
 Technology peripherals
AI
Complete the "Code Generation" task! Fudan et al. release StepCoder framework: Reinforcement learning from compiler feedback signals
Technology peripherals
AI
Complete the "Code Generation" task! Fudan et al. release StepCoder framework: Reinforcement learning from compiler feedback signals
Complete the "Code Generation" task! Fudan et al. release StepCoder framework: Reinforcement learning from compiler feedback signals

Advances in large language models (LLMs) have largely driven the field of code generation. In previous research, reinforcement learning (RL) and compiler feedback signals were combined to explore the output space of LLMs to optimize the quality of code generation.
But there are still two problems:
#1. Reinforcement learning exploration is difficult to directly adapt to "complex human needs". That is, LLMs are required to generate "long sequence code";
2. Since unit tests may not cover complex code, it is ineffective to use unexecuted code snippets to optimize LLMs.
To address these challenges, the researchers proposed a new reinforcement learning framework called StepCoder, which was jointly developed by experts from Fudan University, Huazhong University of Science and Technology, and Royal Institute of Technology. StepCoder contains two key components designed to improve the efficiency and quality of code generation.
1. CCCSAddresses exploration challenges by breaking long sequence code generation tasks into code completion sub-task courses;
2. FGOOptimizes the model by masking unexecuted code segments to provide fine-grained optimization.

Paper link: https://arxiv.org/pdf/2402.01391.pdf
Project Link: https://github.com/Ablustrund/APPS_Plus
The researchers also built the APPS data set for reinforcement learning training and manually verified it to ensure the correctness of the unit tests.
Experimental results show that the method improves the ability to explore the output space and outperforms state-of-the-art methods on corresponding benchmarks.
StepCoder
In the code generation process, ordinary reinforcement learning exploration (exploration) is difficult to handle "environments with sparse and delayed rewards" and "long sequences". Complex needs".
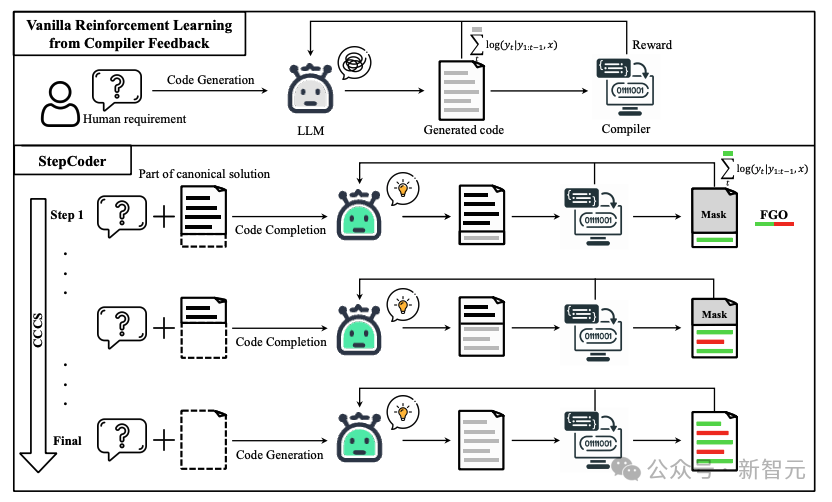
In the CCCS (Curriculum of Code Completion Subtasks) stage, researchers decompose complex exploration problems into a series of subtasks. Using a portion of the canonical solution as a prompt, LLM can start exploring from simple sequences.
The calculation of rewards is only related to executable code fragments, so it is inaccurate to use the entire code (red part in the figure) to optimize LLM (gray part in the figure).
In the FGO (Fine-Grained Optimization) stage, researchers mask the unexecuted tokens (red part) in the unit test and only use the executed tokens (green part) Computes a loss function, which can provide fine-grained optimization.
Preliminary knowledge
Assume that 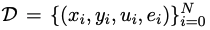 is a training data set used for code generation, where x, y, and u represent human needs (i.e., task description), standard solutions, and unit test samples respectively.
is a training data set used for code generation, where x, y, and u represent human needs (i.e., task description), standard solutions, and unit test samples respectively.
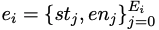 is a list of conditional statements obtained by automatically analyzing the abstract syntax tree of the standard solution yi, where st and en represent the starting position and ending position of the statement respectively.
is a list of conditional statements obtained by automatically analyzing the abstract syntax tree of the standard solution yi, where st and en represent the starting position and ending position of the statement respectively.
For human needs x, its standard solution y can be expressed as 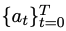 ; in the code generation stage, given human needs x, the final state is through the unit A collection of codes that test u.
; in the code generation stage, given human needs x, the final state is through the unit A collection of codes that test u.
Method details
StepCoder integrates two key components: CCCS and FGO, where the purpose of CCCS is to Courses in which code generation tasks are decomposed into code completion subtasks can alleviate exploration challenges in RL; FGO is designed specifically for code generation tasks and provides fine-grained optimization by only calculating the loss of executed code fragments.
CCCS
In the code generation process, to solve complex human needs, policy models usually need to adopt relatively complex Long action sequences. At the same time, the compiler's feedback is delayed and sparse, that is, the policy model only receives rewards after the entire code has been generated. In this case, exploration is very difficult.
The core of the method is to decompose such a long list of exploration problems into a series of short, easy-to-explore subtasks. The researchers reduced code generation into code completion subtasks, where Subtasks are automatically constructed from typical solutions in the training dataset.
For human needs x, in the early training stage of CCCS, the starting point s* for exploration is a state near the final state.
Specifically, the researchers provide the human need x and the first half of the standard solution 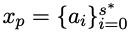 , and train a policy model to predict xp) complete the code.
, and train a policy model to predict xp) complete the code.
Assuming that y^ is the combined sequence of xp and the output trajectory τ, that is, yˆ=(xp,τ), the reward model is provided based on the correctness of the code fragment τ with y^ as input Reward r.

The researchers used the proximal policy optimization (PPO) algorithm to optimize the policy model πθ by utilizing the reward r and trajectory τ.
During the optimization phase, the canonical solution code segment xp used to provide hints will be masked so that it will not have an impact on the gradient of the policy model πθ update.
CCCS optimizes the policy model πθ by maximizing the opposition function, where π^ref is the reference model in PPO and is initialized by the SFT model.
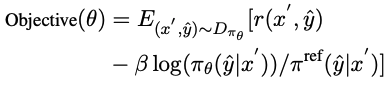
As training progresses, the starting point s* of exploration will gradually move toward the starting point of the standard solution. Specifically, a threshold ρ is set for each training sample. When the cumulative accuracy rate of the code segments generated by πθ is greater than ρ, the starting point is moved to beginning.
In the later stages of training, the exploration process of this method is equivalent to that of original reinforcement learning, that is, s*=0, and the policy model only generates code with human needs as input.
Sample the initial recognition point s* at the starting position of the conditional statement to complete the remaining unwritten code segment.
Specifically, the more conditional statements, the more independent paths the program has, and the higher the logic complexity. The complexity requires more frequent sampling to improve the training quality, and Programs with fewer conditional statements do not need to sample as frequently.
This sampling method can evenly extract representative code structures while taking into account both complex and simple semantic structures in the training data set.
To speed up the training phase, the researchers set the number of courses for the i-th sample to 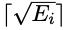 , where Ei is the number of its conditional statements. The training course span of the i-th sample is
, where Ei is the number of its conditional statements. The training course span of the i-th sample is 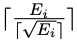 , not 1.
, not 1.
The main points of CCCS can be summarized as follows:
1. It is easy to start exploring from a state close to the goal (i.e. the final state);
2. Exploration from a state further away from the goal is challenging, but exploration becomes easier if you can take advantage of states that have already learned how to reach the goal.
FGO
The relationship between rewards and actions in code generation is different from other reinforcement learning tasks (such as Atari ), in code generation it is possible to exclude a set of actions that are not relevant for calculating the reward in the generated code.
Specifically, for unit testing, the compiler’s feedback is only related to the executed code fragment. However, in the ordinary RL optimization goal, all actions on the trajectory will participate in the gradient calculation. , and the gradient calculation is imprecise.
In order to improve the optimization accuracy, the researchers shielded the unexecuted actions (i.e. tokens) in the unit test and the loss of the strategy model.

Experimental part
APPS data set
Reinforcement learning requires a large amount of high-quality training data. During the investigation, the researchers found that among the currently available open source data sets, only APPS meets this requirement.
But there are some incorrect instances in APPS, such as missing input, output or standard solution, where the standard solution may not compile or execute, or there may be differences in execution output.
To complete the APPS dataset, the researchers filtered out instances with missing inputs, outputs, or standard solutions, and then standardized the formats of inputs and outputs to facilitate the execution of unit tests. and comparison; each instance was then unit tested and manually analyzed, eliminating instances with incomplete or irrelevant code, syntax errors, API misuse, or missing library dependencies.
For differences in output, researchers manually review the problem description, correct the expected output, or eliminate the instance.
Finally, the APPS data set was constructed, containing 7456 instances. Each instance includes programming problem description, standard solution, function name, unit test (i.e. input and output) and Startup code (i.e. the beginning of a standard solution).

Experimental results
To evaluate the performance of other LLMs and StepCoder in code generation, researchers Experiments were conducted on the APPS dataset.
The results show that the RL-based model outperforms other language models, including the base model and the SFT model.
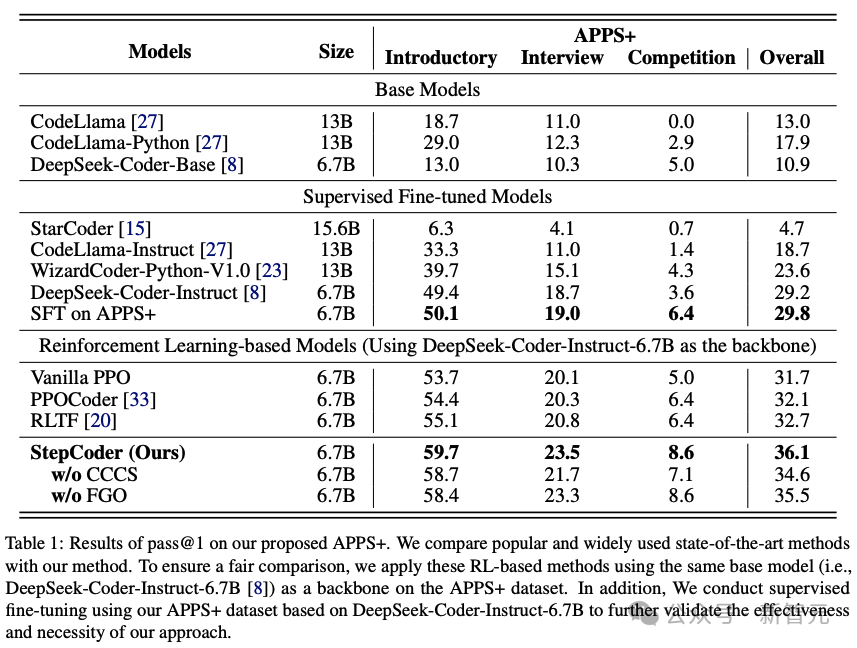
#The researchers have reason to infer that reinforcement learning can further improve performance by more efficiently browsing the model's output space, guided by compiler feedback. The quality of code generation.
Furthermore, StepCoder surpassed all baseline models, including other RL-based methods, and achieved the highest score.
Specifically, this method achieved 59.7%, High scores of 23.5% and 8.6%.
Compared with other reinforcement learning-based methods, this method performs well in exploring the output space by simplifying complex code generation tasks into code completion subtasks, and the FGO process performs well in Played a key role in accurately optimizing the strategy model.
It can also be found that on the APPS data set based on the same architecture network, the performance of StepCoder is better than the supervised LLM for fine-tuning; compared with the backbone network, the latter has almost no Improve the pass rate of generated code, which also directly shows that using compiler feedback to optimize the model can improve the quality of generated code more than the next token prediction in code generation.
The above is the detailed content of Complete the "Code Generation" task! Fudan et al. release StepCoder framework: Reinforcement learning from compiler feedback signals. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1663
1663
 14
1420
52
1313
25
1266
29
1239
24
14
1420
52
1313
25
1266
29
1239
24

 Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
The top ten cryptocurrency exchanges in the world in 2025 include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, KuCoin, Bittrex and Poloniex, all of which are known for their high trading volume and security.
 How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
Bitcoin’s price ranges from $20,000 to $30,000. 1. Bitcoin’s price has fluctuated dramatically since 2009, reaching nearly $20,000 in 2017 and nearly $60,000 in 2021. 2. Prices are affected by factors such as market demand, supply, and macroeconomic environment. 3. Get real-time prices through exchanges, mobile apps and websites. 4. Bitcoin price is highly volatile, driven by market sentiment and external factors. 5. It has a certain relationship with traditional financial markets and is affected by global stock markets, the strength of the US dollar, etc. 6. The long-term trend is bullish, but risks need to be assessed with caution.
 What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
Currently ranked among the top ten virtual currency exchanges: 1. Binance, 2. OKX, 3. Gate.io, 4. Coin library, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9. Bitcoin, 10. bit stamp.
 Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
The top ten cryptocurrency trading platforms in the world include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, KuCoin and Poloniex, all of which provide a variety of trading methods and powerful security measures.
 Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0 redefines crypto asset management through innovative architecture and performance breakthroughs. 1) It solves three major pain points: asset silos, income decay and paradox of security and convenience. 2) Through intelligent asset hubs, dynamic risk management and return enhancement engines, cross-chain transfer speed, average yield rate and security incident response speed are improved. 3) Provide users with asset visualization, policy automation and governance integration, realizing user value reconstruction. 4) Through ecological collaboration and compliance innovation, the overall effectiveness of the platform has been enhanced. 5) In the future, smart contract insurance pools, forecast market integration and AI-driven asset allocation will be launched to continue to lead the development of the industry.
 What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
The top ten digital currency exchanges such as Binance, OKX, gate.io have improved their systems, efficient diversified transactions and strict security measures.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
Handling high DPI display in C can be achieved through the following steps: 1) Understand DPI and scaling, use the operating system API to obtain DPI information and adjust the graphics output; 2) Handle cross-platform compatibility, use cross-platform graphics libraries such as SDL or Qt; 3) Perform performance optimization, improve performance through cache, hardware acceleration, and dynamic adjustment of the details level; 4) Solve common problems, such as blurred text and interface elements are too small, and solve by correctly applying DPI scaling.
