
 Technology peripherals
AI
Complete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%
Technology peripherals
AI
Complete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%
Complete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%

In order to deal with the problem of insufficient visual information extraction in multi-modal large language models, researchers from Harbin Institute of Technology (Shenzhen) proposed a double-layer knowledge-enhanced multi-modal large language model-JiuTian- LION).

The content that needs to be rewritten is: Paper link: https://arxiv.org/abs/2311.11860
GitHub: https://github.com/rshaojimmy/JiuTian
Project homepage: https://rshaojimmy.github.io/Projects/JiuTian-LION
Compared with existing work, Jiutian analyzed the internal conflicts between image-level understanding tasks and regional-level positioning tasks for the first time, and proposed a segmented instruction fine-tuning strategy and a hybrid adapter to achieve both Mutual promotion of tasks.
By injecting fine-grained spatial perception and high-level semantic visual knowledge, Jiutian has achieved significant performance improvements in 17 visual language tasks including image description, visual problems, and visual localization. (For example, up to 5% performance improvement on Visual Spatial Reasoning). It has reached the international leading level in 13 of the evaluation tasks. The performance comparison is shown in Figure 1.
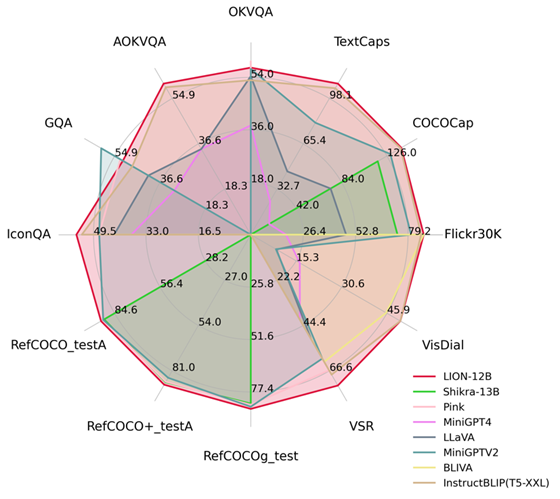
Figure 1: Compared with other MLLMs, Jiutian has achieved optimal performance on most tasks.
九天JiuTian-LION
By giving large language models (LLMs) multimodal awareness capabilities, some work has begun to generate multimodal large language models (MLLMs), And has made breakthrough progress in many visual language tasks. However, existing MLLMs mainly use visual encoders pre-trained on image-text pairs, such as CLIP-ViT
. The main task of these visual encoders is to learn coarse-grained images at the image level. Text modalities are aligned, but they lack comprehensive visual perception and information extraction capabilities for fine-grained visual understanding
To a large extent, this visual information extraction and understanding are insufficient Insufficient problems will lead to multiple defects in MLLMs such as visual localization bias, insufficient spatial reasoning, and object hallucination, as shown in Figure 2
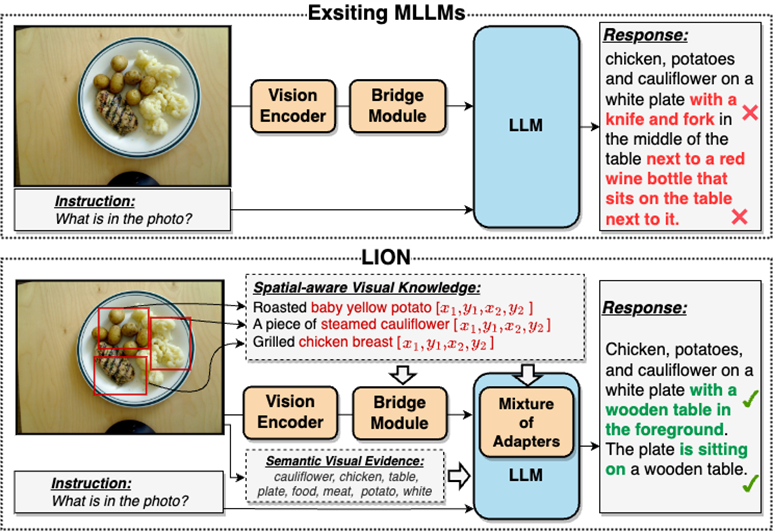
##Please Reference Figure 2: JiuTian-LION is a multi-modal large language model enhanced with double-layer visual knowledge
JiuTian-LION is compared with existing multi-modal large language Models (MLLMs), by injecting fine-grained spatial awareness visual knowledge and high-level semantic visual evidence, effectively improve the visual understanding capabilities of MLLMs, generate more accurate text responses, and reduce the hallucination phenomenon of MLLMs
Double-layer visual knowledge enhanced multi-modal large language model-JiuTian-LION
In order to solve the problem of MLLMs in visual information extraction and understanding In order to solve the shortcomings in this aspect, the researchers proposed a two-layer visual knowledge enhanced MLLMs method, called JiuTian-LION. The specific method framework is shown in Figure 3
This method mainly enhances MLLMs from two aspects, progressively integrating fine-grained Spatial-aware Visual knowledge (Progressive Incorporation of Fine-grained Spatial-aware Visual knowledge) and Soft Prompting of High-level Semantic Visual Evidence under soft prompts.
Specifically, the researchers proposed a segmented instruction fine-tuning strategy to resolve the internal conflict between the image-level understanding task and the region-level localization task. They gradually inject fine-grained spatial awareness knowledge into MLLMs. At the same time, they added image labels as high-level semantic visual evidence to MLLMs, and used soft hinting methods to mitigate the possible negative impact of incorrect labels
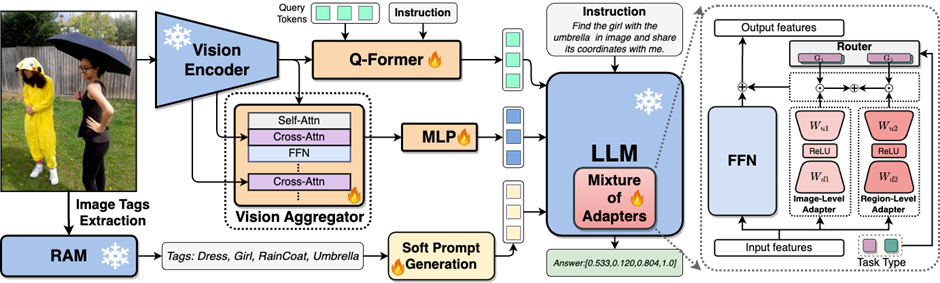
This work uses a segmented training strategy to first learn image-level understanding and regional-level positioning tasks based on Q-Former and Vision Aggregator-MLP branches respectively, and then utilizes a hybrid adapter with a routing mechanism in the final training stage. To dynamically integrate the performance of different branches of knowledge improvement models on two tasks. This work also extracts image tags as high-level semantic visual evidence through RAM, and then proposes a soft prompt method to improve the effect of high-level semantic injection Progressive fusion of fine-grained spatial awareness visual knowledge When directly combining image-level understanding tasks (including image description and visual question answering) with regional-level localization tasks (including instructions Expression understanding, instruction expression generation, etc.) When performing single-stage hybrid training, MLLMs will encounter internal conflicts between the two tasks and thus cannot achieve good overall performance on all tasks. Researchers believe that this internal conflict is mainly caused by two issues. The first problem is the lack of regional-level modal alignment pre-training. Currently, most MLLMs with regional-level positioning capabilities first use a large amount of relevant data for pre-training. Otherwise, it will be difficult to use image-level modal alignment based on limited training resources. Visual feature adaptation to region-level tasks. Another problem is the difference in input and output patterns between image-level understanding tasks and region-level localization tasks. The latter requires the model to additionally understand specific short sentences about object coordinates (started with As shown in Figure 4, the researchers split the single-stage instruction fine-tuning process into three stages: Using ViT, Q-Former and image-level adapters to learn image-level understanding tasks of global visual knowledge; use Vision Aggregator, MLP, and regional-level adapters to learn regional-level positioning tasks of fine-grained space-aware visual knowledge; propose a hybrid adapter with a routing mechanism to dynamically integrate different branches Visual knowledge learned at different granularities. Table 3 shows the performance advantages of the segmented instruction fine-tuning strategy over single-stage training Figure 4: Segmented instruction fine-tuning strategy For high-level semantic visual evidence injected under soft prompts, rewriting is required Researchers propose using image labels as an effective supplement to high-level semantic visual evidence to further enhance the global visual perception understanding ability of MLLMs Specific For example, first extract the image tag through RAM, and then use the specific command template "According to Coupled with the specific phrase "use or partially use" in the template, the soft hint vector can guide the model to mitigate the potential negative impact of incorrect labels. The researchers included image captioning (image captioning), visual question answering (VQA), and directed expression understanding (REC) It was evaluated on 17 task benchmark sets. The experimental results show that Jiutian has reached the international leading level in 13 evaluation sets. In particular, compared with InstructBLIP and Shikra, Jiutian has achieved comprehensive and consistent performance improvements in image-level understanding tasks and region-level positioning tasks respectively, and can achieve up to 5% improvement in Visual Spatial Reasoning (VSR) tasks. As can be seen from Figure 5, there are differences in the abilities of Jiutian and other MLLMs in different visual language multi-modal tasks, indicating that Jiutian performs better in fine-grained visual understanding and visuospatial reasoning capabilities. And be able to output text responses with less illusion The rewritten content is: The fifth picture shows the response to the Nine-day Large Model, InstructBLIP and Qualitative analysis of Shikra’s ability differences Figure 6 shows through sample analysis that the Jiutian model has excellent understanding and recognition capabilities in both image-level and regional-level visual language tasks. The sixth picture: Through the analysis of more examples, the capabilities of the Jiutian large model are demonstrated from the perspective of image and regional level visual understanding (1) This work proposes a new multi-modal large language model-Jiutian: enhanced by double-layer visual knowledge Multimodal large language model. (2) This work was evaluated on 17 visual language task benchmark sets including image description, visual question answering and instructional expression understanding, among which 13 evaluation sets reached the current best performance. (3) This work proposes a segmented instruction fine-tuning strategy to resolve the internal conflict between image-level understanding and region-level localization tasks, and implements two Mutual improvement between tasks (4) This work successfully integrates image-level understanding and regional-level positioning tasks to comprehensively understand visual scenes at multiple levels. This comprehensive approach can be used in the future. Visual understanding capabilities are applied to embodied intelligent scenarios to help robots better and more comprehensively identify and understand the current environment and make effective decisions. 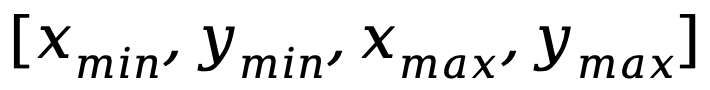 form). In order to solve the above problems, researchers proposed a segmented instruction fine-tuning strategy and a hybrid adapter with a routing mechanism.
form). In order to solve the above problems, researchers proposed a segmented instruction fine-tuning strategy and a hybrid adapter with a routing mechanism. 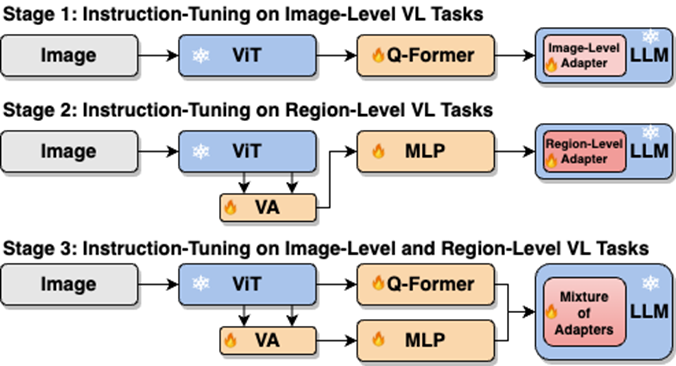
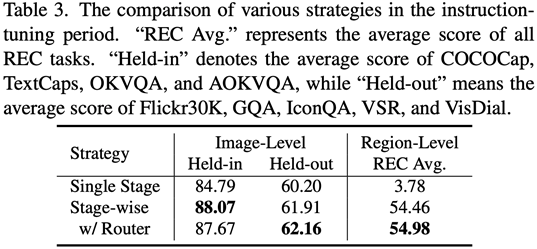
Experimental results
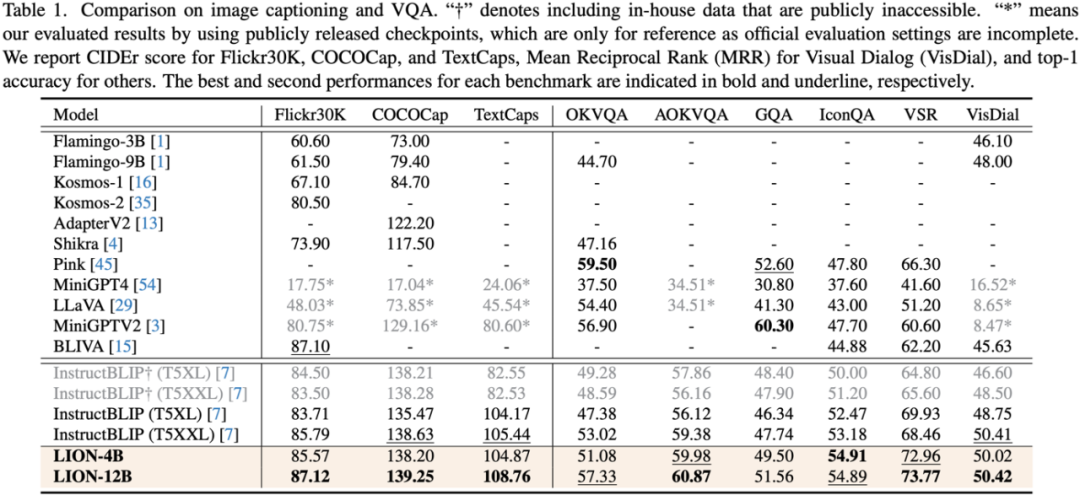
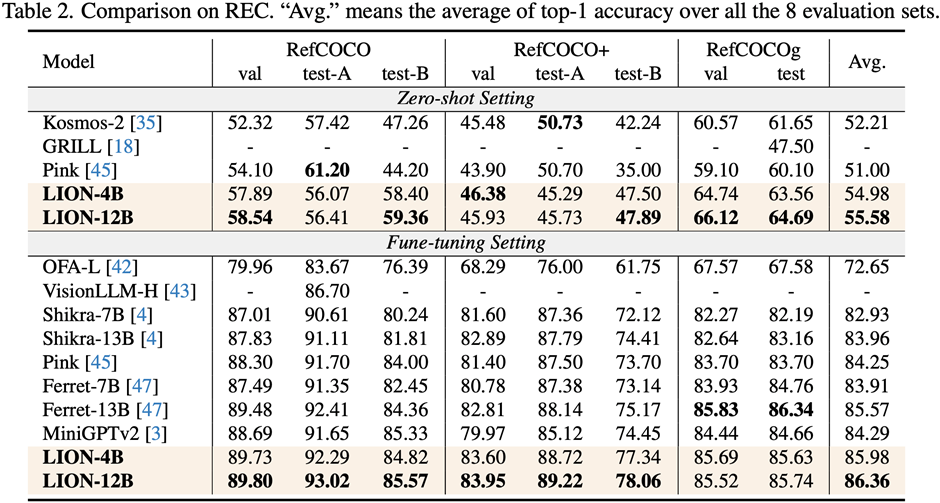


Summary
The above is the detailed content of Complete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Top 10 latest releases of virtual currency trading platforms for bulk transactions
Apr 22, 2025 am 08:18 AM
Top 10 latest releases of virtual currency trading platforms for bulk transactions
Apr 22, 2025 am 08:18 AM
The following factors should be considered when choosing a bulk trading platform: 1. Liquidity: Priority is given to platforms with an average daily trading volume of more than US$5 billion. 2. Compliance: Check whether the platform holds licenses such as FinCEN in the United States, MiCA in the European Union. 3. Security: Cold wallet storage ratio and insurance mechanism are key indicators. 4. Service capability: Whether to provide exclusive account managers and customized transaction tools.
 Summary of the top ten Apple version download portals for digital currency exchange apps
Apr 22, 2025 am 09:27 AM
Summary of the top ten Apple version download portals for digital currency exchange apps
Apr 22, 2025 am 09:27 AM
Provides a variety of complex trading tools and market analysis. It covers more than 100 countries, has an average daily derivative trading volume of over US$30 billion, supports more than 300 trading pairs and 200 times leverage, has strong technical strength, a huge global user base, provides professional trading platforms, secure storage solutions and rich trading pairs.
 What are the top ten virtual currency trading apps? Recommended on the top ten digital currency exchange platforms
Apr 22, 2025 pm 01:12 PM
What are the top ten virtual currency trading apps? Recommended on the top ten digital currency exchange platforms
Apr 22, 2025 pm 01:12 PM
The top ten secure digital currency exchanges in 2025 are: 1. Binance, 2. OKX, 3. gate.io, 4. Coinbase, 5. Kraken, 6. Huobi, 7. Bitfinex, 8. KuCoin, 9. Bybit, 10. Bitstamp. These platforms adopt multi-level security measures, including separation of hot and cold wallets, multi-signature technology, and a 24/7 monitoring system to ensure the safety of user funds.
 What are the stablecoins? How to trade stablecoins?
Apr 22, 2025 am 10:12 AM
What are the stablecoins? How to trade stablecoins?
Apr 22, 2025 am 10:12 AM
Common stablecoins are: 1. Tether, issued by Tether, pegged to the US dollar, widely used but transparency has been questioned; 2. US dollar, issued by Circle and Coinbase, with high transparency and favored by institutions; 3. DAI, issued by MakerDAO, decentralized, and popular in the DeFi field; 4. Binance Dollar (BUSD), cooperated by Binance and Paxos, and performed excellent in transactions and payments; 5. TrustTo
 How many stablecoin exchanges are there now? How many types of stablecoins are there?
Apr 22, 2025 am 10:09 AM
How many stablecoin exchanges are there now? How many types of stablecoins are there?
Apr 22, 2025 am 10:09 AM
As of 2025, the number of stablecoin exchanges is about 1,000. 1. Stable coins supported by fiat currencies include USDT, USDC, etc. 2. Cryptocurrency-backed stablecoins such as DAI and sUSD. 3. Algorithm stablecoins such as TerraUSD. 4. There are also hybrid stablecoins.
 Which of the top ten transactions in the currency circle? The latest currency circle app recommendations
Apr 24, 2025 am 11:57 AM
Which of the top ten transactions in the currency circle? The latest currency circle app recommendations
Apr 24, 2025 am 11:57 AM
Choosing a reliable exchange is crucial. The top ten exchanges such as Binance, OKX, and Gate.io have their own characteristics. New apps such as CoinGecko and Crypto.com are also worth paying attention to.
 What are the next thousand-fold coins in 2025?
Apr 24, 2025 pm 01:45 PM
What are the next thousand-fold coins in 2025?
Apr 24, 2025 pm 01:45 PM
As of April 2025, seven cryptocurrency projects are considered to have significant growth potential: 1. Filecoin (FIL) achieves rapid development through distributed storage networks; 2. Aptos (APT) attracts DApp developers with high-performance Layer 1 public chains; 3. Polygon (MATIC) improves Ethereum network performance; 4. Chainlink (LINK) serves as a decentralized oracle network to meet smart contract needs; 5. Avalanche (AVAX) trades quickly and
 What is DLC currency? What is the prospect of DLC currency
Apr 24, 2025 pm 12:03 PM
What is DLC currency? What is the prospect of DLC currency
Apr 24, 2025 pm 12:03 PM
DLC coins are blockchain-based cryptocurrencies that aim to provide an efficient and secure trading platform, support smart contracts and cross-chain technologies, and are suitable for the financial and payment fields.
