Method introduction
Figure 2a below shows the details of the Mamba module.

Figure 3 illustrates the overall framework of VideoMamba. This paper first uses 3D convolution (i.e. 1×16×16) to project the input video Xv ∈ R 3×T ×H×W into L non-overlapping spatio-temporal patches Xp ∈ R L×C, where L=t×h×w (t=T, h= H 16, and w= W 16). The token sequence input to the next VideoMamba encoder is 

Spatiotemporal scanning: To apply the B-Mamba layer to the spatiotemporal input, In Figure 4 of this article, the original 2D scan is expanded into different bidirectional 3D scans:
(a) Spatial first, organize spatial tokens by position, and then stack them frame by frame;
(b) Time priority, arrange time tokens according to frames, and then stack them along the spatial dimension;
(c) Space-time mixing, both space priority and There is time priority, where v1 executes half of it and v2 executes all (2 times the calculation amount).
The experiments in Figure 7a show that space-first bidirectional scanning is the most efficient yet simplest. Due to Mamba's linear complexity, VideoMamba in this article can efficiently process high-resolution long videos.

For SSM in the B-Mamba layer, this article uses the same default hyperparameter settings as Mamba, setting the state dimension and expansion ratio to 16 and 2 respectively. Following ViT's approach, this paper adjusts the depth and embedding dimensions to create models of comparable size to those in Table 1, including VideoMamba-Ti, VideoMamba-S and VideoMamba-M. However, it was observed in experiments that larger VideoMamba is often prone to overfitting in experiments, resulting in suboptimal performance as shown in Figure 6a. This overfitting problem exists not only in the model proposed in this paper, but also in VMamba, where the best performance of VMamba-B is achieved at three-quarters of the total training period. To combat the overfitting problem of larger Mamba models, this paper introduces an effective self-distillation strategy that uses smaller and well-trained models as "teachers" to guide the training of larger "student" models. The results shown in Figure 6a show that this strategy leads to the expected better convergence.


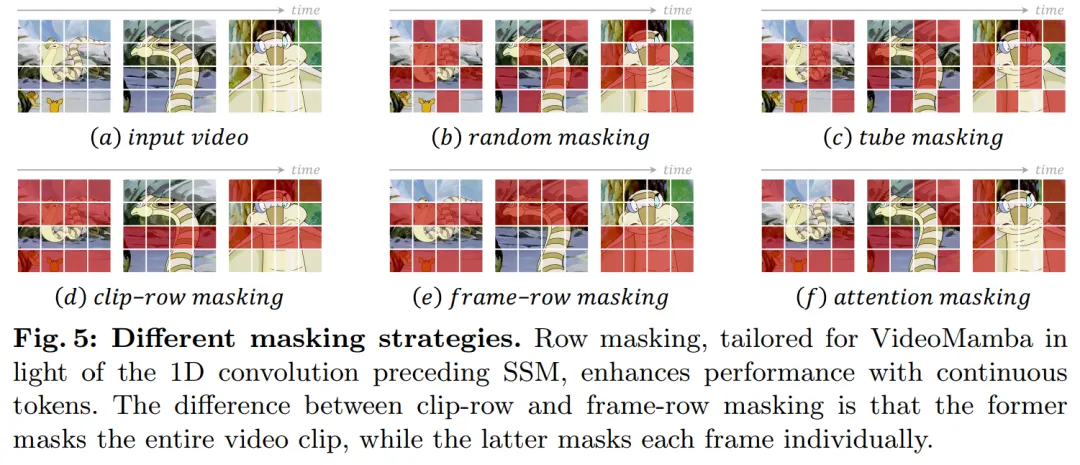
Regarding the masking strategy, this article proposes different row masking techniques, as shown in Figure 5 , specifically for the B-Mamba block's preference for consecutive tokens.
Experiment
Table 2 shows the results on the ImageNet-1K dataset. Notably, VideoMamba-M significantly outperforms other isotropic architectures, improving by 0.8% compared to ConvNeXt-B and 2.0% compared to DeiT-B, while using fewer parameters. VideoMamba-M also performs well in a non-isotropic backbone structure that employs layered features for enhanced performance. Given Mamba's efficiency in processing long sequences, this paper further improves performance by increasing the resolution, achieving 84.0% top-1 accuracy using only 74M parameters.
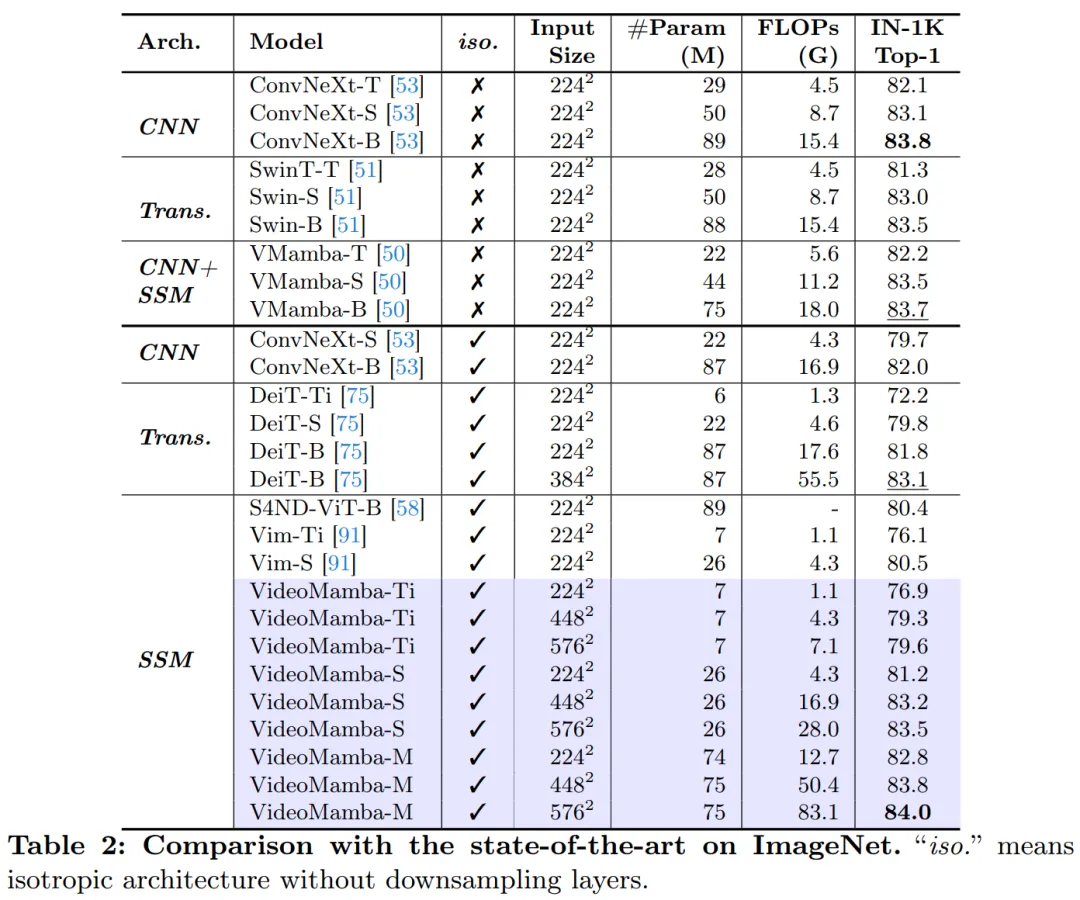
Table 3 and Table 4 list the results on the short-term video dataset. (a) Supervised learning: Compared with pure attention methods, VideoMamba-M based on SSM gained obvious advantages, outperforming ViViT-L on the scene-related K400 and time-related Sth-SthV2 datasets respectively. 2.0% and 3.0%. This improvement comes with significantly reduced computational requirements and less pre-training data. VideoMamba-M's results are on par with SOTA UniFormer, which cleverly integrates convolution and attention in a non-isotropic architecture. (b) Self-supervised learning: With mask pre-training, VideoMamba outperforms VideoMAE, which is known for its fine motor skills. This achievement highlights the potential of our pure SSM-based model to understand short-term videos efficiently and effectively, emphasizing its suitability for both supervised and self-supervised learning paradigms.


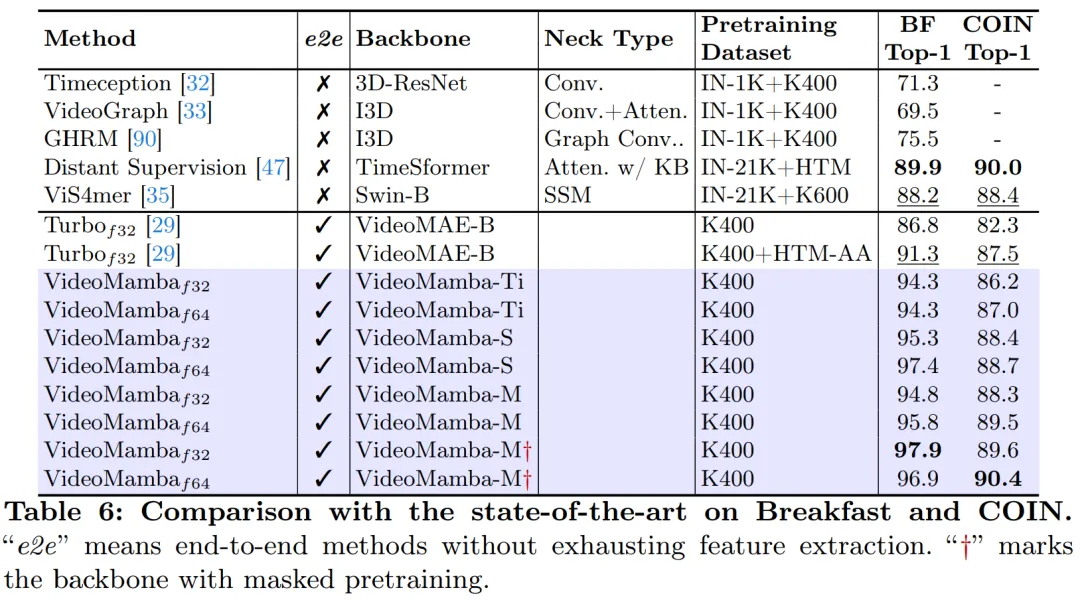
As shown in Figure 1, VideoMamba’s linear complexity makes it very suitable for end-to-end training with long videos. . The comparison in Tables 6 and 7 highlights the simplicity and effectiveness of VideoMamba over traditional feature-based methods in these tasks. It brings significant performance improvements, enabling SOTA results even at smaller model sizes. VideoMamba-Ti shows a significant 6.1% improvement over ViS4mer using Swin-B features, and also a 3.0% improvement over Turbo's multi-modal alignment method. Notably, the results highlight the positive impact of scaling models and frame rates for long-term tasks. On nine diverse and challenging tasks proposed by LVU, this paper adopts an end-to-end approach to fine-tune VideoMamba-Ti and achieves results that are comparable to or superior to current SOTA methods. These results not only highlight the effectiveness of VideoMamba, but also demonstrate its great potential for future long video understanding.
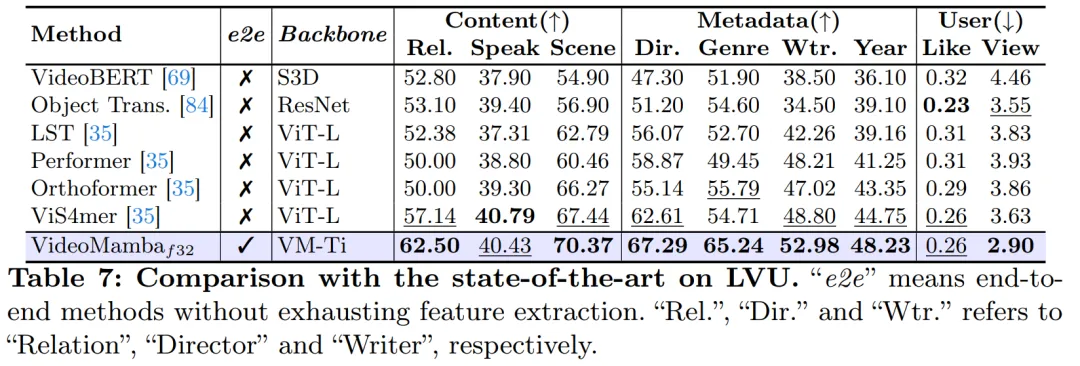
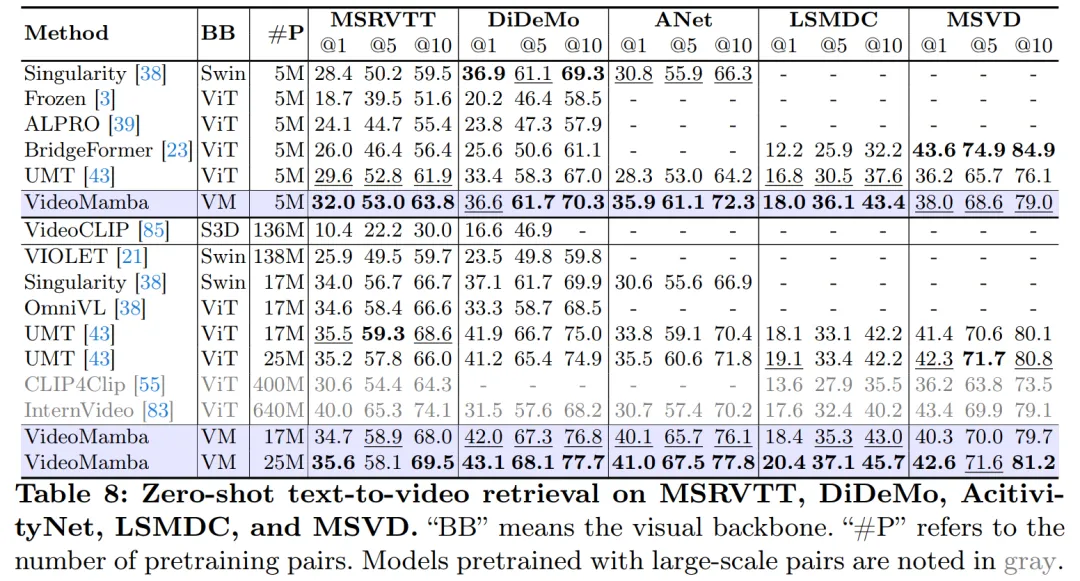
As shown in Table 8, under the same pre-training corpus and similar training strategy, VideoMamba It is better than ViT-based UMT in zero-sample video retrieval performance. This highlights Mamba's comparable efficiency and scalability compared to ViT in processing multi-modal video tasks. Notably, VideoMamba shows significant improvements on datasets with longer video lengths (e.g., ANet and DiDeMo) and more complex scenarios (e.g., LSMDC). This demonstrates Mamba's capabilities in challenging multimodal environments, even where cross-modal alignment is required.
For more research details, please refer to the original paper.
The above is the detailed content of In addition to CNN, Transformer, and Uniformer, we finally have more efficient video understanding technology. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1663
1663
 14
1420
52
1315
25
1266
29
1239
24
14
1420
52
1315
25
1266
29
1239
24

 Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
The top ten cryptocurrency exchanges in the world in 2025 include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, KuCoin, Bittrex and Poloniex, all of which are known for their high trading volume and security.
 How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
Bitcoin’s price ranges from $20,000 to $30,000. 1. Bitcoin’s price has fluctuated dramatically since 2009, reaching nearly $20,000 in 2017 and nearly $60,000 in 2021. 2. Prices are affected by factors such as market demand, supply, and macroeconomic environment. 3. Get real-time prices through exchanges, mobile apps and websites. 4. Bitcoin price is highly volatile, driven by market sentiment and external factors. 5. It has a certain relationship with traditional financial markets and is affected by global stock markets, the strength of the US dollar, etc. 6. The long-term trend is bullish, but risks need to be assessed with caution.
 Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
The top ten cryptocurrency trading platforms in the world include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, KuCoin and Poloniex, all of which provide a variety of trading methods and powerful security measures.
 What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
Currently ranked among the top ten virtual currency exchanges: 1. Binance, 2. OKX, 3. Gate.io, 4. Coin library, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9. Bitcoin, 10. bit stamp.
 What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
The top ten digital currency exchanges such as Binance, OKX, gate.io have improved their systems, efficient diversified transactions and strict security measures.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
Handling high DPI display in C can be achieved through the following steps: 1) Understand DPI and scaling, use the operating system API to obtain DPI information and adjust the graphics output; 2) Handle cross-platform compatibility, use cross-platform graphics libraries such as SDL or Qt; 3) Perform performance optimization, improve performance through cache, hardware acceleration, and dynamic adjustment of the details level; 4) Solve common problems, such as blurred text and interface elements are too small, and solve by correctly applying DPI scaling.
 Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
The built-in quantization tools on the exchange include: 1. Binance: Provides Binance Futures quantitative module, low handling fees, and supports AI-assisted transactions. 2. OKX (Ouyi): Supports multi-account management and intelligent order routing, and provides institutional-level risk control. The independent quantitative strategy platforms include: 3. 3Commas: drag-and-drop strategy generator, suitable for multi-platform hedging arbitrage. 4. Quadency: Professional-level algorithm strategy library, supporting customized risk thresholds. 5. Pionex: Built-in 16 preset strategy, low transaction fee. Vertical domain tools include: 6. Cryptohopper: cloud-based quantitative platform, supporting 150 technical indicators. 7. Bitsgap:
