
 Technology peripherals
AI
Tongyi Qianwen is open source again, Qwen1.5 brings six volume models, and its performance exceeds GPT3.5
Technology peripherals
AI
Tongyi Qianwen is open source again, Qwen1.5 brings six volume models, and its performance exceeds GPT3.5
Tongyi Qianwen is open source again, Qwen1.5 brings six volume models, and its performance exceeds GPT3.5

Before the Spring Festival, version 1.5 of Tongyi Qianwen Model (Qwen) is online. This morning, news of the new version sparked concern in the AI community.
The new version of the large model includes six model sizes: 0.5B, 1.8B, 4B, 7B, 14B and 72B. Among them, the performance of the strongest version surpasses GPT 3.5 and Mistral-Medium. This version includes Base model and Chat model, and provides multi-language support.
The Alibaba Tongyi Qianwen team stated that the relevant technology has also been launched on the Tongyi Qianwen official website and Tongyi Qianwen App.
In addition, today’s release of Qwen 1.5 also has the following highlights:
- Supports 32K context length;
- Opened the checkpoint of the Base Chat model;
- Can be run locally with Transformers;
- Released at the same time GPTQ Int-4/Int8, AWQ and GGUF weights.
By using more advanced large-scale models as judges, the Tongyi Qianwen team performed on Qwen1.5 on two widely used benchmarks, MT-Bench and Alpaca-Eval. made a preliminary assessment. The evaluation results are as follows:
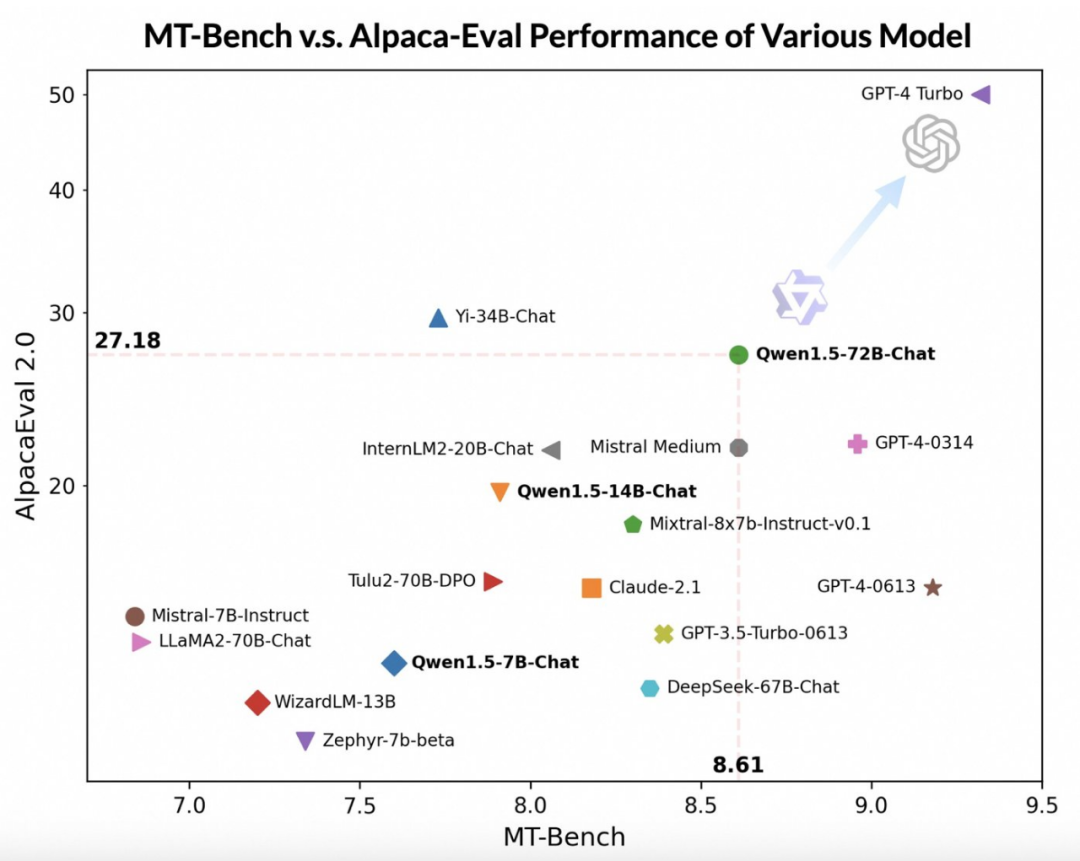
##Although the Qwen1.5-72B-Chat model lags behind GPT-4-Turbo, it performs better in MT-Bench and In tests on Alpaca-Eval v2, it showed impressive performance. In fact, Qwen1.5-72B-Chat surpasses Claude-2.1, GPT-3.5-Turbo-0613, Mixtral-8x7b-instruct and TULU 2 DPO 70B in performance, and is comparable to the Mistral Medium model that has attracted much attention recently. Comparable. This shows that the Qwen1.5-72B-Chat model has considerable strength in natural language processing.
Tongyi Qianwen team pointed out that although the score of the large model may be related to the length of the answer, human observations show that Qwen1.5 does not suffer from excessively long answers. Impact rating. According to AlpacaEval 2.0 data, the average length of Qwen1.5-Chat is 1618, which is the same length as GPT-4 and shorter than GPT-4-Turbo.
The developers of Tongyi Qianwen said that in recent months, they have been committed to building an excellent model and continuously improving the developer experience.

Compared with previous versions, this update focuses on improving the alignment of the Chat model with human preferences, and significantly enhances the model's multi-language processing power. In terms of sequence length, all scale models have implemented context length range support of 32768 tokens. At the same time, the quality of the pre-trained Base model has also been keyly optimized, which is expected to provide people with a better experience during the fine-tuning process.
Basic capabilities
Regarding the evaluation of the basic capabilities of the model, the Tongyi Qianwen team conducted MMLU (5-shot), C-Eval, Qwen1.5 was evaluated on benchmark data sets such as Humaneval, GS8K, and BBH.
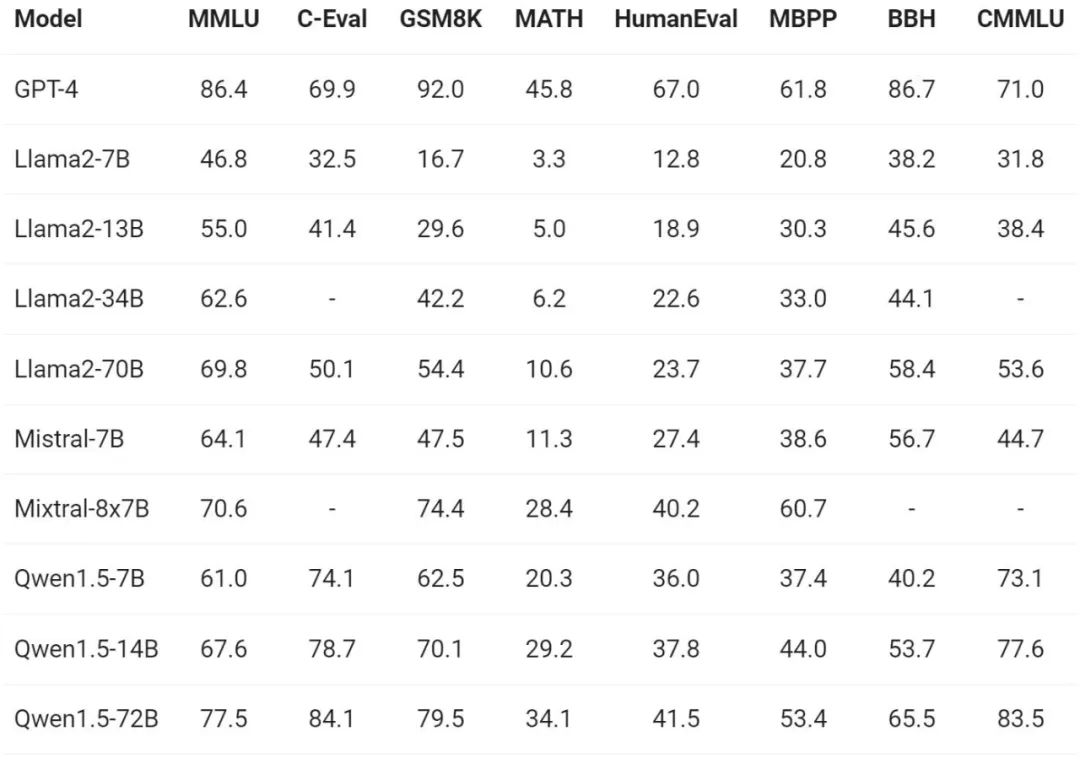
Under different model sizes, Qwen1.5 showed strong performance in the evaluation benchmarks, and the 72B version performed well in all benchmarks. Beyond Llama2-70B, it demonstrated its capabilities in language understanding, reasoning, and mathematics.
In recent times, the construction of small models has been one of the hot spots in the industry. The Tongyi Qianwen team has compared the Qwen1.5 model with model parameters less than 7 billion with important small models in the community. Comparison:
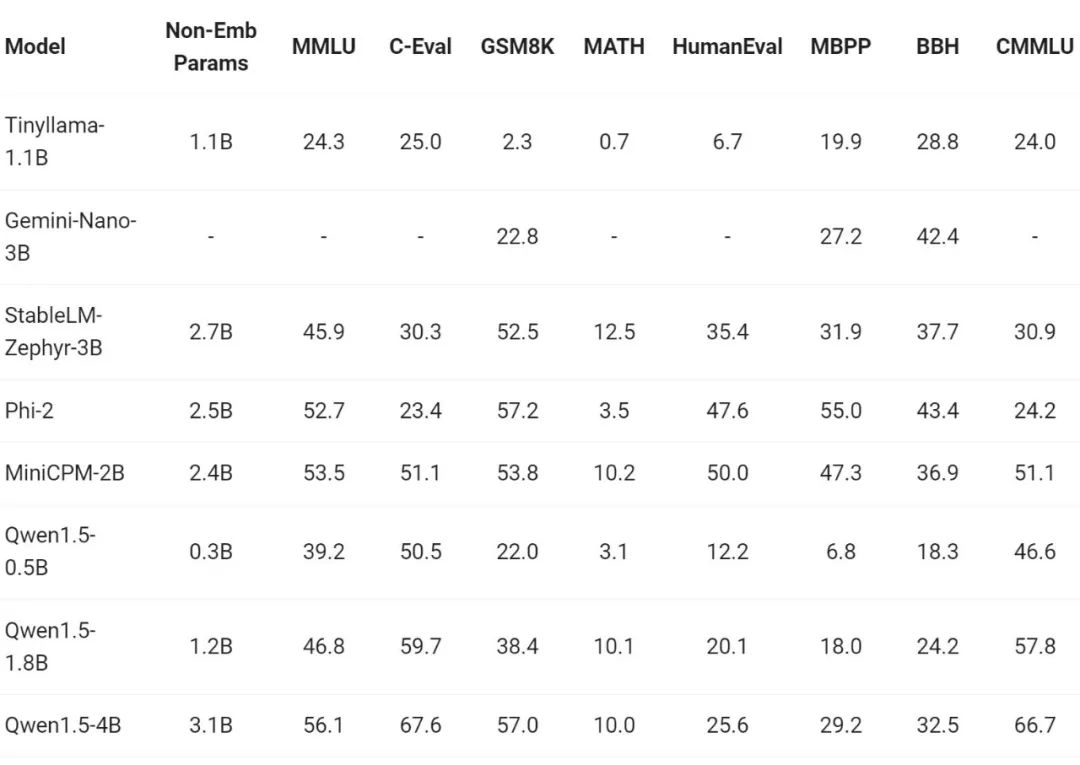
Qwen1.5 is highly competitive with industry-leading small models in the parameter size range below 7 billion force.
Multi-language capabilities
The Tongyi Qianwen team evaluated the Base model on 12 different languages from Europe, East Asia, and Southeast Asia multilingual capabilities. From the public data set of the open source community, Alibaba researchers constructed the evaluation set shown in the following table, covering four different dimensions: examination, comprehension, translation, and mathematics. The table below provides details for each test set, including its evaluation configuration, evaluation metrics, and the specific languages involved.
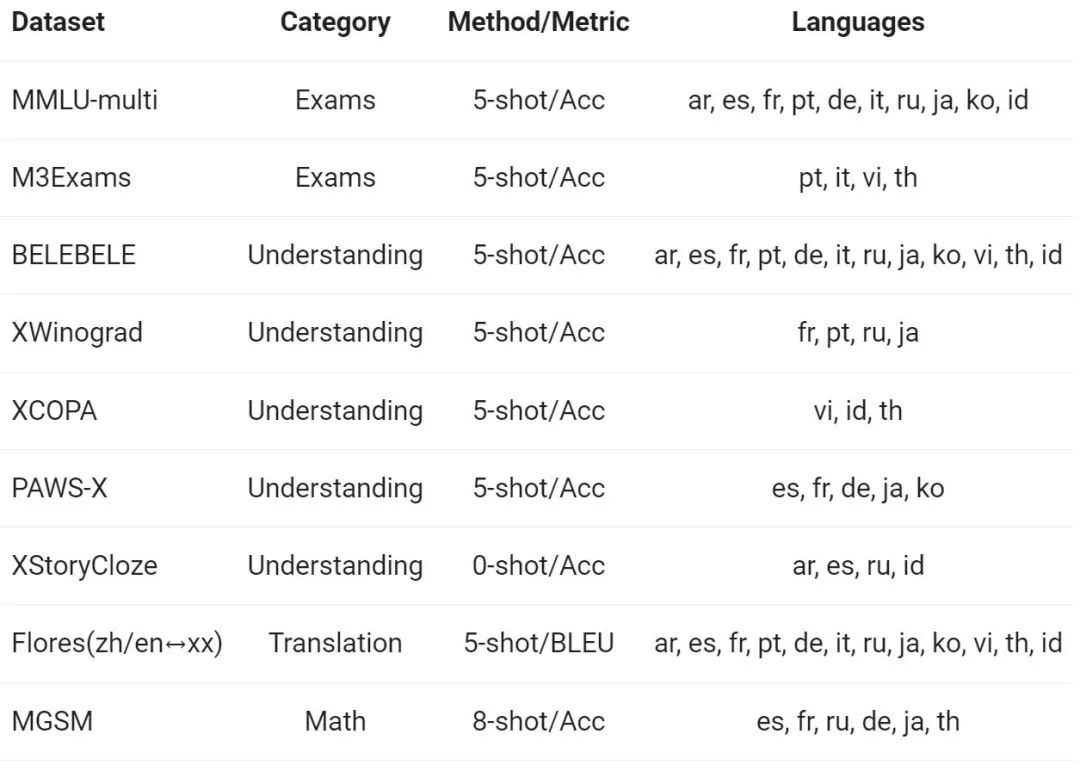
The detailed results are as follows:
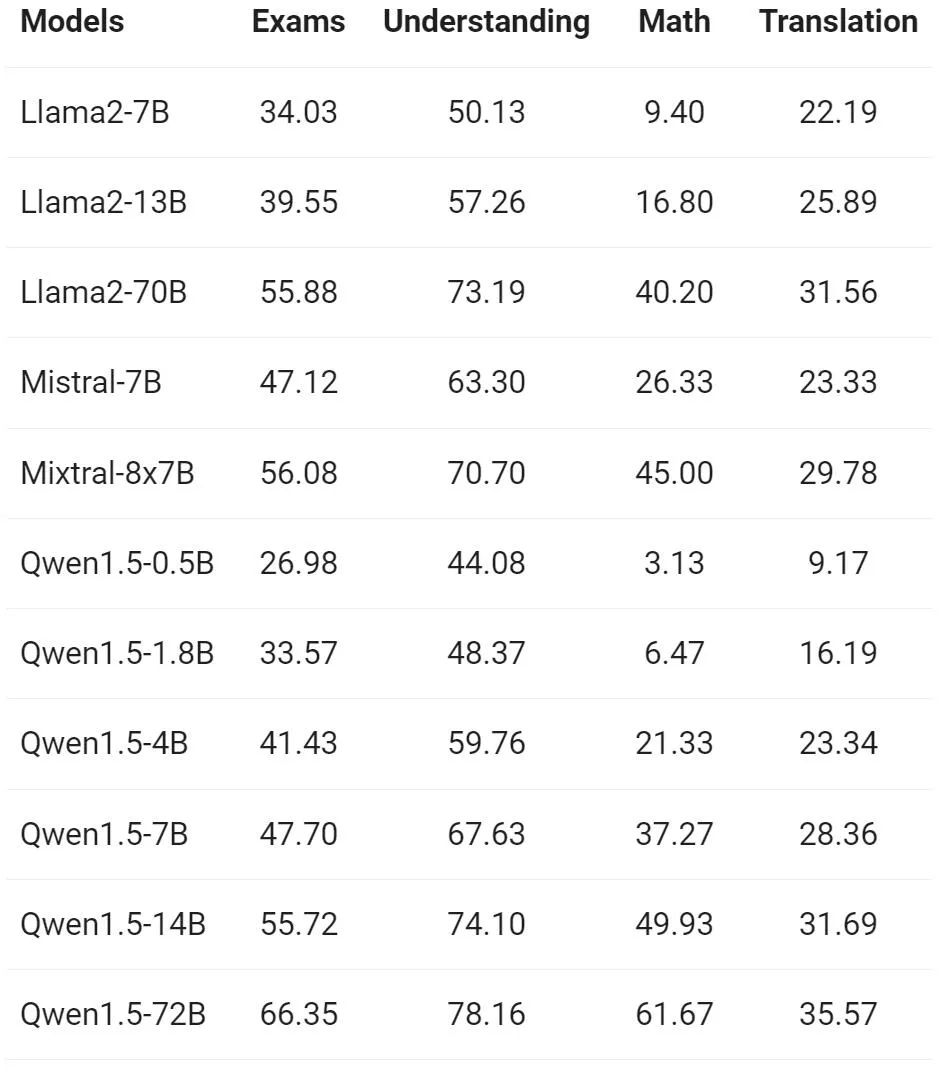
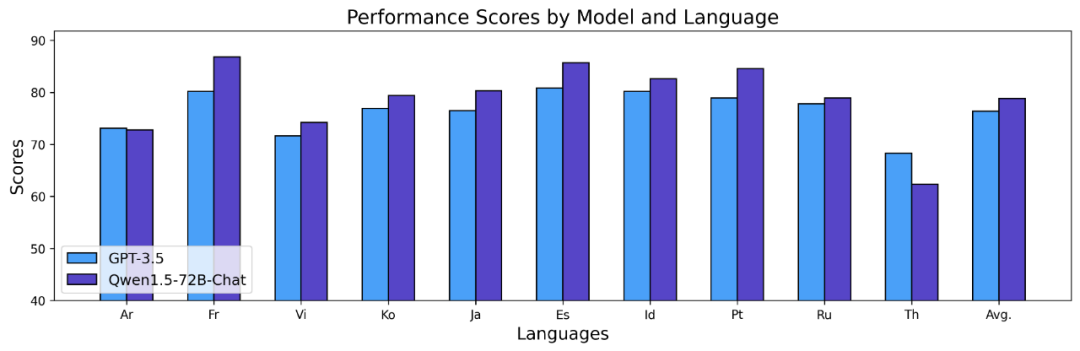
The above results show that the Qwen1.5 Base model performs well in multilingual capabilities in 12 different languages, and shows good performance in the evaluation of various dimensions such as subject knowledge, language understanding, translation, and mathematics. result. Furthermore, with regard to the multilingual capabilities of the Chat model, the following results can be observed:
Long sequence
As the demand for long sequence understanding continues to increase, Alibaba has improved the corresponding capabilities of the Qianwen model in the new version. The full series of Qwen1.5 models support the context of 32K tokens. The Tongyi Qianwen team evaluated the performance of the Qwen1.5 model on the L-Eval benchmark, which measures a model's ability to generate responses based on long context. The results are as follows:
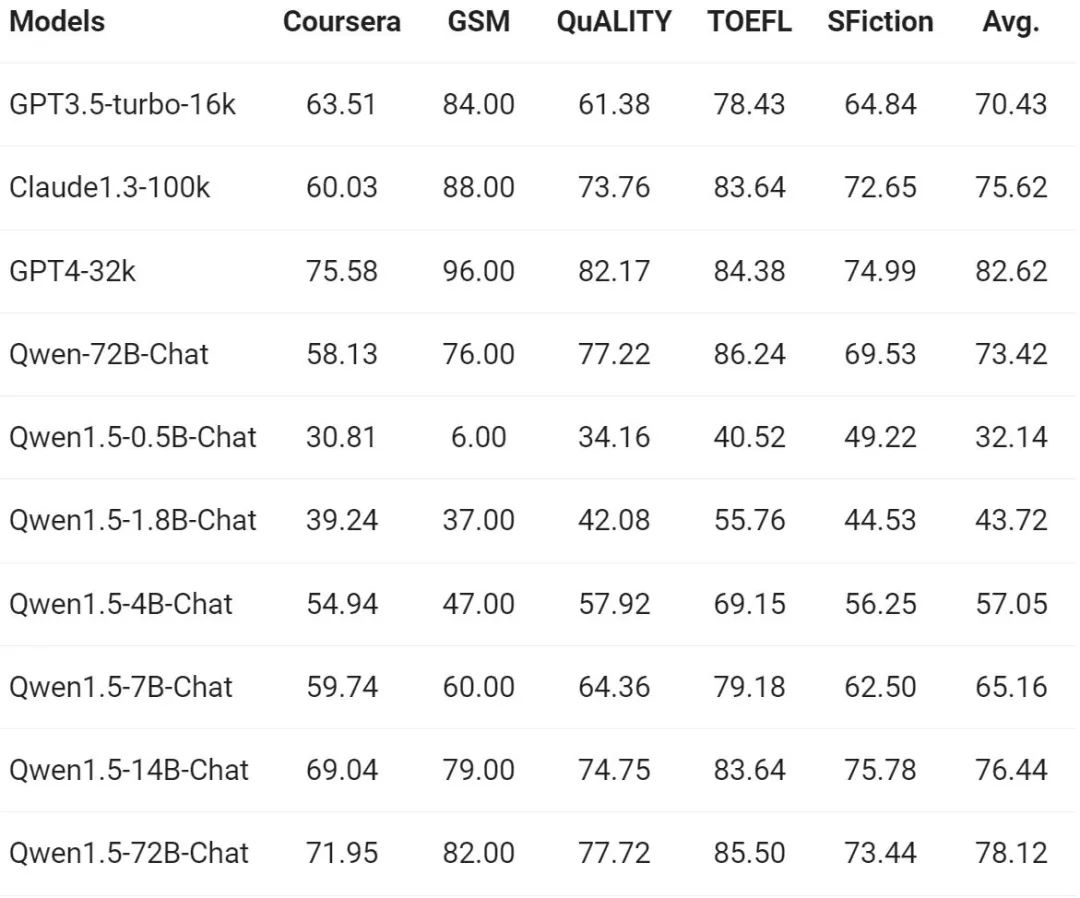
From the results, even a small-scale model like Qwen1.5-7B-Chat can show the same performance as GPT -3.5 Comparable performance, while the largest model, Qwen1.5-72B-Chat, is only slightly behind GPT4-32k.
It is worth mentioning that the above results only show the effect of Qwen 1.5 under the length of 32K tokens, and it does not mean that the model can only support a maximum length of 32K. Developers can try to modify max_position_embedding in config.json to a larger value to observe whether the model can achieve satisfactory results in longer context understanding scenarios.
Linking external systems
Nowadays, one of the charms of general language models lies in their potential ability to interface with external systems. As a rapidly emerging task in the community, RAG effectively addresses some of the typical challenges faced by large language models, such as hallucinations and the inability to obtain real-time updates or private data. In addition, language models demonstrate powerful capabilities in using APIs and writing code based on instructions and examples. Large models can use code interpreters or act as AI agents to achieve broader value.
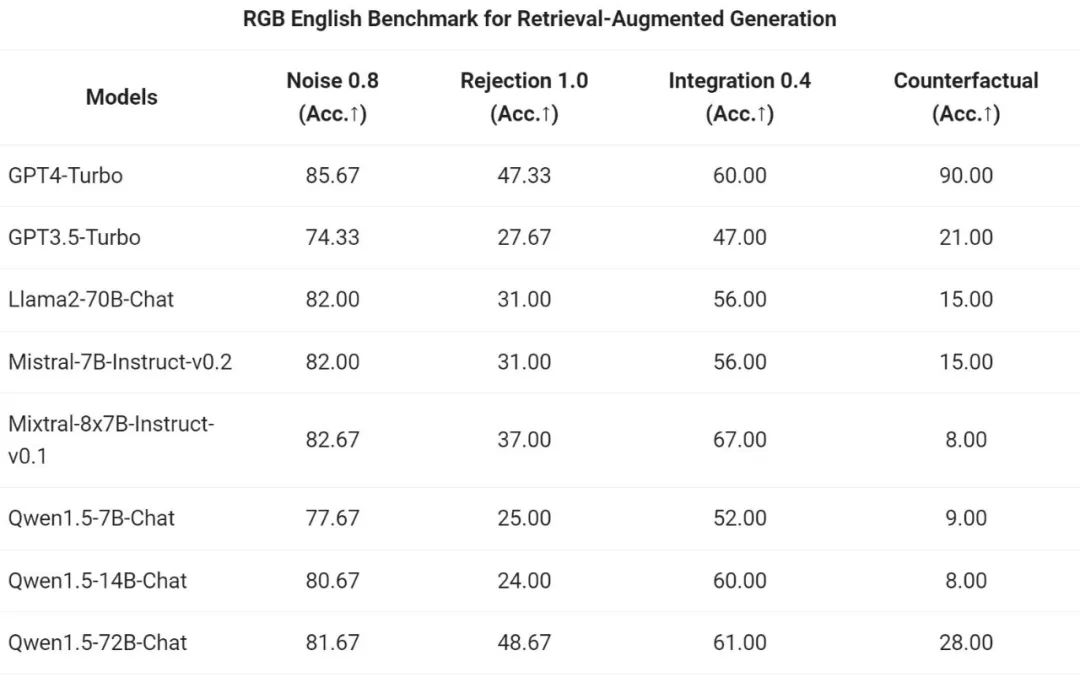
The Tongyi Qianwen team evaluated the end-to-end effect of the Qwen1.5 series Chat model on the RAG task. The evaluation is based on the RGB test set, which is a set used for Chinese and English RAG evaluation:
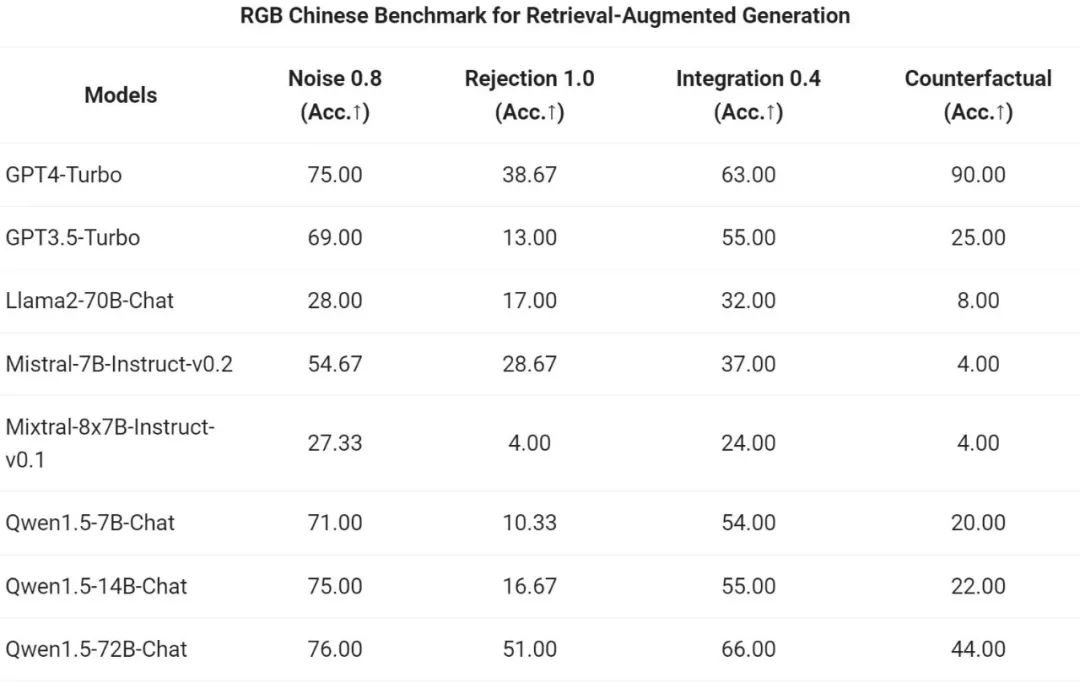
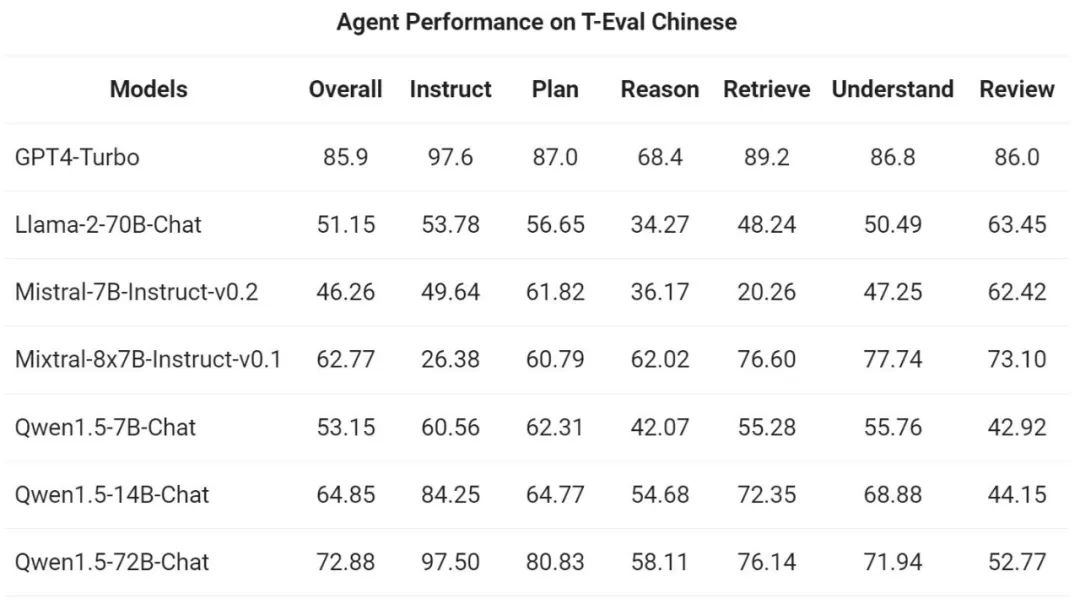
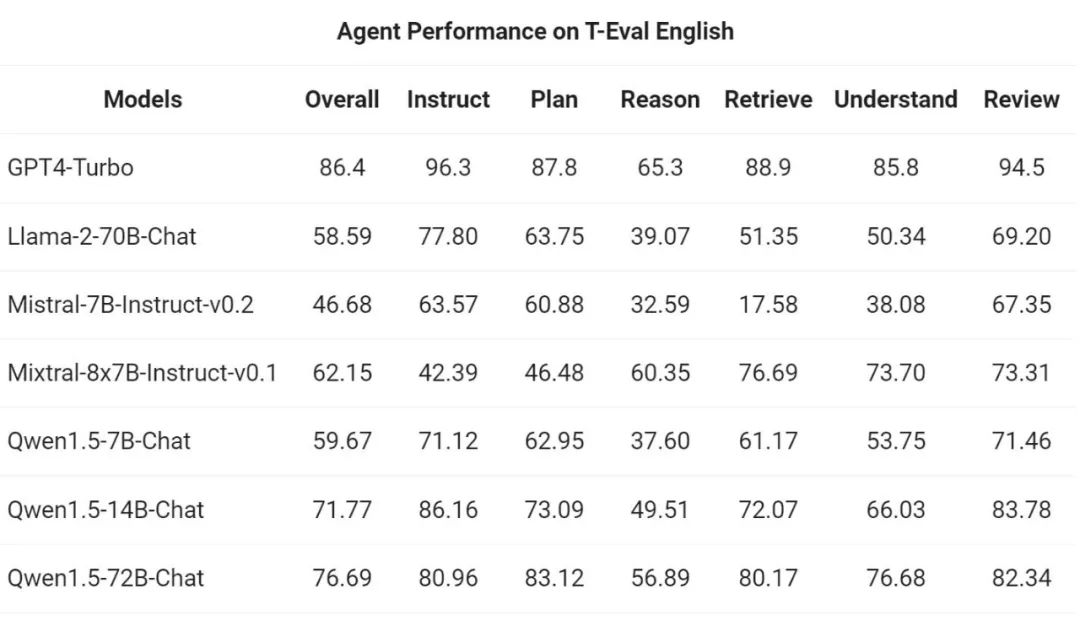
Then, pass The Yiqianwen team evaluated Qwen1.5's ability to run as a general-purpose agent in the T-Eval benchmark. All Qwen1.5 models are not optimized specifically for the benchmark:
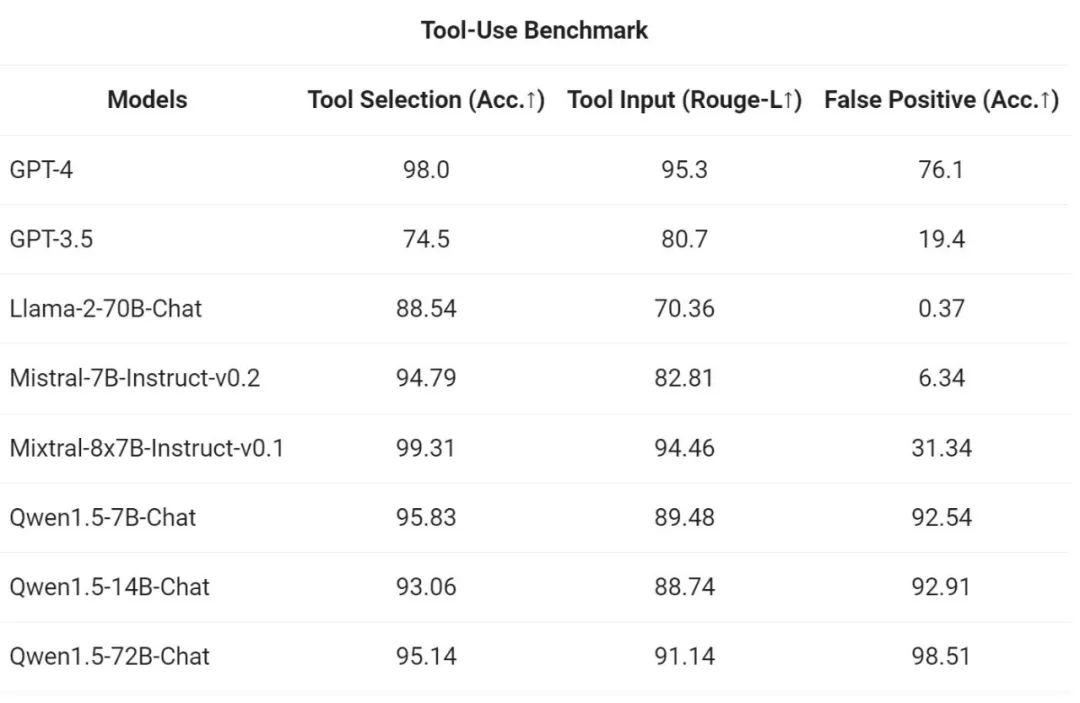
##In order to test the tool calling ability, Ali Use your own open source evaluation benchmark to test the model's ability to correctly select and call tools. The results are as follows:
Finally, since the Python code interpreter has become an advanced LLM is an increasingly powerful tool. The Tongyi Qianwen team also evaluated the new model's ability to utilize this tool based on previous open source evaluation benchmarks:
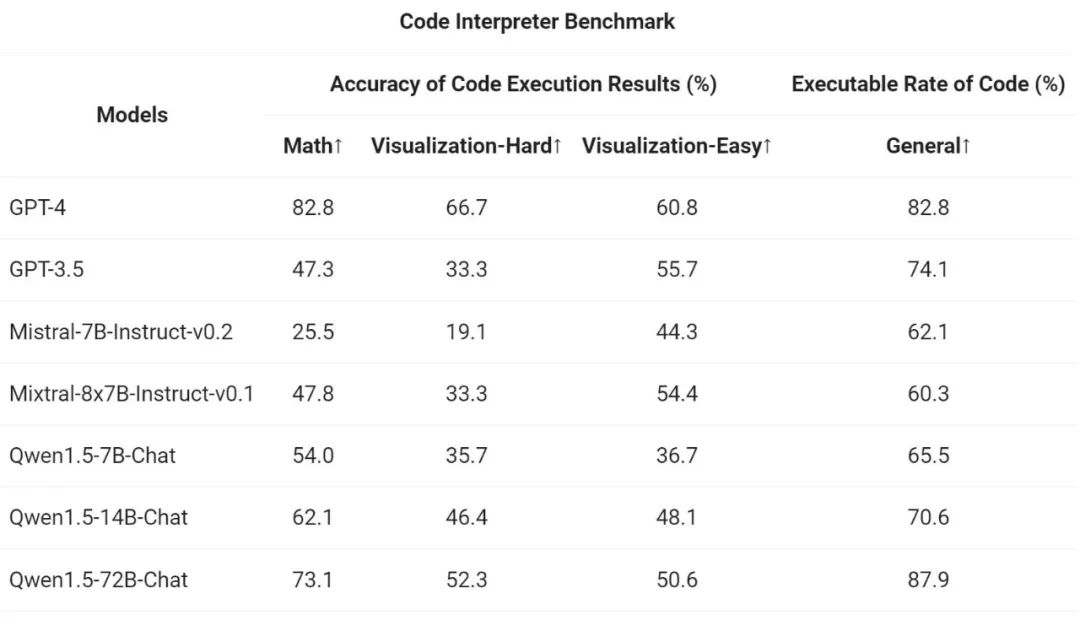
The results show that the larger Qwen1.5-Chat model generally outperforms the smaller model, with Qwen1.5-72B-Chat approaching GPT-4 tool performance. However, in code interpreter tasks such as mathematical problem solving and visualization, even the largest Qwen1.5-72B-Chat model lags significantly behind GPT-4 in terms of coding ability. Ali stated that it will improve the coding capabilities of all Qwen models during the pre-training and alignment process in future versions.
Qwen1.5 is integrated with the HuggingFace transformers code base. Starting from version 4.37.0, developers can directly use the transformers library native code without loading any custom code (specifying the trust_remote_code option) to use Qwen1.5.
In the open source ecosystem, Alibaba has cooperated with vLLM, SGLang (for deployment), AutoAWQ, AutoGPTQ (for quantification), Axolotl, LLaMA-Factory (for fine-tuning) and llama.cpp (for local LLM inference) and other frameworks, all of which now support Qwen1.5. The Qwen1.5 series is also currently available on platforms such as Ollama and LMStudio.
The above is the detailed content of Tongyi Qianwen is open source again, Qwen1.5 brings six volume models, and its performance exceeds GPT3.5. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
 okx online okx exchange official website online
Apr 22, 2025 am 06:45 AM
okx online okx exchange official website online
Apr 22, 2025 am 06:45 AM
The detailed introduction of OKX Exchange is as follows: 1) Development history: Founded in 2017 and renamed OKX in 2022; 2) Headquartered in Seychelles; 3) Business scope covers a variety of trading products and supports more than 350 cryptocurrencies; 4) Users are spread across more than 200 countries, with tens of millions of users; 5) Multiple security measures are adopted to protect user assets; 6) Transaction fees are based on the market maker model, and the fee rate decreases with the increase in trading volume; 7) It has won many honors, such as "Cryptocurrency Exchange of the Year".
 A list of special services for major virtual currency trading platforms
Apr 22, 2025 am 08:09 AM
A list of special services for major virtual currency trading platforms
Apr 22, 2025 am 08:09 AM
Institutional investors should choose compliant platforms such as Coinbase Pro and Genesis Trading, focusing on cold storage ratios and audit transparency; retail investors should choose large platforms such as Binance and Huobi, focusing on user experience and security; users in compliance-sensitive areas can conduct fiat currency trading through Circle Trade and Huobi Global, and mainland Chinese users need to go through compliant over-the-counter channels.
 Top 10 latest releases of virtual currency trading platforms for bulk transactions
Apr 22, 2025 am 08:18 AM
Top 10 latest releases of virtual currency trading platforms for bulk transactions
Apr 22, 2025 am 08:18 AM
The following factors should be considered when choosing a bulk trading platform: 1. Liquidity: Priority is given to platforms with an average daily trading volume of more than US$5 billion. 2. Compliance: Check whether the platform holds licenses such as FinCEN in the United States, MiCA in the European Union. 3. Security: Cold wallet storage ratio and insurance mechanism are key indicators. 4. Service capability: Whether to provide exclusive account managers and customized transaction tools.
 A list of top ten virtual currency trading platforms that support multiple currencies
Apr 22, 2025 am 08:15 AM
A list of top ten virtual currency trading platforms that support multiple currencies
Apr 22, 2025 am 08:15 AM
Priority is given to compliant platforms such as OKX and Coinbase, enabling multi-factor verification, and asset self-custody can reduce dependencies: 1. Select an exchange with a regulated license; 2. Turn on the whitelist of 2FA and withdrawals; 3. Use a hardware wallet or a platform that supports self-custody.
 Recommended top 10 for easy access to digital currency trading apps (latest ranking in 25)
Apr 22, 2025 am 07:45 AM
Recommended top 10 for easy access to digital currency trading apps (latest ranking in 25)
Apr 22, 2025 am 07:45 AM
The core advantage of gate.io (global version) is that the interface is minimalist, supports Chinese, and the fiat currency trading process is intuitive; Binance (simplified version) has the highest global trading volume, and the simple version model only retains spot trading; OKX (Hong Kong version) has the simple version of the interface is simple, supports Cantonese/Mandarin, and has a low threshold for derivative trading; Huobi Global Station (Hong Kong version) has the core advantage of being an old exchange, launches a meta-universe trading terminal; KuCoin (Chinese Community Edition) has the core advantage of supporting 800 currencies, and the interface adopts WeChat interaction; Kraken (Hong Kong version) has the core advantage of being an old American exchange, holding a Hong Kong SVF license, and the interface is simple; HashKey Exchange (Hong Kong licensed) has the core advantage of being a well-known licensed exchange in Hong Kong, supporting France
 Tips and recommendations for the top ten market websites in the currency circle 2025
Apr 22, 2025 am 08:03 AM
Tips and recommendations for the top ten market websites in the currency circle 2025
Apr 22, 2025 am 08:03 AM
Domestic user adaptation solutions include compliance channels and localization tools. 1. Compliance channels: Franchise currency exchange through OTC platforms such as Circle Trade, domestically, they need to go through Hong Kong or overseas platforms. 2. Localization tools: Use the currency circle network to obtain Chinese information, and Huobi Global Station provides a meta-universe trading terminal.
 Summary of the top ten Apple version download portals for digital currency exchange apps
Apr 22, 2025 am 09:27 AM
Summary of the top ten Apple version download portals for digital currency exchange apps
Apr 22, 2025 am 09:27 AM
Provides a variety of complex trading tools and market analysis. It covers more than 100 countries, has an average daily derivative trading volume of over US$30 billion, supports more than 300 trading pairs and 200 times leverage, has strong technical strength, a huge global user base, provides professional trading platforms, secure storage solutions and rich trading pairs.
