
 Technology peripherals
AI
A new step towards high-quality image generation: Google's UFOGen ultra-fast sampling method
Technology peripherals
AI
A new step towards high-quality image generation: Google's UFOGen ultra-fast sampling method
A new step towards high-quality image generation: Google's UFOGen ultra-fast sampling method

In the past year, a series of Vincentian graph diffusion models represented by Stable Diffusion have completely changed the field of visual creation. Countless users have improved their productivity with images produced by diffusion models. However, the speed of generation of diffusion models is a common problem. Because the denoising model relies on multi-step denoising to gradually turn the initial Gaussian noise into an image, it requires multiple calculations of the network, resulting in a very slow generation speed. This makes the large-scale Vincentian graph diffusion model very unfriendly to some applications that focus on real-time and interactivity. With the introduction of a series of technologies, the number of steps required to sample from a diffusion model has increased from the initial few hundred steps to dozens of steps, or even only 4-8 steps.
Recently, a research team from Google proposed the UFOGen model, a variant of the diffusion model that can sample extremely quickly. By fine-tuning Stable Diffusion with the method proposed in the paper, UFOGen can generate high-quality images in just one step. At the same time, Stable Diffusion's downstream applications, such as graph generation and ControlNet, can also be retained.

Please click the following link to view the paper: https://arxiv.org/abs/2311.09257
As you can see from the picture below, UFOGen can generate high-quality, diverse pictures in just one step.

Improving the generation speed of diffusion models is not a new research direction. Previous research in this area mainly focused on two directions. One direction is to design more efficient numerical calculation methods, so as to achieve the purpose of solving the sampling ODE of the diffusion model using fewer discrete steps. For example, the DPM series of numerical solvers proposed by Zhu Jun's team at Tsinghua University have been verified to be very effective in Stable Diffusion, and can significantly reduce the number of solution steps from the default 50 steps of DDIM to less than 20 steps. Another direction is to use the knowledge distillation method to compress the ODE-based sampling path of the model to a smaller number of steps. Examples in this direction are Guided distillation, one of the best paper candidates of CVPR2023, and the recently popular Latent Consistency Model (LCM). LCM, in particular, can reduce the number of sampling steps to only 4 by distilling the consistency target, which has spawned many real-time generation applications.
However, Google’s research team did not follow the above general direction in the UFOGen model. Instead, it took a different approach and used a mixture of the diffusion model and GAN proposed more than a year ago. Model ideas. They believe that the aforementioned ODE-based sampling and distillation has its fundamental limitations, and it is difficult to compress the number of sampling steps to the limit. Therefore, if you want to achieve the goal of one-step generation, you need to open up new ideas.
Hybrid model refers to a method that combines a diffusion model and a generative adversarial network (GAN). This method was first proposed by NVIDIA's research team at ICLR 2022 and is called DDGAN ("Using Denoising Diffusion GAN to Solve Three Problems in Generative Learning"). DDGAN is inspired by the shortcomings of ordinary diffusion models that make Gaussian assumptions about noise reduction distributions. Simply put, the diffusion model assumes that the denoising distribution (a conditional distribution that, given a noisy sample, generates a less noisy sample) is a simple Gaussian distribution. However, the theory of stochastic differential equations proves that such an assumption only holds true when the noise reduction step size approaches 0. Therefore, the diffusion model requires a large number of repeated denoising steps to ensure a small denoising step size, resulting in a slower generation speed.
DDGAN proposes to abandon the Gaussian assumption of the denoising distribution and instead Use a conditional GAN to simulate this noise reduction distribution. Because GAN has extremely strong representation capabilities and can simulate complex distributions, a larger noise reduction step size can be used to reduce the number of steps. However, DDGAN changes the stable reconstruction training goal of the diffusion model into the training goal of GAN, which can easily cause training instability and make it difficult to extend to more complex tasks. At NeurIPS 2023, the same Google research team that created UGOGen proposed SIDDM (paper title Semi-Implicit Denoising Diffusion Models), reintroducing the reconstruction objective function into the training objective of DDGAN, making training more stable and The generation quality is greatly improved compared to DDGAN.
SIDDM, as the predecessor of UFOGen, can generate high-quality images on CIFAR-10, ImageNet and other research data sets in only 4 steps. But SIDDM has two problems that need to be solved: first, it cannot achieve one-step generation of ideal conditions; second, it is not simple to extend it to the field of Vincentian graphs that attract more attention. To this end, Google’s research team proposed UFOGen to solve these two problems.
Specifically, for question one, through simple mathematical analysis, the team found that by changing the parameterization method of the generator and changing the calculation method of the reconstruction loss function, the theory The above model can be generated in one step. For question two, the team proposed to use the existing Stable Diffusion model for initialization to allow the UFOGen model to be expanded to Vincent diagram tasks faster and better. It is worth noting that SIDDM has proposed that both the generator and the discriminator adopt the UNet architecture. Therefore, based on this design, the generator and discriminator of UFOGen are initialized by the Stable Diffusion model. Doing so makes the most of Stable Diffusion's internal information, especially about the relationship between images and text. Such information is difficult to obtain through adversarial learning. The training algorithm and diagram are shown below.

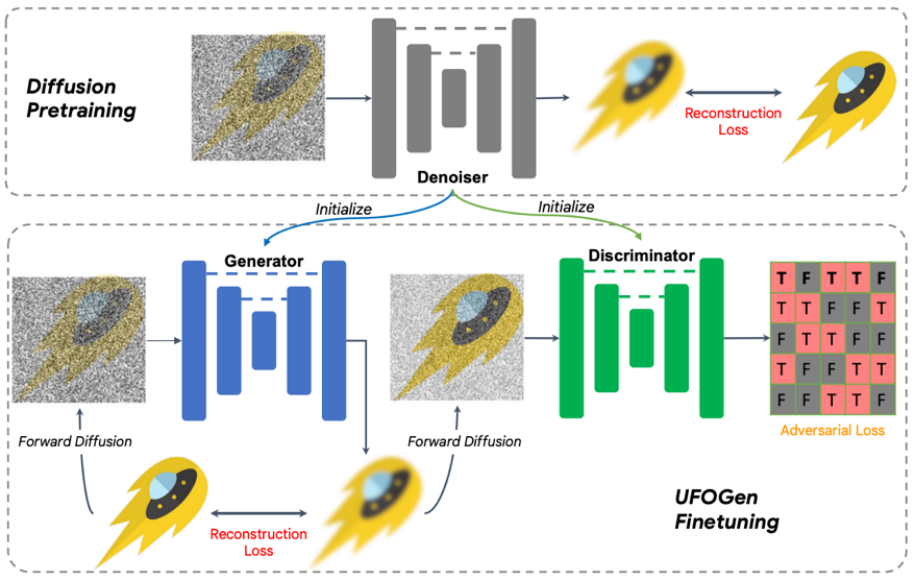
It is worth noting that before this, there was some work using GAN to do Vincentian graphs, such as NVIDIA StyleGAN-T and Adobe's GigaGAN both extend the basic architecture of StyleGAN to a larger scale, allowing them to generate graphs in one step. The author of UFOGen pointed out that compared with previous GAN-based work, in addition to generation quality, UFOGen has several advantages:
Rewritten content: 1. In the Vincentian graph task , pure generative adversarial network (GAN) training is very unstable. The discriminator not only needs to judge the texture of the image, but also needs to understand the degree of match between the image and the text, which is a very difficult task, especially in the early stages of training. Therefore, previous GAN models, such as GigaGAN, introduced a large number of auxiliary losses to help training, which made training and parameter adjustment extremely difficult. However, UFOGen makes GAN play a supporting role in this regard by introducing reconstruction loss, thereby achieving very stable training
2. Training GAN directly from scratch is not only unstable but also abnormal Expensive, especially for tasks like Vincent plots that require large amounts of data and training steps. Because two sets of parameters need to be updated at the same time, the training of GAN consumes more time and memory than the diffusion model. UFOGen's innovative design can initialize parameters from Stable Diffusion, greatly saving training time. Usually convergence only requires tens of thousands of training steps.
3. One of the charms of the Vincent graph diffusion model is that it can be applied to other tasks, including applications that do not require fine-tuning such as graph graphs, and applications that already require fine-tuning such as controlled generation. Previous GAN models have been difficult to scale to these downstream tasks because fine-tuning GANs has been difficult. In contrast, UFOGen has the framework of a diffusion model and therefore can be more easily applied to these tasks. The figure below shows UFOGen's graph generation graph and examples of controllable generation. Note that these generation only require one step of sampling.

Experiments have shown that UFOGen only needs one step of sampling to generate high-quality images that conform to text descriptions. Compared with recently proposed high-speed sampling methods for diffusion models (such as Instaflow and LCM), UFOGen shows strong competitiveness. Even compared to Stable Diffusion, which requires 50 steps of sampling, the samples generated by UFOGen are not inferior in appearance. Here are some comparison results:

Summary
The Google team proposed a method called UFOGen Powerful model, achieved by improving the existing diffusion model and a hybrid model of GAN. This model is fine-tuned by Stable Diffusion, and while ensuring the ability to generate graphs in one step, it is also suitable for different downstream applications. As one of the early works to achieve ultra-fast text-to-image synthesis, UFOGen has opened up a new path in the field of high-efficiency generative models
The above is the detailed content of A new step towards high-quality image generation: Google's UFOGen ultra-fast sampling method. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1422
52
1316
25
1268
29
1241
24
14
1422
52
1316
25
1268
29
1241
24

 How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
DMA in C refers to DirectMemoryAccess, a direct memory access technology, allowing hardware devices to directly transmit data to memory without CPU intervention. 1) DMA operation is highly dependent on hardware devices and drivers, and the implementation method varies from system to system. 2) Direct access to memory may bring security risks, and the correctness and security of the code must be ensured. 3) DMA can improve performance, but improper use may lead to degradation of system performance. Through practice and learning, we can master the skills of using DMA and maximize its effectiveness in scenarios such as high-speed data transmission and real-time signal processing.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
The built-in quantization tools on the exchange include: 1. Binance: Provides Binance Futures quantitative module, low handling fees, and supports AI-assisted transactions. 2. OKX (Ouyi): Supports multi-account management and intelligent order routing, and provides institutional-level risk control. The independent quantitative strategy platforms include: 3. 3Commas: drag-and-drop strategy generator, suitable for multi-platform hedging arbitrage. 4. Quadency: Professional-level algorithm strategy library, supporting customized risk thresholds. 5. Pionex: Built-in 16 preset strategy, low transaction fee. Vertical domain tools include: 6. Cryptohopper: cloud-based quantitative platform, supporting 150 technical indicators. 7. Bitsgap:
 How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
Handling high DPI display in C can be achieved through the following steps: 1) Understand DPI and scaling, use the operating system API to obtain DPI information and adjust the graphics output; 2) Handle cross-platform compatibility, use cross-platform graphics libraries such as SDL or Qt; 3) Perform performance optimization, improve performance through cache, hardware acceleration, and dynamic adjustment of the details level; 4) Solve common problems, such as blurred text and interface elements are too small, and solve by correctly applying DPI scaling.
 What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
C performs well in real-time operating system (RTOS) programming, providing efficient execution efficiency and precise time management. 1) C Meet the needs of RTOS through direct operation of hardware resources and efficient memory management. 2) Using object-oriented features, C can design a flexible task scheduling system. 3) C supports efficient interrupt processing, but dynamic memory allocation and exception processing must be avoided to ensure real-time. 4) Template programming and inline functions help in performance optimization. 5) In practical applications, C can be used to implement an efficient logging system.
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
 An efficient way to batch insert data in MySQL
Apr 29, 2025 pm 04:18 PM
An efficient way to batch insert data in MySQL
Apr 29, 2025 pm 04:18 PM
Efficient methods for batch inserting data in MySQL include: 1. Using INSERTINTO...VALUES syntax, 2. Using LOADDATAINFILE command, 3. Using transaction processing, 4. Adjust batch size, 5. Disable indexing, 6. Using INSERTIGNORE or INSERT...ONDUPLICATEKEYUPDATE, these methods can significantly improve database operation efficiency.
 How to use string streams in C?
Apr 28, 2025 pm 09:12 PM
How to use string streams in C?
Apr 28, 2025 pm 09:12 PM
The main steps and precautions for using string streams in C are as follows: 1. Create an output string stream and convert data, such as converting integers into strings. 2. Apply to serialization of complex data structures, such as converting vector into strings. 3. Pay attention to performance issues and avoid frequent use of string streams when processing large amounts of data. You can consider using the append method of std::string. 4. Pay attention to memory management and avoid frequent creation and destruction of string stream objects. You can reuse or use std::stringstream.
