
 Technology peripherals
AI
Implement Python code to enhance retrieval capabilities for large models
Technology peripherals
AI
Implement Python code to enhance retrieval capabilities for large models
Implement Python code to enhance retrieval capabilities for large models

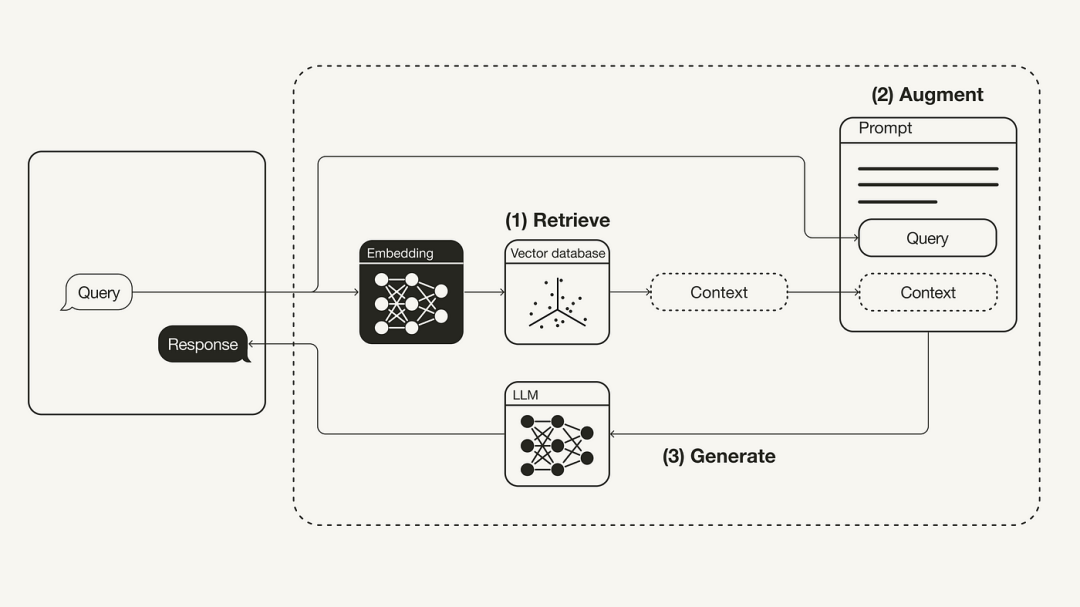
The primary focus of this article is the concept and theory of RAG. Next, we will show how to use LangChain, OpenAI language model and Weaviate vector database to implement a simple RAG orchestration system
What is retrieval enhancement generation?
The concept of Retrieval Augmented Generation (RAG) refers to providing additional information to LLM through external knowledge sources. This allows LLM to generate more accurate and contextual answers while reducing hallucinations.
When rewriting the content, the original text needs to be rewritten into Chinese without the original sentence
##Currently The best LLMs are trained using large amounts of data, so a large amount of general knowledge (parameter memory) is stored in their neural network weights. However, if the prompt requires LLM to generate results that require knowledge other than its training data (such as new information, proprietary data, or domain-specific information), factual inaccuracies may occur. When rewriting the content, you need to The original text was rewritten into Chinese without the original sentence (illusion), as shown in the screenshot below:
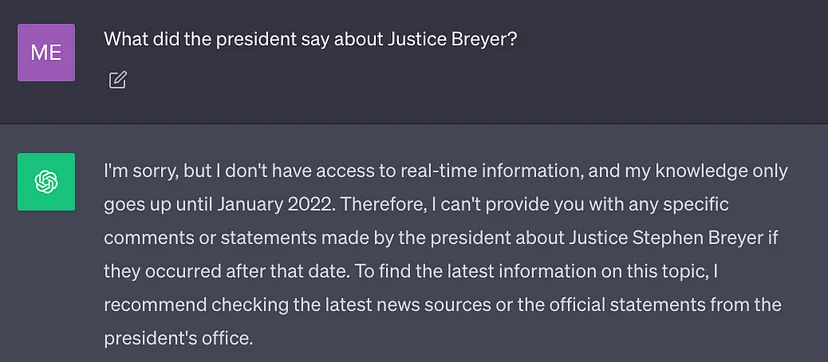
Therefore, it is important is to combine general knowledge of LLM with additional context in order to produce more accurate and contextual results with fewer hallucinations
Solution
Traditionally, we can fine-tune a model to adapt a neural network to a specific domain or proprietary information. Although this technology is effective, it requires extensive computing resources, is expensive, and requires the support of technical experts, making it difficult to quickly adapt to changing information
2020, Lewis et al.'s paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" proposes a more flexible technology: Retrieval Augmented Generation (RAG). In this paper, the researchers combined the generative model with a retrieval module that can provide additional information using an external knowledge source that is more easily updated.
To put it in vernacular: RAG is to LLM what open book examination is to humans. For open-book exams, students can bring reference materials such as textbooks and notes where they can find relevant information to answer the questions. The idea behind open-book exams is that the exam focuses on students' ability to reason rather than their ability to memorize specific information.
Similarly, factual knowledge is distinct from LLM reasoning capabilities and can be stored in external knowledge sources that are easily accessible and updated
- Parameterized knowledge: The knowledge learned during training is implicitly stored in the neural network weights.
- Non-parametric knowledge: stored in external knowledge sources, such as vector databases.
The following diagram shows the most basic RAG workflow:
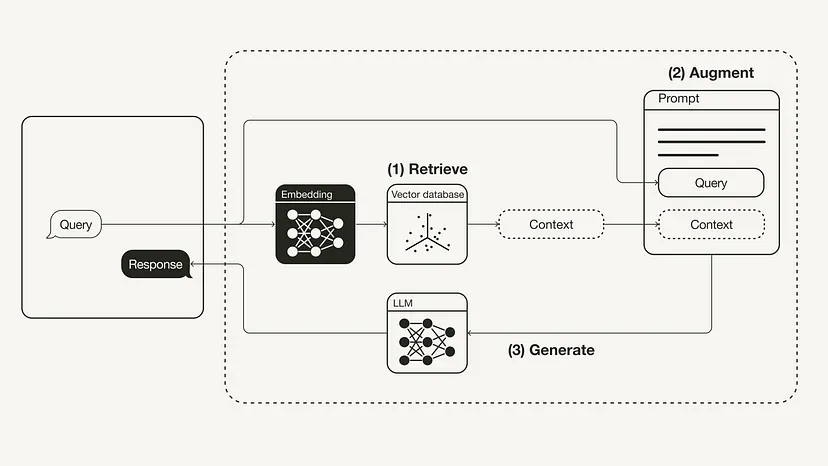
Rewritten Content: Workflow for Reconstructing Retrieval Augmented Generation (RAG)
- # Retrieval: Use user queries to retrieve relevant context from external knowledge sources. To do this, an embedding model is used to embed the user query into the same vector space as additional context in the vector database. This allows you to perform a similarity search and return the k data objects in this vector database that are closest to the user query.
- Enhancement: The user query and retrieved additional context are then populated into a prompt template.
- Generation: Finally, the retrieval-enhanced prompt is fed to LLM.
Use LangChain to implement retrieval enhancement generation
The following will introduce how to implement the RAG workflow through Python, which will use OpenAI LLM As well as the Weaviate vector database and an OpenAI embedding model. The role of LangChain is orchestration.
Please rephrase: Required prerequisites
Please make sure you have the required Python packages installed:
- langchain, orchestration
- openai, embedded model and LLM
- ##weaviate-client, vector database
#!pip install langchain openai weaviate-client
In addition, use an .env file in the root directory to define relevant environment variables. You need an OpenAI account to obtain the OpenAI API Key, and then "Create a new key" in API keys (https://platform.openai.com/account/api-keys).
OPENAI_API_KEY="<your_openai_api_key>"</your_openai_api_key>
Then, run the following command to load the relevant environment variables.
import dotenvdotenv.load_dotenv()
Preparation work
#In the preparation phase, you need to prepare a vector database as an external knowledge source, using to save all additional information. The construction of this vector database includes the following steps:
- Collect and load data
- Cut the document into chunks
- Embed the text block and save
Rewritten content: First, we need to collect and load data. As an example, if we wanted to use President Biden’s 2022 State of the Union address as additional context, LangChain’s GitHub repository provides the original text document of the file. In order to load this data, we can take advantage of LangChain's various built-in document loading tools. A document is a dictionary composed of text and metadata. To load text, you can use LangChain’s TextLoader tool
Original document address: https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/ state_of_the_union.txt
import requestsfrom langchain.document_loaders import TextLoaderurl = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"res = requests.get(url)with open("state_of_the_union.txt", "w") as f:f.write(res.text)loader = TextLoader('./state_of_the_union.txt')documents = loader.load()Next, break the document into chunks. Because the original state of the document is too long to fit into LLM's context window, it needs to be split into smaller chunks of text. LangChain also has many built-in splitting tools. For this simple example, we can use a CharacterTextSplitter with chunk_size set to 500 and chunk_overlap set to 50, which maintains text continuity between text chunks.
from langchain.text_splitter import CharacterTextSplittertext_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)chunks = text_splitter.split_documents(documents)
Finally, embed the text block and save it. In order for semantic search to be performed across text blocks, vector embeddings need to be generated for each text block and saved together with their embeddings. To generate vector embeddings, use the OpenAI embedding model; for storage, use the Weaviate vector database. Blocks of text can be automatically populated into a vector database by calling .from_documents().
from langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Weaviateimport weaviatefrom weaviate.embedded import EmbeddedOptionsclient = weaviate.Client(embedded_options = EmbeddedOptions())vectorstore = Weaviate.from_documents(client = client,documents = chunks,embedding = OpenAIEmbeddings(),by_text = False)
Step 1: Retrieve
After filling the vector database, we can It is defined as a retriever component that can obtain additional context based on the semantic similarity between the user query and the embedded block
retriever = vectorstore.as_retriever()
Step 2: Enhance
from langchain.prompts import ChatPromptTemplatetemplate = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.Question: {question} Context: {context} Answer:"""prompt = ChatPromptTemplate.from_template(template)print(prompt)Next, in order to enhance the prompt with additional context, you need to prepare a prompt template. As shown below, prompt can be easily customized using prompt template.
Step 3: Generate
Finally, we can build a Thought chain, linking the retriever, prompt template and LLM together. Once the RAG chain is defined, it can be called
from langchain.chat_models import ChatOpenAIfrom langchain.schema.runnable import RunnablePassthroughfrom langchain.schema.output_parser import StrOutputParserllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)rag_chain = ({"context": retriever,"question": RunnablePassthrough()} | prompt | llm| StrOutputParser() )query = "What did the president say about Justice Breyer"rag_chain.invoke(query)"The president thanked Justice Breyer for his service and acknowledged his dedication to serving the country. The president also mentioned that he nominated Judge Ketanji Brown Jackson as a successor to continue Justice Breyer's legacy of excellence."The following figure shows the RAG process for this specific example:
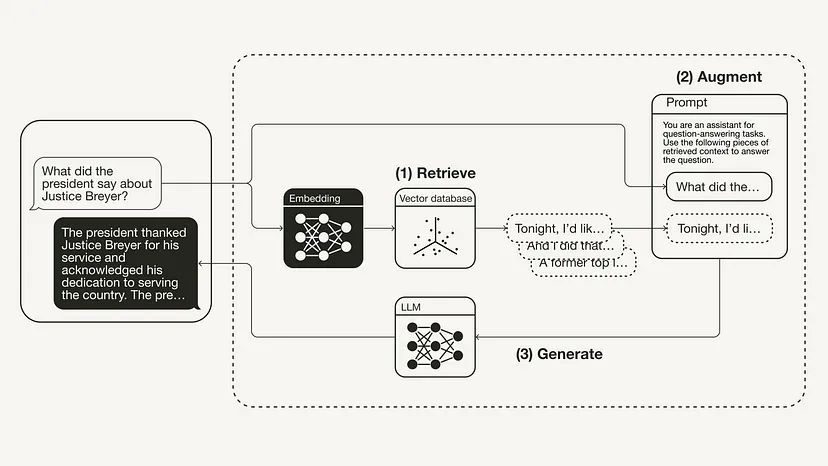
#Summary
This article introduces the concept of RAG, which first came from the 2020 paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" . After introducing the theory behind RAG, including motivation and solutions, this article shows how to implement it in Python. This article shows how to implement a RAG workflow using OpenAI LLM coupled with the Weaviate vector database and OpenAI embedding model. The role of LangChain is orchestration.
The above is the detailed content of Implement Python code to enhance retrieval capabilities for large models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1318
25
1269
29
1248
24
14
1423
52
1318
25
1269
29
1248
24

 How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
DMA in C refers to DirectMemoryAccess, a direct memory access technology, allowing hardware devices to directly transmit data to memory without CPU intervention. 1) DMA operation is highly dependent on hardware devices and drivers, and the implementation method varies from system to system. 2) Direct access to memory may bring security risks, and the correctness and security of the code must be ensured. 3) DMA can improve performance, but improper use may lead to degradation of system performance. Through practice and learning, we can master the skills of using DMA and maximize its effectiveness in scenarios such as high-speed data transmission and real-time signal processing.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
The built-in quantization tools on the exchange include: 1. Binance: Provides Binance Futures quantitative module, low handling fees, and supports AI-assisted transactions. 2. OKX (Ouyi): Supports multi-account management and intelligent order routing, and provides institutional-level risk control. The independent quantitative strategy platforms include: 3. 3Commas: drag-and-drop strategy generator, suitable for multi-platform hedging arbitrage. 4. Quadency: Professional-level algorithm strategy library, supporting customized risk thresholds. 5. Pionex: Built-in 16 preset strategy, low transaction fee. Vertical domain tools include: 6. Cryptohopper: cloud-based quantitative platform, supporting 150 technical indicators. 7. Bitsgap:
 How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
Handling high DPI display in C can be achieved through the following steps: 1) Understand DPI and scaling, use the operating system API to obtain DPI information and adjust the graphics output; 2) Handle cross-platform compatibility, use cross-platform graphics libraries such as SDL or Qt; 3) Perform performance optimization, improve performance through cache, hardware acceleration, and dynamic adjustment of the details level; 4) Solve common problems, such as blurred text and interface elements are too small, and solve by correctly applying DPI scaling.
 What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
C performs well in real-time operating system (RTOS) programming, providing efficient execution efficiency and precise time management. 1) C Meet the needs of RTOS through direct operation of hardware resources and efficient memory management. 2) Using object-oriented features, C can design a flexible task scheduling system. 3) C supports efficient interrupt processing, but dynamic memory allocation and exception processing must be avoided to ensure real-time. 4) Template programming and inline functions help in performance optimization. 5) In practical applications, C can be used to implement an efficient logging system.
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
 Steps to add and delete fields to MySQL tables
Apr 29, 2025 pm 04:15 PM
Steps to add and delete fields to MySQL tables
Apr 29, 2025 pm 04:15 PM
In MySQL, add fields using ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column, delete fields using ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop. When adding fields, you need to specify a location to optimize query performance and data structure; before deleting fields, you need to confirm that the operation is irreversible; modifying table structure using online DDL, backup data, test environment, and low-load time periods is performance optimization and best practice.
 How to use string streams in C?
Apr 28, 2025 pm 09:12 PM
How to use string streams in C?
Apr 28, 2025 pm 09:12 PM
The main steps and precautions for using string streams in C are as follows: 1. Create an output string stream and convert data, such as converting integers into strings. 2. Apply to serialization of complex data structures, such as converting vector into strings. 3. Pay attention to performance issues and avoid frequent use of string streams when processing large amounts of data. You can consider using the append method of std::string. 4. Pay attention to memory management and avoid frequent creation and destruction of string stream objects. You can reuse or use std::stringstream.
