
 Technology peripherals
AI
All-round open source with no dead ends, Xingbo team's LLM360 makes large models truly transparent
Technology peripherals
AI
All-round open source with no dead ends, Xingbo team's LLM360 makes large models truly transparent
All-round open source with no dead ends, Xingbo team's LLM360 makes large models truly transparent

Open source models are showing their vigorous vitality, not only the number is increasing, but the performance is getting better and better. Turing Award winner Yann LeCun also lamented: "Open source artificial intelligence models are on the road to surpassing proprietary models."
Proprietary models are in technical performance and innovation It shows great potential in terms of capabilities, but due to its non-open source characteristics, it hinders the development of LLM. Although some open source models provide practitioners and researchers with diverse choices, most only disclose the final model weights or inference code, and an increasing number of technical reports limit their scope to top-level design and surface statistics. . This closed-source strategy not only limits the development of open-source models, but also hinders the progress of the entire LLM research field to a great extent. This means that these models need to be more comprehensive and Share in depth, including training data, algorithm details, implementation challenges, and performance evaluation details.
Researchers from Cerebras, Petuum and MBZUAI jointly proposed LLM360. This is a comprehensive open source LLM initiative that advocates providing the community with everything related to LLM training, including training code and data, model checkpoints, and intermediate results. The goal of LLM360 is to make the LLM training process transparent and reproducible for everyone, thereby promoting the development of open and collaborative artificial intelligence research.

- Project web page: https://www.llm360.ai/
- Blog: https://www.llm360.ai/blog/introducing-llm360-fully-transparent-open-source-llms.html
- Researcher We developed the architecture of LLM360, focusing on its design principles and the rationale for being fully open source. They specify the components of the LLM360 framework, including specific details such as datasets, code and configuration, model checkpoints, metrics, and more. LLM360 sets an example of transparency for current and future open source models.
Researchers released two large-scale language models pre-trained from scratch under the open source framework of LLM360: AMBER and CRYSTALCODER. AMBER is a 7B English language model pre-trained based on 1.3T tokens. CRYSTALCODER is a 7B English and code language model pre-trained based on 1.4T tokens. In this article, the researchers summarize the development details, preliminary evaluation results, observations, and experiences and lessons learned from these two models. Notably, at the time of release, AMBER and CRYSTALCODER saved 360 and 143 model checkpoints during training, respectively.
 Now, let’s take a look at the details of the article
Now, let’s take a look at the details of the article
## The framework of #LLM360
LLM360 will provide a standard for what data and codes need to be collected during the LLM pre-training process to ensure that existing work can be better circulated and shared in the community . It mainly contains the following parts:
1. Training data set and data processing code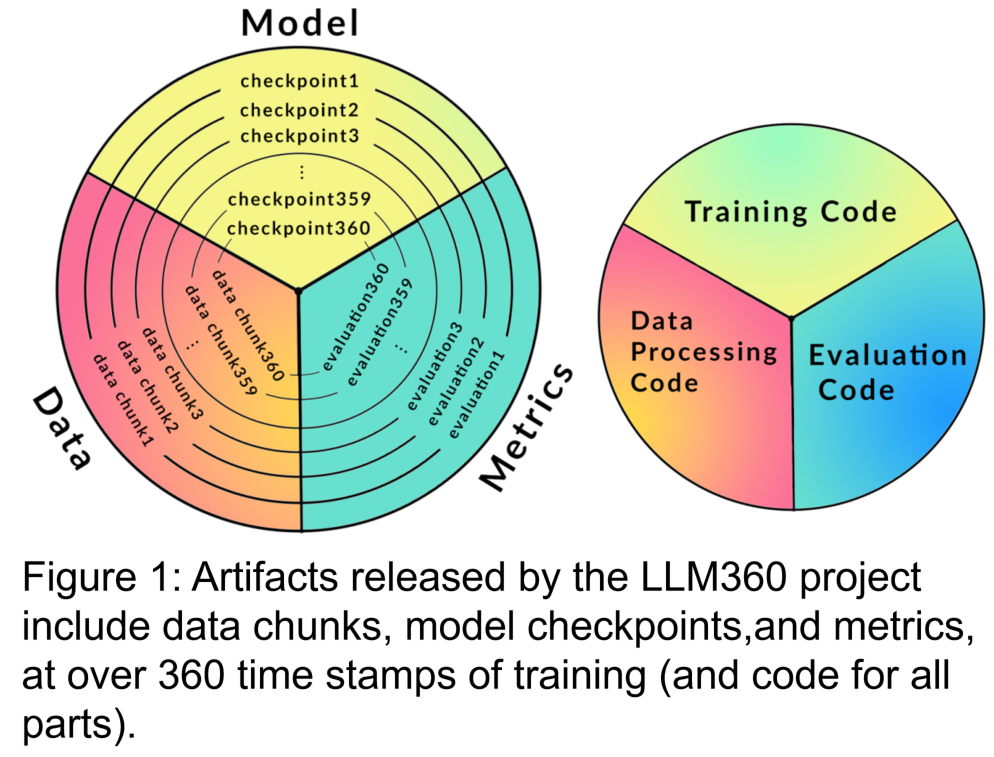
Pre-training datasets are critical to the performance of large language models. Therefore, it is important to understand the pre-training data set to assess potential behavioral issues and biases. Additionally, publicly available pre-training datasets help improve LLM’s scalability when subsequently fine-tuned and adapted to various domains. Recent research shows that training on repeated data disproportionately reduces the final performance of the model. Therefore, exposing the original pre-training data helps avoid using duplicate data when fine-tuning downstream or continuing to pre-train in a specific domain. Based on the above reasons, LLM360 advocates the disclosure of raw data sets of large language models. Where appropriate, details about data filtering, processing, and training sequences should also be disclosed.
The content that needs to be rewritten is: 2. Training code, hyperparameters and configuration
Training code, hyperparameters, and configuration have a significant impact on the performance and quality of LLM training, but are not always publicly disclosed. In LLM360, researchers open source all the training code, training parameters and system configuration of the pre-training framework.
3. Model checkpoint is rewritten as: 3. Model checkpoint
Regularly saved model checkpoints are also Quite useful. Not only are they critical for failure recovery during training, but they are also useful for post-training research. These checkpoints allow subsequent researchers to continue training the model from multiple starting points without having to train from scratch, aiding in reproducibility. and in-depth research.
4. Performance indicators
Training an LLM often takes weeks to months , the evolutionary trends during training can provide valuable information. However, detailed logs and intermediate metrics of training are currently only available to those who have experienced them, which hinders comprehensive research on LLM. These statistics often contain key insights that are difficult to detect. Even a simple analysis such as variance calculations on these measures can reveal important findings. For example, the GLM research team proposed a gradient shrinkage algorithm that effectively handles loss spikes and NaN losses by analyzing the gradient specification behavior.
Amber
AMBER is the first member of the LLM360 "family". Also released are its fine-tuned versions: AMBERCHAT and AMBERSAFE.

What needs to be rewritten: details of data and model
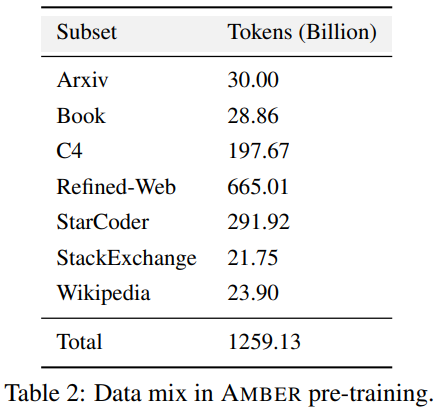
Table 2 details AMBER’s pre-training data set, which contains 1.26 T markers. These include data preprocessing methods, formats, data mixing ratios, as well as architectural details and specific pretraining hyperparameters of the AMBER model. For detailed information, please refer to the project homepage of the LLM360 code base
##AMBER adopts the same model structure as LLaMA 7B4, Table 3 The detailed structural configuration of LLM is summarized. Training hyperparameters. AMBER is trained using the AdamW optimizer, and the hyperparameters are: β₁=0.9, β₂=0.95. In addition, researchers have released several fine-tuned versions of AMBER: AMBERCHAT and AMBERSAFE. AMBERCHAT is fine-tuned based on WizardLM's instruction training data set. For more parameter details, please refer to the original text
In order to achieve the purpose of not changing the original meaning, the content needs to be rewritten into Chinese. The following is a rewrite of "Experiments and Results":
Conduct experiments and result analysis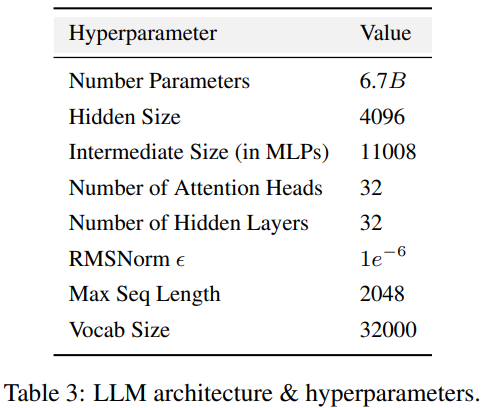
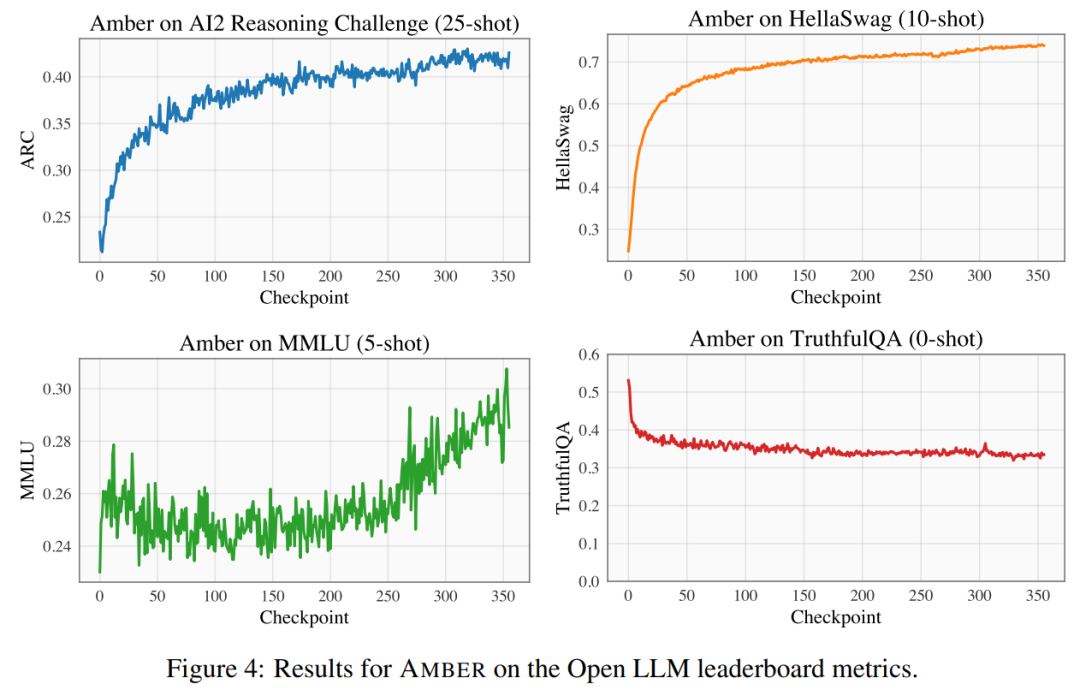
#The researchers used four benchmark data sets on the Open LLM rankings to evaluate the performance of AMBER. As shown in Figure 4, in the HellaSwag and ARC data sets, the AMBER score gradually increases during the pre-training period, while in the TruthfulQA data set, the score decreases as training proceeds. In the MMLU dataset, the score of AMBER decreases in the initial stage of pre-training and then starts to increase
in Table 4 , the researchers compared the model performance of AMBER with models trained in similar time periods such as OpenLLaMA, RedPajama-INCITE, Falcon, and MPT. Many models are inspired by LLaMA. It can be found that AMBER scores better on MMLU but performs slightly worse on ARC. AMBER's performance is relatively strong compared to other similar models.
CRYSTALCODER
The second member of LLM360 "Big Family" is CrystalCoder. 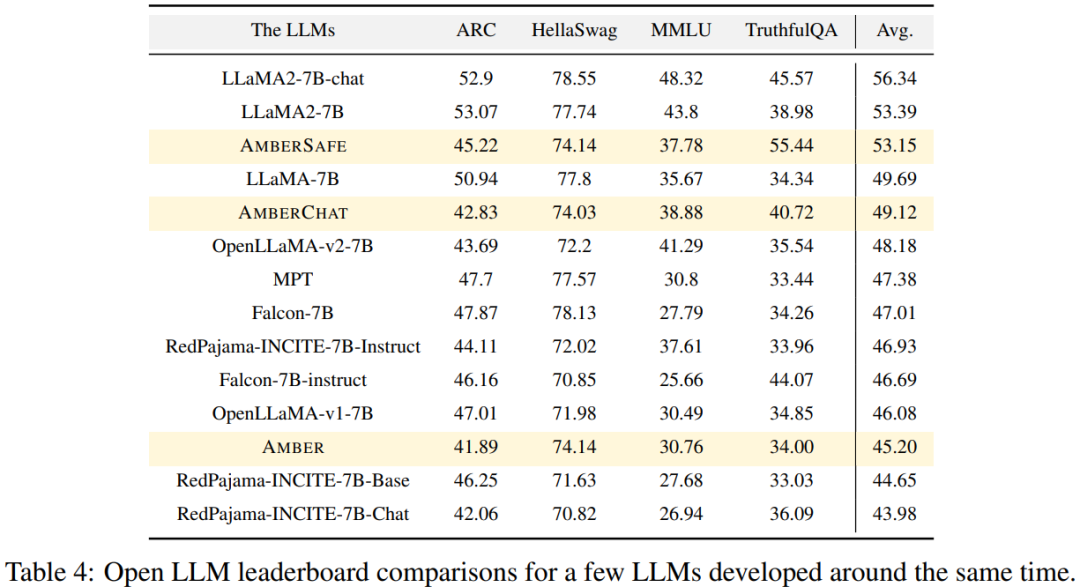
CrystalCoder is a 7B language model trained on 1.4 T tokens, achieving a balance between coding and language capabilities. Unlike most previous code LLMs, CrystalCoder is trained on a careful mixture of text and code data to maximize utility in both domains. Compared with Code Llama 2, CrystalCoder's code data is introduced earlier in the pre-training process. In addition, the researchers trained CrystalCoder on Python and web programming languages to improve its usefulness as a programming assistant.
Rebuild the model architecture
CrystalCoder adopts a very similar architecture to LLaMA 7B, adding the maximum update parameter Chemistry (muP). In addition to this specific parameterization, the researchers also made some modifications. In addition, the researchers also used LayerNorm instead of RMSNorm because the CG-1 architecture supports efficient calculation of LayerNorm.
#In order to achieve the purpose of not changing the original meaning, the content needs to be rewritten into Chinese. The following is a rewrite of "Experiments and Results": Conduct experiments and result analysis
#On the Open LLM Leaderboard, the researcher conducted a benchmark test on the model, including four benchmark data sets and a coding benchmark data set. As shown in Figure 6
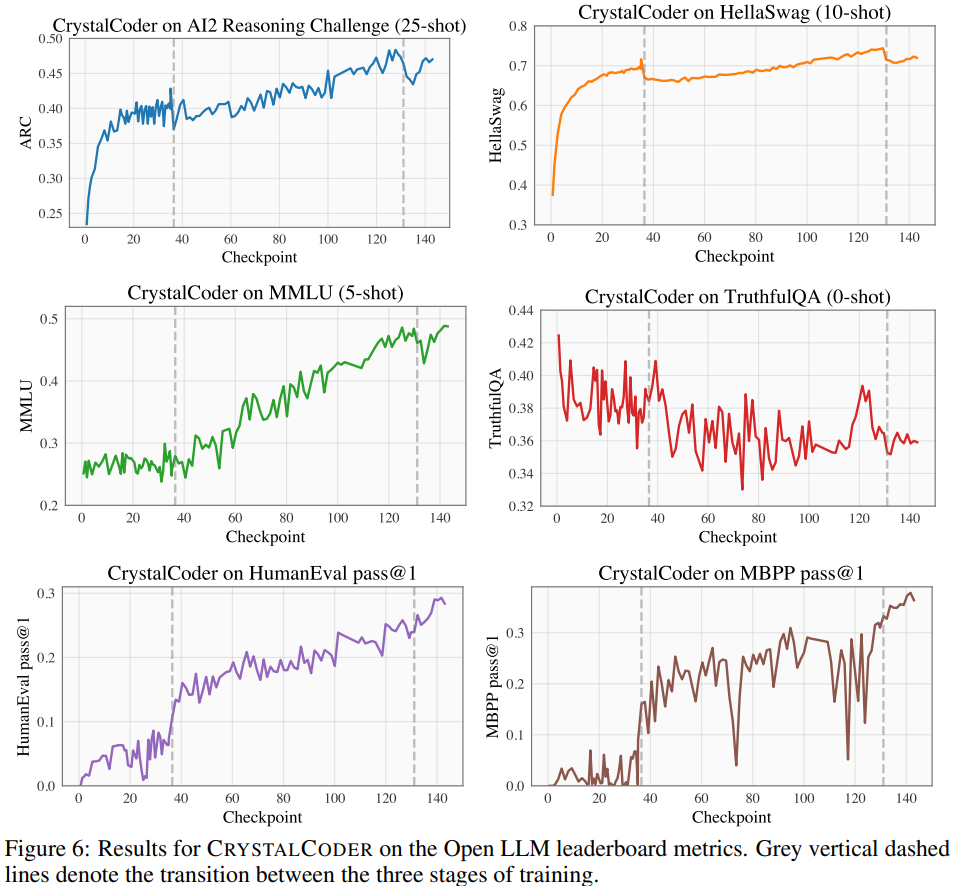
Referring to Table 5, you can see that CrystalCoder has achieved a good balance between language tasks and code tasks
ANALYSIS360
Based on previous research, in-depth research can be carried out by analyzing the intermediate checkpoints of the model. Researchers hope LLM360 will provide the community with a useful reference and research resource. To this end, they released the initial version of the ANALYSIS360 project, an organized repository of multifaceted analyzes of model behavior, including model characteristics and downstream evaluation results
as a An example of analyzing a series of model checkpoints. The researchers conducted a preliminary study on memoization in LLM. Recent research has shown that LLMs may memorize large portions of training data and that this data can be retrieved with appropriate prompts. Not only does this memoization have problems with leaking private training data, but it can also degrade LLM performance if the training data contains repetitions or specificities. The researchers made all checkpoints and data public so that a comprehensive analysis of memorization throughout the training phase can be performed.
The following is the memorization score method used in this article, which is expressed in length The accuracy of the prompt of k followed by the token of length l. For specific memory score settings, please refer to the original article.
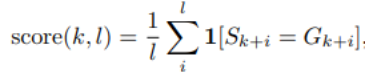
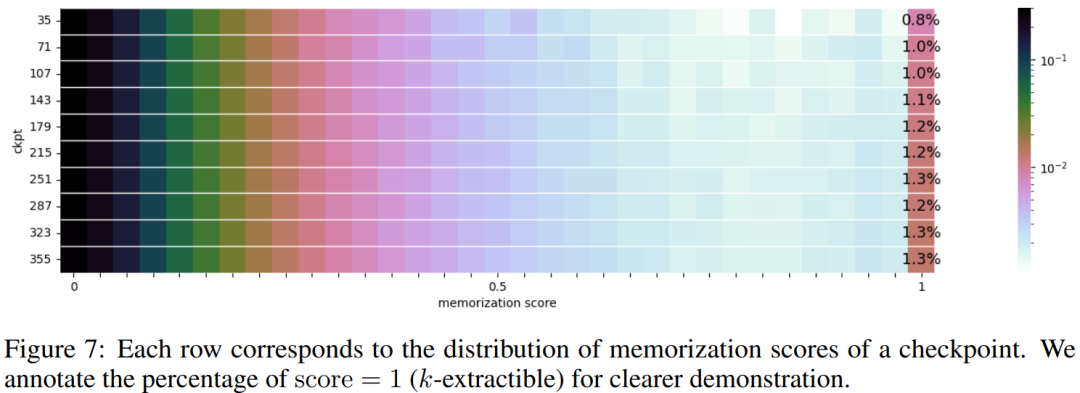
The distribution of memorized scores for 10 selected checkpoints is presented in Figure 7
The researchers grouped the data blocks according to the selected checkpoints and plotted each data block for each checkpoint in Figure 8 Memoized score of the group. They found that AMBER checkpoints memorize the latest data better than the previous data. Furthermore, for each data block, the memoization score decreases slightly after additional training, but then continues to increase.
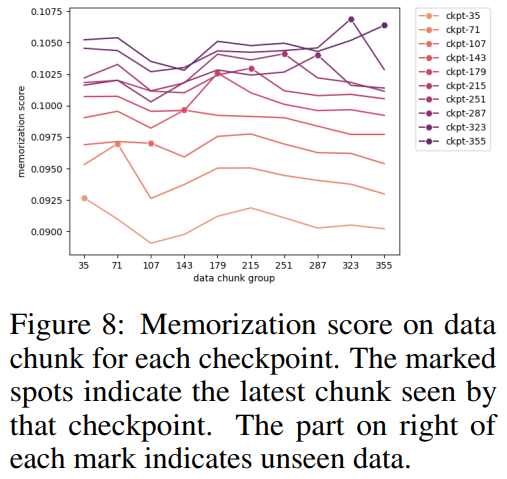
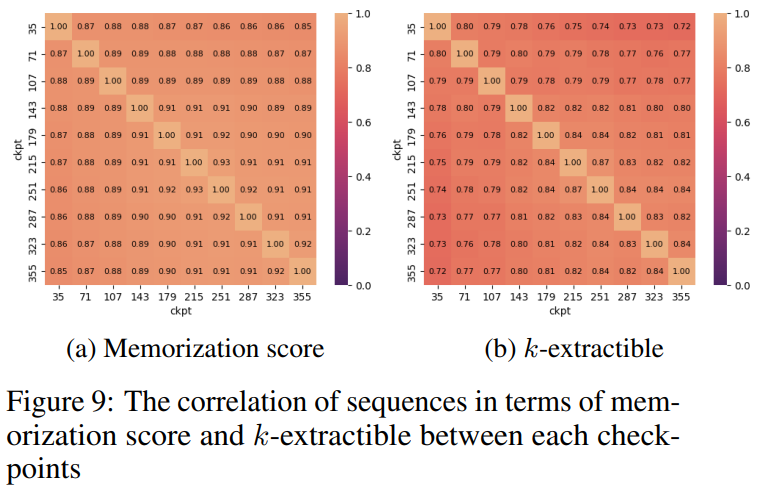
Figure 9 shows the correlation between sequences in memoization scores and extractable k values. It can be seen that there is a strong correlation between checkpoints.
Summary
The researcher summarized the observations and some implications of AMBER and CRYSTALCODER. They say pre-training is a computationally intensive task that many academic labs or small institutions cannot afford. They hope that LLM360 can provide comprehensive knowledge and let users understand what happens during LLM pre-training without having to do it themselves
Please see the original text for more details
The above is the detailed content of All-round open source with no dead ends, Xingbo team's LLM360 makes large models truly transparent. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1244
24
14
1423
52
1317
25
1268
29
1244
24

 How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
DMA in C refers to DirectMemoryAccess, a direct memory access technology, allowing hardware devices to directly transmit data to memory without CPU intervention. 1) DMA operation is highly dependent on hardware devices and drivers, and the implementation method varies from system to system. 2) Direct access to memory may bring security risks, and the correctness and security of the code must be ensured. 3) DMA can improve performance, but improper use may lead to degradation of system performance. Through practice and learning, we can master the skills of using DMA and maximize its effectiveness in scenarios such as high-speed data transmission and real-time signal processing.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
The built-in quantization tools on the exchange include: 1. Binance: Provides Binance Futures quantitative module, low handling fees, and supports AI-assisted transactions. 2. OKX (Ouyi): Supports multi-account management and intelligent order routing, and provides institutional-level risk control. The independent quantitative strategy platforms include: 3. 3Commas: drag-and-drop strategy generator, suitable for multi-platform hedging arbitrage. 4. Quadency: Professional-level algorithm strategy library, supporting customized risk thresholds. 5. Pionex: Built-in 16 preset strategy, low transaction fee. Vertical domain tools include: 6. Cryptohopper: cloud-based quantitative platform, supporting 150 technical indicators. 7. Bitsgap:
 How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
Handling high DPI display in C can be achieved through the following steps: 1) Understand DPI and scaling, use the operating system API to obtain DPI information and adjust the graphics output; 2) Handle cross-platform compatibility, use cross-platform graphics libraries such as SDL or Qt; 3) Perform performance optimization, improve performance through cache, hardware acceleration, and dynamic adjustment of the details level; 4) Solve common problems, such as blurred text and interface elements are too small, and solve by correctly applying DPI scaling.
 What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
C performs well in real-time operating system (RTOS) programming, providing efficient execution efficiency and precise time management. 1) C Meet the needs of RTOS through direct operation of hardware resources and efficient memory management. 2) Using object-oriented features, C can design a flexible task scheduling system. 3) C supports efficient interrupt processing, but dynamic memory allocation and exception processing must be avoided to ensure real-time. 4) Template programming and inline functions help in performance optimization. 5) In practical applications, C can be used to implement an efficient logging system.
 How to use string streams in C?
Apr 28, 2025 pm 09:12 PM
How to use string streams in C?
Apr 28, 2025 pm 09:12 PM
The main steps and precautions for using string streams in C are as follows: 1. Create an output string stream and convert data, such as converting integers into strings. 2. Apply to serialization of complex data structures, such as converting vector into strings. 3. Pay attention to performance issues and avoid frequent use of string streams when processing large amounts of data. You can consider using the append method of std::string. 4. Pay attention to memory management and avoid frequent creation and destruction of string stream objects. You can reuse or use std::stringstream.
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
 Steps to add and delete fields to MySQL tables
Apr 29, 2025 pm 04:15 PM
Steps to add and delete fields to MySQL tables
Apr 29, 2025 pm 04:15 PM
In MySQL, add fields using ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column, delete fields using ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop. When adding fields, you need to specify a location to optimize query performance and data structure; before deleting fields, you need to confirm that the operation is irreversible; modifying table structure using online DDL, backup data, test environment, and low-load time periods is performance optimization and best practice.
