
 Technology peripherals
AI
LLM learns to fight each other, and the basic model may usher in group innovation
Technology peripherals
AI
LLM learns to fight each other, and the basic model may usher in group innovation
LLM learns to fight each other, and the basic model may usher in group innovation

There is a martial arts stunt in Jin Yong's martial arts novels: left and right fighting; it was a martial art created by Zhou Botong who practiced hard in a cave on Taohua Island for more than ten years. The initial idea was to fight with the left hand and the right hand for his own entertainment. happy. This idea can not only be used to practice martial arts, but can also be used to train machine learning models, such as the Generative Adversarial Network (GAN) that was all the rage in the past few years.
In today’s large model (LLM) era, researchers have discovered the subtle use of left and right interaction. Recently, Gu Quanquan's team at the University of California, Los Angeles, proposed a new method called SPIN (Self-Play Fine-Tuning). This method can greatly improve the capabilities of LLM only through self-game without using additional fine-tuning data. Professor Gu Quanquan said: "It is better to teach someone to fish than to teach him to fish: through self-game fine-tuning (SPIN), all large models can be improved from weak to strong!"
This research has also caused a lot of discussion on social networks. For example, Professor Ethan Mollick of the Wharton School of the University of Pennsylvania said: "More evidence shows that AI will not be limited by the resources available for its training. of human-created content. This paper once again shows that training AI using AI-created data can achieve higher-quality results than using only human-created data."
In addition, many researchers are excited about this method and have great expectations for progress in related directions in 2024. Professor Gu Quanquan told Machine Heart: "If you want to train a large model beyond GPT-4, this is a technology definitely worth trying."

The paper address is https://arxiv.org/pdf/2401.01335.pdf.
Large language models (LLMs) have ushered in an era of breakthroughs in general artificial intelligence (AGI), with extraordinary capabilities to solve a wide range of tasks that require complex reasoning and expertise. LLM areas of expertise include mathematical reasoning/problem solving, code generation/programming, text generation, summarizing and creative writing, and more.
One of the key advancements in LLM is the alignment process after training, which can make the model behave more in line with requirements, but this process often relies on costly human-labeled data. Classic alignment methods include supervised fine-tuning (SFT) based on human demonstrations and reinforcement learning based on human preference feedback (RLHF).
These alignment methods all require a large amount of human-labeled data. Therefore, to streamline the alignment process, researchers hope to develop fine-tuning methods that effectively leverage human data.
This is also the goal of this research: to develop new fine-tuning methods so that the fine-tuned model can continue to become stronger, and this fine-tuning process does not require the use of humans outside the fine-tuning data set Label the data.
In fact, the machine learning community has always been concerned about how to improve weak models into strong models without using additional training data. Research in this area can even be traced back to the boosting algorithm . Studies have also shown that self-training algorithms can convert weak learners into strong learners in hybrid models without the need for additional labeled data. However, the ability to automatically improve LLM without external guidance is complex and poorly studied. This leads to the following question:
Can we make LLM self-improvement without additional human-labeled data?
Method
In technical detail, we can convert the The LLM, denoted as pθt, generates a response y' to a prompt x in the human-annotated SFT dataset. The next goal is to find a new LLM pθ{t 1} that has the ability to distinguish the response y' generated by pθt from the response y given by a human.
This process can be regarded as a game process between two players: the main player is the new LLM pθ{t 1}, and its goal is to distinguish the response of the opponent player pθt and the human generation response; the opponent player is the old LLM pθt, whose task is to generate responses that are as close as possible to the human-annotated SFT data set.
The new LLM pθ{t 1} is obtained by fine-tuning the old LLM pθt. The training process allows the new LLM pθ{t 1} to have a good ability to distinguish the response y' generated by pθt and that given by humans. response y. This training not only allows the new LLM pθ{t 1} to achieve good discrimination ability as a main player, but also allows the new LLM pθ{t 1} to provide more aligned SFT data as an opponent player in the next iteration. set response. In the next iteration, the newly obtained LLM pθ{t 1} becomes the response generated opponent player.
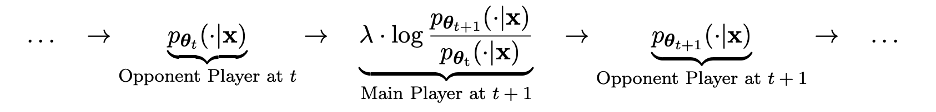

##The goal of this self-game process is to make LLM finally Convergence to pθ∗ = p_data is such that the most powerful possible LLM generates responses that no longer differ from its previous versions and human-generated responses.
Interestingly, this new method shows similarity with the direct preference optimization (DPO) method recently proposed by Rafailov et al., but the obvious difference of the new method is that it uses self- Game mechanism. Therefore, this new method has a significant advantage: no additional human preference data is required.
In addition, we can also clearly see the similarity between this new method and the Generative Adversarial Network (GAN), except that the discriminator (main player) and generator in the new method (The opponent) is an instance of the same LLM after two adjacent iterations.
The team also conducted a theoretical proof of this new method, and the results showed that the method can converge if and only if the distribution of LLM is equal to the target data distribution, that is, when p_θ_t=p_data .
Experiment
In the experiment, the team used a fine-tuned LLM instance zephyr-7b-sft-full based on Mistral-7B .
The results show that the new method can continue to improve zephyr-7b-sft-full in consecutive iterations, and as a comparison, when using the SFT method to continuously train on the SFT dataset Ultrachat200k, The evaluation score will reach the performance bottleneck or even decline.
What’s more interesting is that the dataset used by the new method is only a 50k-sized subset of the Ultrachat200k dataset!
The new method SPIN has another achievement: it can effectively improve the average score of the base model zephyr-7b-sft-full in the HuggingFace Open LLM rankings from 58.14 to 63.16. Among them, there is an astonishing improvement of more than 10% on GSM8k and TruthfulQA, and it can also be improved from 5.94 to 6.78 on MT-Bench.
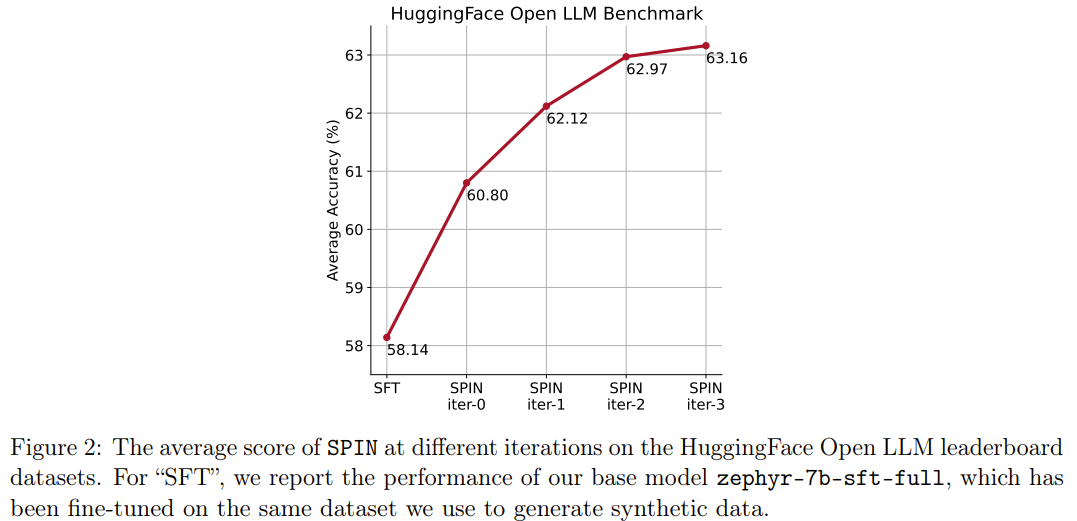
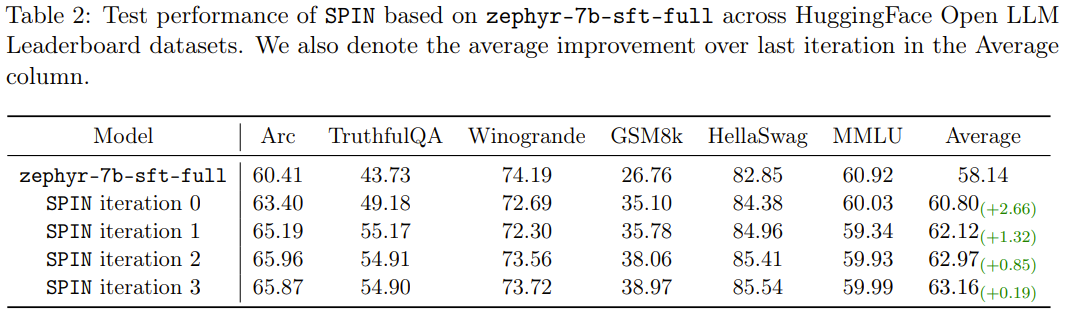
It is worth noting that in the Open LLM rankings, the model using SPIN fine-tuning can even compete with The model trained using an additional 62k preference dataset is comparable.
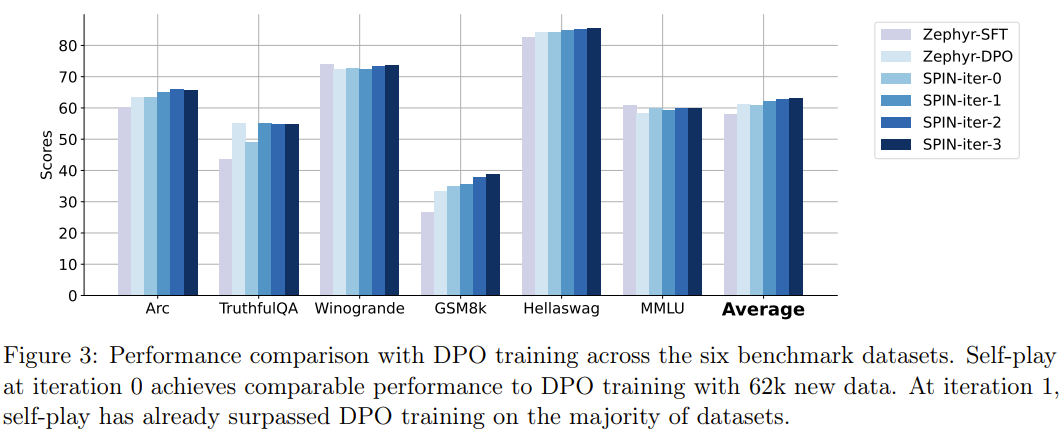
Conclusion
By making full use of human-labeled data, SPIN allows large models to rely on self-gaming to overcome weaknesses. Become stronger. Compared to reinforcement learning based on human preference feedback (RLHF), SPIN enables LLM to self-improve without additional human feedback or stronger LLM feedback. In experiments on multiple benchmark datasets including the HuggingFace Open LLM leaderboard, SPIN significantly and stably improves the performance of LLM, even outperforming models trained with additional AI feedback.
We expect that SPIN can help the evolution and improvement of large models, and ultimately achieve artificial intelligence beyond human levels.
The above is the detailed content of LLM learns to fight each other, and the basic model may usher in group innovation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1653
1653
 14
1413
52
1305
25
1251
29
1224
24
14
1413
52
1305
25
1251
29
1224
24

 What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
The top ten digital currency exchanges such as Binance, OKX, gate.io have improved their systems, efficient diversified transactions and strict security measures.
 Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
The top ten cryptocurrency trading platforms in the world include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, KuCoin and Poloniex, all of which provide a variety of trading methods and powerful security measures.
 Recommended reliable digital currency trading platforms. Top 10 digital currency exchanges in the world. 2025
Apr 28, 2025 pm 04:30 PM
Recommended reliable digital currency trading platforms. Top 10 digital currency exchanges in the world. 2025
Apr 28, 2025 pm 04:30 PM
Recommended reliable digital currency trading platforms: 1. OKX, 2. Binance, 3. Coinbase, 4. Kraken, 5. Huobi, 6. KuCoin, 7. Bitfinex, 8. Gemini, 9. Bitstamp, 10. Poloniex, these platforms are known for their security, user experience and diverse functions, suitable for users at different levels of digital currency transactions
 Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
The top ten cryptocurrency exchanges in the world in 2025 include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, KuCoin, Bittrex and Poloniex, all of which are known for their high trading volume and security.
 How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
Bitcoin’s price ranges from $20,000 to $30,000. 1. Bitcoin’s price has fluctuated dramatically since 2009, reaching nearly $20,000 in 2017 and nearly $60,000 in 2021. 2. Prices are affected by factors such as market demand, supply, and macroeconomic environment. 3. Get real-time prices through exchanges, mobile apps and websites. 4. Bitcoin price is highly volatile, driven by market sentiment and external factors. 5. It has a certain relationship with traditional financial markets and is affected by global stock markets, the strength of the US dollar, etc. 6. The long-term trend is bullish, but risks need to be assessed with caution.
 What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
Currently ranked among the top ten virtual currency exchanges: 1. Binance, 2. OKX, 3. Gate.io, 4. Coin library, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9. Bitcoin, 10. bit stamp.
 Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0 redefines crypto asset management through innovative architecture and performance breakthroughs. 1) It solves three major pain points: asset silos, income decay and paradox of security and convenience. 2) Through intelligent asset hubs, dynamic risk management and return enhancement engines, cross-chain transfer speed, average yield rate and security incident response speed are improved. 3) Provide users with asset visualization, policy automation and governance integration, realizing user value reconstruction. 4) Through ecological collaboration and compliance innovation, the overall effectiveness of the platform has been enhanced. 5) In the future, smart contract insurance pools, forecast market integration and AI-driven asset allocation will be launched to continue to lead the development of the industry.
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
