
今天跟大家聊一聊大模型时间序列预测的最新工作,来自阿里巴巴达摩院,提出了一种基于adaptor的通用时间序列分析框架,在长周期预测、短周期预测、zero-shot、few-shot、异常检测、时间序列分类、时间序列填充等7项时间序列任务上都取得了显著的效果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
论文标题:一刀切:使用预训练语言模型和特别设计的适配器进行通用时间序列分析
可下载链接:https://arxiv.org/pdf/2311.14782v1.pdf
时间序列预测领域中,搭建大型模型的难点之一在于缺乏如NLP或CV领域那样的充足的训练数据。本文提出了一种解决方案,即以NLP或CV领域中训练好的大型模型为基础,并结合Adaptor技术,将其适配到时间序列中,以解决各种时间序列问题
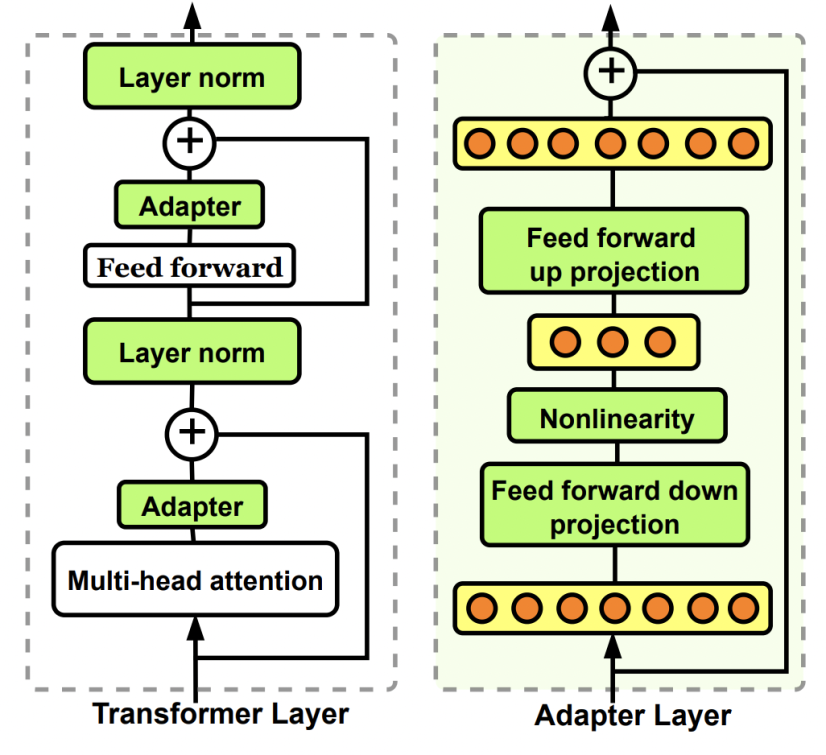
Adaptor在NLP、CV等领域应用很广泛,尤其是最近大模型应用中,adaptor经常被用来进行大模型的轻量级finetune。Adaptor是一个轻量级网络,通过将其插入到大模型中的一些模块中,然后fix大模型参数,只更新adaptor的参数,就可以实现轻量级的大模型finetune。
 图片
图片
下面,给大家介绍阿里达摩院这篇工作中,是如何利用adaptor结合预训练的NLP、CV模型搭建统一时间序列模型的。
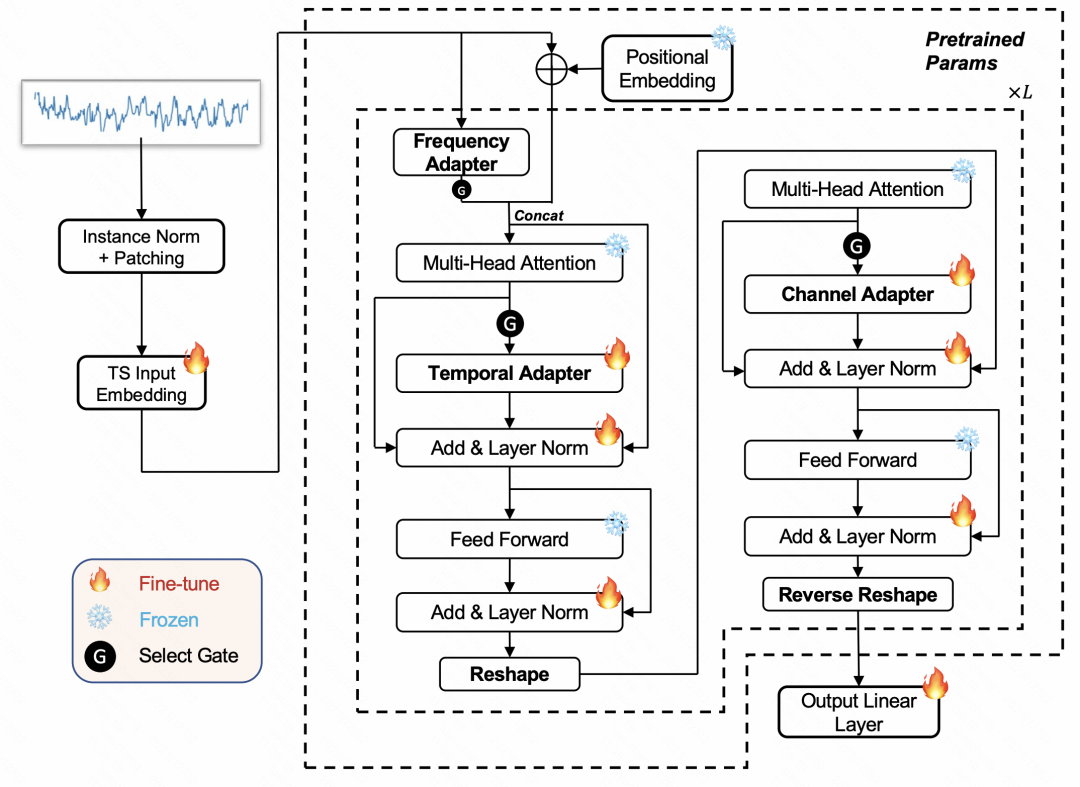
本文提出的模型基于Freeze参数的预训练语言模型,结合4种类型的adaptor实现。整体模型结构如下图所示。
 图片
图片
首先,对于输入的时间序列,我们将使用RevIN的方法进行归一化。这意味着我们会从每个时间序列中减去均值,并除以方差。接下来,我们将使用PatchTST的方法,将时间序列通过滑动窗口切分成多个片段,生成片段嵌入。处理好的时间序列将被输入到一个NLP领域的预训练语言模型中。在整个训练过程中,语言模型的原始参数将保持不变,我们只会更新新增的4类适配器参数
本文介绍了四种类型的适配器,这些适配器可以插入到NLP和CV领域的大型模型的不同位置,以实现对时间序列进行适配的目标。这四种适配器分别是时间适配器、通道适配器、频率适配器和异常适配器
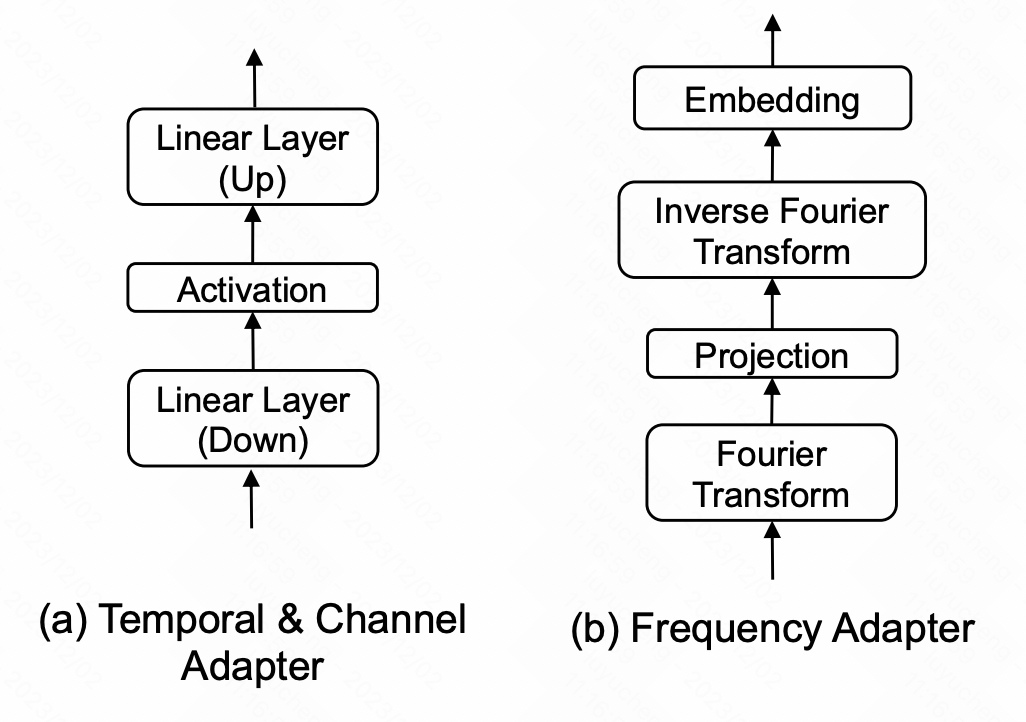
时间适配器:时间适配器是一个MLP网络,用于融合时间维度的信息。在文中,我们采用了瓶颈结构,先将时间维度或空间维度的高维信息映射到低维空间,然后再映射回高维空间。这样做的目的是在提取时序关系的过程中避免过拟合的风险
Channel Adaptor:channel adaptor的结构和temporal adaptor相似,区别在于在空间维度进行,用来提取多元序列各个变量之间的关系,也采用了bottlenect;
 图片
图片
Frequency Adaptor:frequency adaptor在频域进行时间序列的信息提取,这部分将时间序列映射到频域,在频域做MLP,然后再映射回时域,以此实现频域这种全局信息的提取。
Anomaly Adapter:这部分主要是实现了一种新的时间序列异常检测方法,这里利用了attention score矩阵,对于正常序列attention score矩阵呈现周期重复的特性,而异常序列则没有,因此文中使用一个高斯核作为anomaly adaptor,用attention的输出结果和其计算KL散度进行时间序列异常检测。
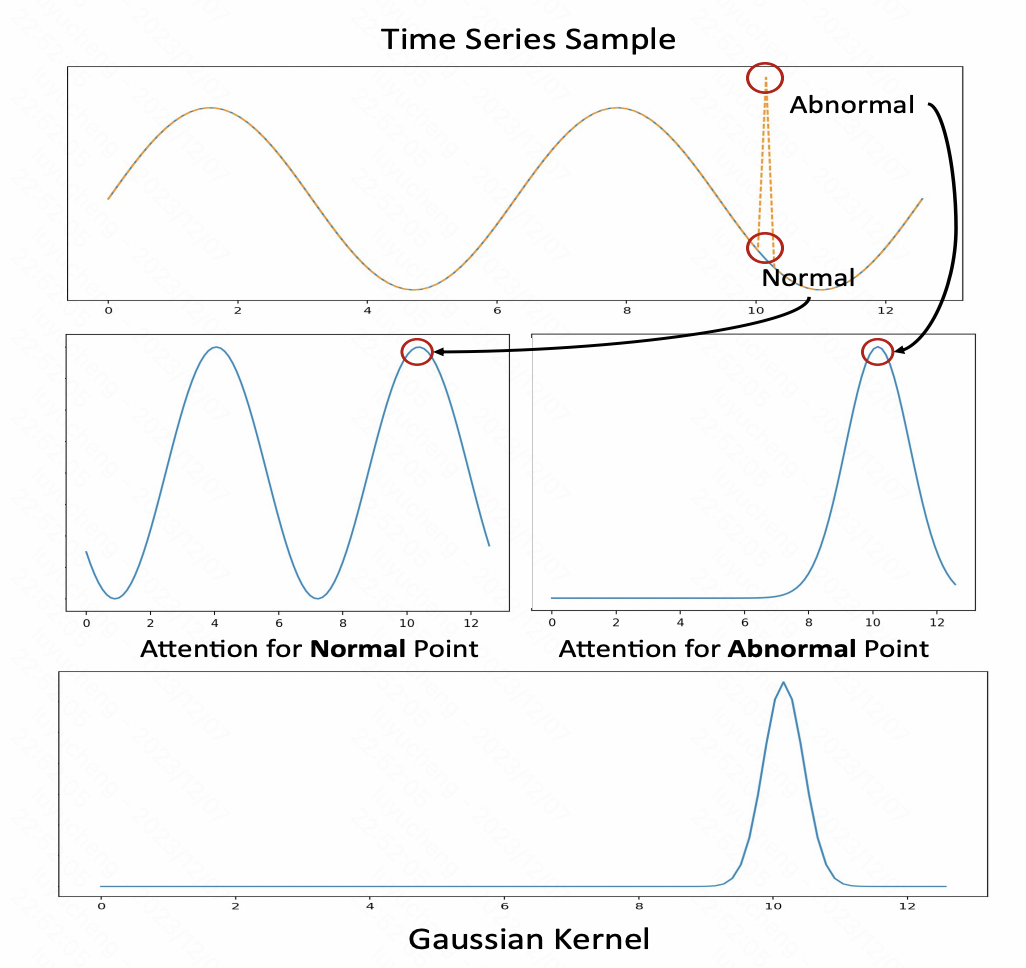 图片
图片
另外,不同的数据会受到各个适配器的影响程度不同,因此,在文中采用了一个门控网络,以有选择地使用适配器
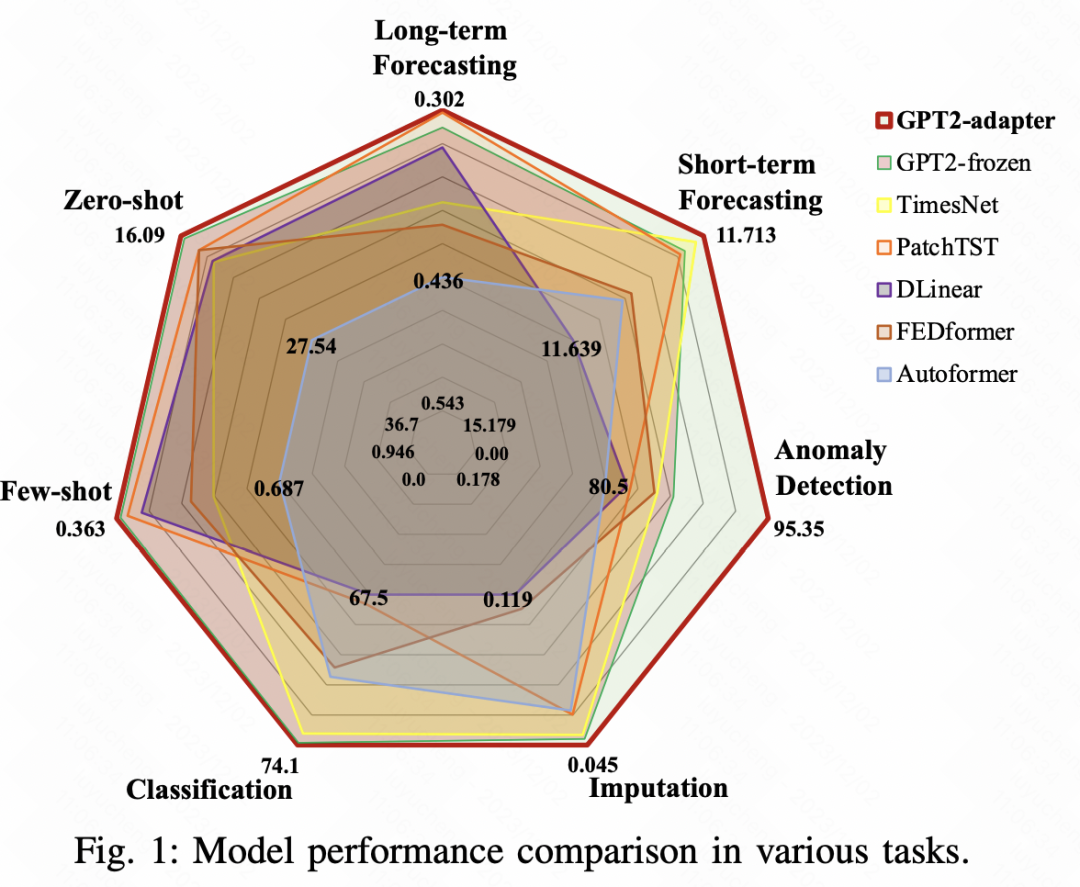
对7种时间序列任务进行了效果对比,本文提出的时间序列统一大模型在各个任务中取得了超出业内各个SOTA模型的效果。以长周期预测任务为例,基于GPT2+Adaptor的统一模型表现最优
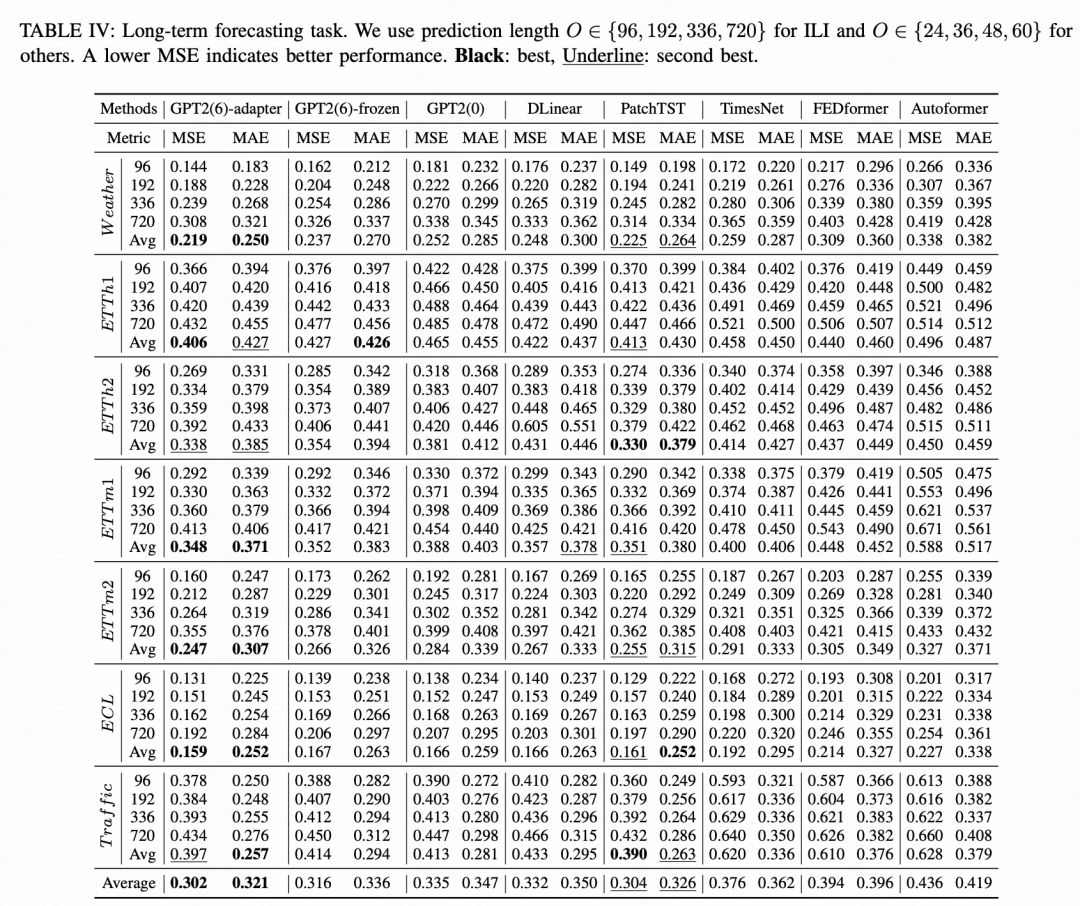 图片
图片
以上就是基于Adaptor和GPT的时间序列多任务一体化大型模型的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 299
299





















