
 Technology peripherals
AI
The fusion of multiple heterogeneous large models brings amazing results
Technology peripherals
AI
The fusion of multiple heterogeneous large models brings amazing results
The fusion of multiple heterogeneous large models brings amazing results

With the success of large language models such as LLaMA and Mistral, many companies have begun to create their own large language models. However, training a new model from scratch is expensive and may have redundant capabilities.
Recently, researchers from Sun Yat-sen University and Tencent AI Lab proposed FuseLLM, which is used to "fuse multiple heterogeneous large models."
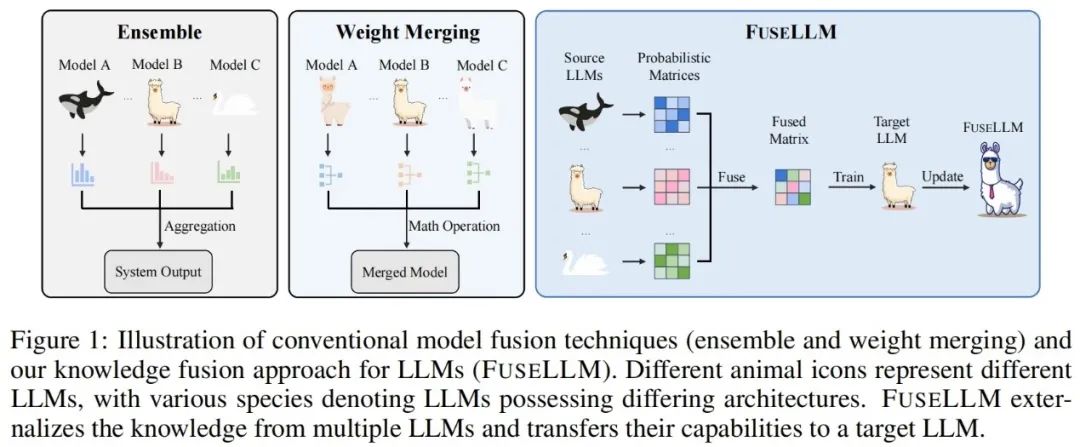
Different from traditional model integration and weight merging methods, FuseLLM provides a new way to fuse the knowledge of multiple heterogeneous large language models. Instead of deploying multiple large language models at the same time or requiring the merging of model results, FuseLLM uses a lightweight continuous training method to transfer the knowledge and capabilities of individual models into a fused large language model. What is unique about this approach is its ability to use multiple heterogeneous large language models at inference time and externalize their knowledge into a fused model. In this way, FuseLLM effectively improves the performance and efficiency of the model.
The paper has just been published on arXiv and has attracted a lot of attention and forwarding from netizens.

Someone thought it would be interesting to train a model on another language and I’ve been thinking about it.
This paper has been accepted by ICLR 2024.

- ##Paper title: Knowledge Fusion of Large Language Models
- Paper address: https://arxiv.org/abs/2401.10491
- Paper warehouse: https: //github.com/fanqiwan/FuseLLM
The key to FuseLLM The purpose is to explore the fusion of large language models from the perspective of probability distribution representation. For the same input text, the author believes that the representations generated by different large language models can reflect their intrinsic knowledge in understanding these texts. Therefore, FuseLLM first uses multiple source large language models to generate representations, externalizes their collective knowledge and respective advantages, then integrates the generated multiple representations to complement each other, and finally migrates to the target large language model through lightweight continuous training. . The figure below shows an overview of the FuseLLM approach.
In order to combine the collective knowledge of multiple large language models while maintaining their respective strengths, strategies for fused model-generated representations need to be carefully designed. Specifically, FuseLLM evaluates how well different large language models understand this text by calculating the cross-entropy between the generated representation and the label text, and then introduces two fusion functions based on cross-entropy:
- MinCE: Input multiple large models to generate representations for the current text, and output the representation with the smallest cross entropy;
- AvgCE: Input multiple large models to generate the current text The generated representation outputs a weighted average representation based on the weight obtained by cross entropy;
Experimental results
In the experimental part, the author considers a general but challenging large language model fusion scenario, where the source model is Have minor commonalities in structure or capabilities. Specifically, it conducted experiments on a 7B scale and selected three representative open source models: Llama-2, OpenLLaMA, and MPT as large models to be fused.
The author evaluated FuseLLM in scenarios such as general reasoning, common sense reasoning, code generation, text generation, and instruction following, and found that it achieved significant performance improvements compared to all source models and continued training baseline models. General Reasoning & Common Sense Reasoning ## On the Big-Bench Hard Benchmark that tests general reasoning capabilities, Llama-2 CLM after continuous training achieved an average improvement of 1.86% on 27 tasks compared to Llama-2, while FuseLLM achieved an average improvement of 1.86% compared to Llama-2. An improvement of 5.16% was achieved, which is significantly better than Llama-2 CLM, indicating that FuseLLM can combine the advantages of multiple large language models to achieve performance improvements. On the Common Sense Benchmark, which tests common sense reasoning ability, FuseLLM surpassed all source models and baseline models, achieving the best performance on all tasks. Code Generation & Text Generation On multiple text generation benchmarks measuring knowledge question answering (TrivialQA), reading comprehension (DROP), content analysis (LAMBADA), machine translation (IWSLT2017) and theorem application (SciBench) ,FuseLLM also outperforms all source models in all tasks,and outperforms Llama-2 CLM in 80% of tasks.
directive follows FuseLLM vs. Knowledge Distillation & Model Integration & Weight Merging
Finally, although the community has been paying attention to the fusion of large models, current practices are mostly based on weight merging and cannot be extended to model fusion scenarios of different structures and sizes. Although FuseLLM is only a preliminary research on heterogeneous model fusion, considering that there are currently a large number of language, visual, audio and multi-modal large models of different structures and sizes in the technical community, what will the fusion of these heterogeneous models burst out in the future? Astonishing performance? let us wait and see! 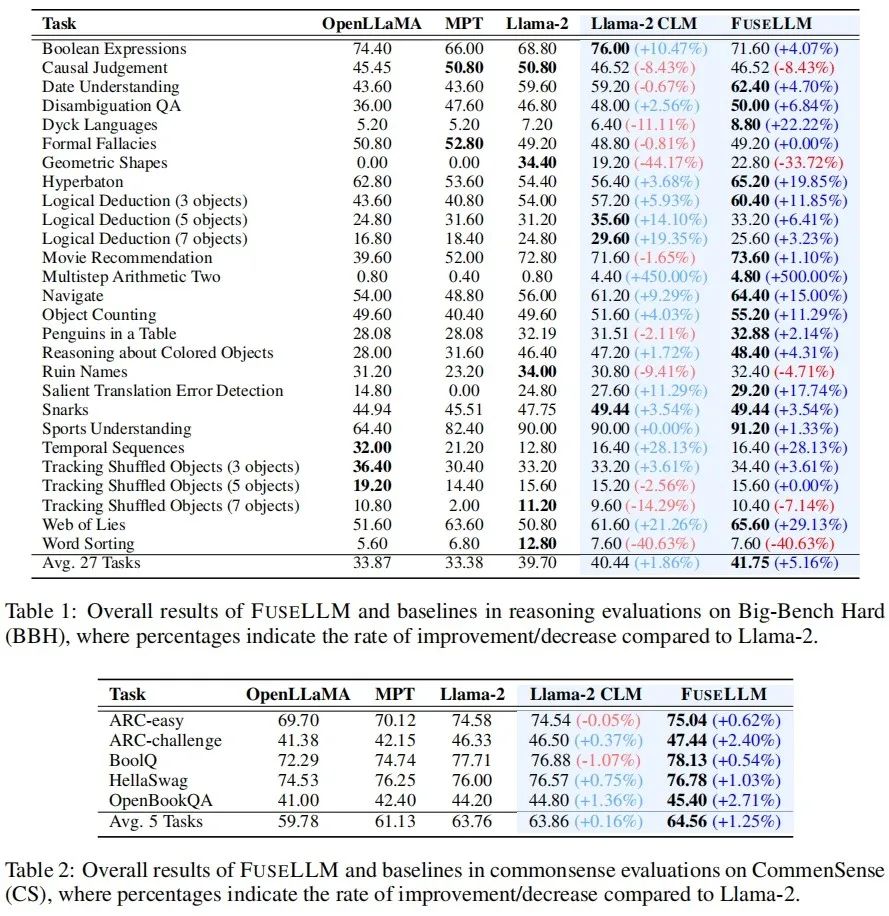

 ## Since FuseLLM only It is necessary to extract the representations of multiple source models for fusion, and then continuously train the target model, so it can also be applied to the fusion of instruction fine-tuning large language models. On the Vicuna Benchmark, which evaluates instruction following ability, FuseLLM also achieved excellent performance, surpassing all source models and CLM.
## Since FuseLLM only It is necessary to extract the representations of multiple source models for fusion, and then continuously train the target model, so it can also be applied to the fusion of instruction fine-tuning large language models. On the Vicuna Benchmark, which evaluates instruction following ability, FuseLLM also achieved excellent performance, surpassing all source models and CLM. 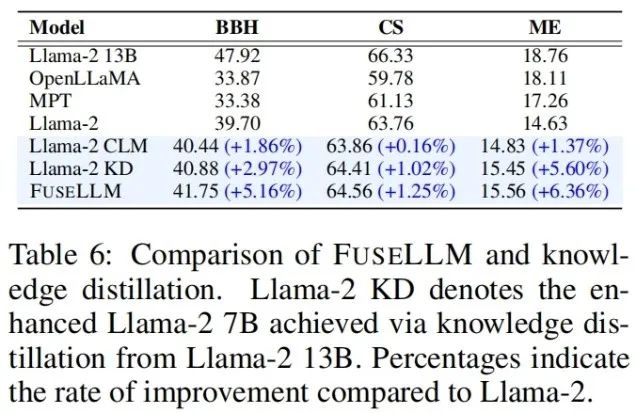 Considering that knowledge distillation is also a method of using representation to improve the performance of large language models, the author compared FuseLLM with Llama-2 KD distilled with Llama-2 13B. Results show that FuseLLM outperforms distillation from a single 13B model by fusing three 7B models with different architectures.
Considering that knowledge distillation is also a method of using representation to improve the performance of large language models, the author compared FuseLLM with Llama-2 KD distilled with Llama-2 13B. Results show that FuseLLM outperforms distillation from a single 13B model by fusing three 7B models with different architectures.  To compare FuseLLM with existing fusion methods (such as model ensemble and weight merging), the authors simulated multiple source models from the same structure base model, but continuously trained on different corpora, and tested the perplexity of various methods on different test benchmarks. It can be seen that although all fusion techniques can combine the advantages of multiple source models, FuseLLM can achieve the lowest average perplexity, indicating that FuseLLM has the potential to combine the collective knowledge of source models more effectively than model ensemble and weight merging methods.
To compare FuseLLM with existing fusion methods (such as model ensemble and weight merging), the authors simulated multiple source models from the same structure base model, but continuously trained on different corpora, and tested the perplexity of various methods on different test benchmarks. It can be seen that although all fusion techniques can combine the advantages of multiple source models, FuseLLM can achieve the lowest average perplexity, indicating that FuseLLM has the potential to combine the collective knowledge of source models more effectively than model ensemble and weight merging methods.
The above is the detailed content of The fusion of multiple heterogeneous large models brings amazing results. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1421
52
1315
25
1266
29
1239
24
14
1421
52
1315
25
1266
29
1239
24

 Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
The top ten cryptocurrency exchanges in the world in 2025 include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, KuCoin, Bittrex and Poloniex, all of which are known for their high trading volume and security.
 How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
DMA in C refers to DirectMemoryAccess, a direct memory access technology, allowing hardware devices to directly transmit data to memory without CPU intervention. 1) DMA operation is highly dependent on hardware devices and drivers, and the implementation method varies from system to system. 2) Direct access to memory may bring security risks, and the correctness and security of the code must be ensured. 3) DMA can improve performance, but improper use may lead to degradation of system performance. Through practice and learning, we can master the skills of using DMA and maximize its effectiveness in scenarios such as high-speed data transmission and real-time signal processing.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
Handling high DPI display in C can be achieved through the following steps: 1) Understand DPI and scaling, use the operating system API to obtain DPI information and adjust the graphics output; 2) Handle cross-platform compatibility, use cross-platform graphics libraries such as SDL or Qt; 3) Perform performance optimization, improve performance through cache, hardware acceleration, and dynamic adjustment of the details level; 4) Solve common problems, such as blurred text and interface elements are too small, and solve by correctly applying DPI scaling.
 What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
C performs well in real-time operating system (RTOS) programming, providing efficient execution efficiency and precise time management. 1) C Meet the needs of RTOS through direct operation of hardware resources and efficient memory management. 2) Using object-oriented features, C can design a flexible task scheduling system. 3) C supports efficient interrupt processing, but dynamic memory allocation and exception processing must be avoided to ensure real-time. 4) Template programming and inline functions help in performance optimization. 5) In practical applications, C can be used to implement an efficient logging system.
 Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
The built-in quantization tools on the exchange include: 1. Binance: Provides Binance Futures quantitative module, low handling fees, and supports AI-assisted transactions. 2. OKX (Ouyi): Supports multi-account management and intelligent order routing, and provides institutional-level risk control. The independent quantitative strategy platforms include: 3. 3Commas: drag-and-drop strategy generator, suitable for multi-platform hedging arbitrage. 4. Quadency: Professional-level algorithm strategy library, supporting customized risk thresholds. 5. Pionex: Built-in 16 preset strategy, low transaction fee. Vertical domain tools include: 6. Cryptohopper: cloud-based quantitative platform, supporting 150 technical indicators. 7. Bitsgap:
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
 An efficient way to batch insert data in MySQL
Apr 29, 2025 pm 04:18 PM
An efficient way to batch insert data in MySQL
Apr 29, 2025 pm 04:18 PM
Efficient methods for batch inserting data in MySQL include: 1. Using INSERTINTO...VALUES syntax, 2. Using LOADDATAINFILE command, 3. Using transaction processing, 4. Adjust batch size, 5. Disable indexing, 6. Using INSERTIGNORE or INSERT...ONDUPLICATEKEYUPDATE, these methods can significantly improve database operation efficiency.
