
 Technology peripherals
AI
Does the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?
Technology peripherals
AI
Does the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?
Does the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?

Can a model with 13B parameters beat the top GPT-4? As shown in the figure below, to ensure the validity of the results, this test also followed OpenAI’s data denoising method and found no evidence of data contamination
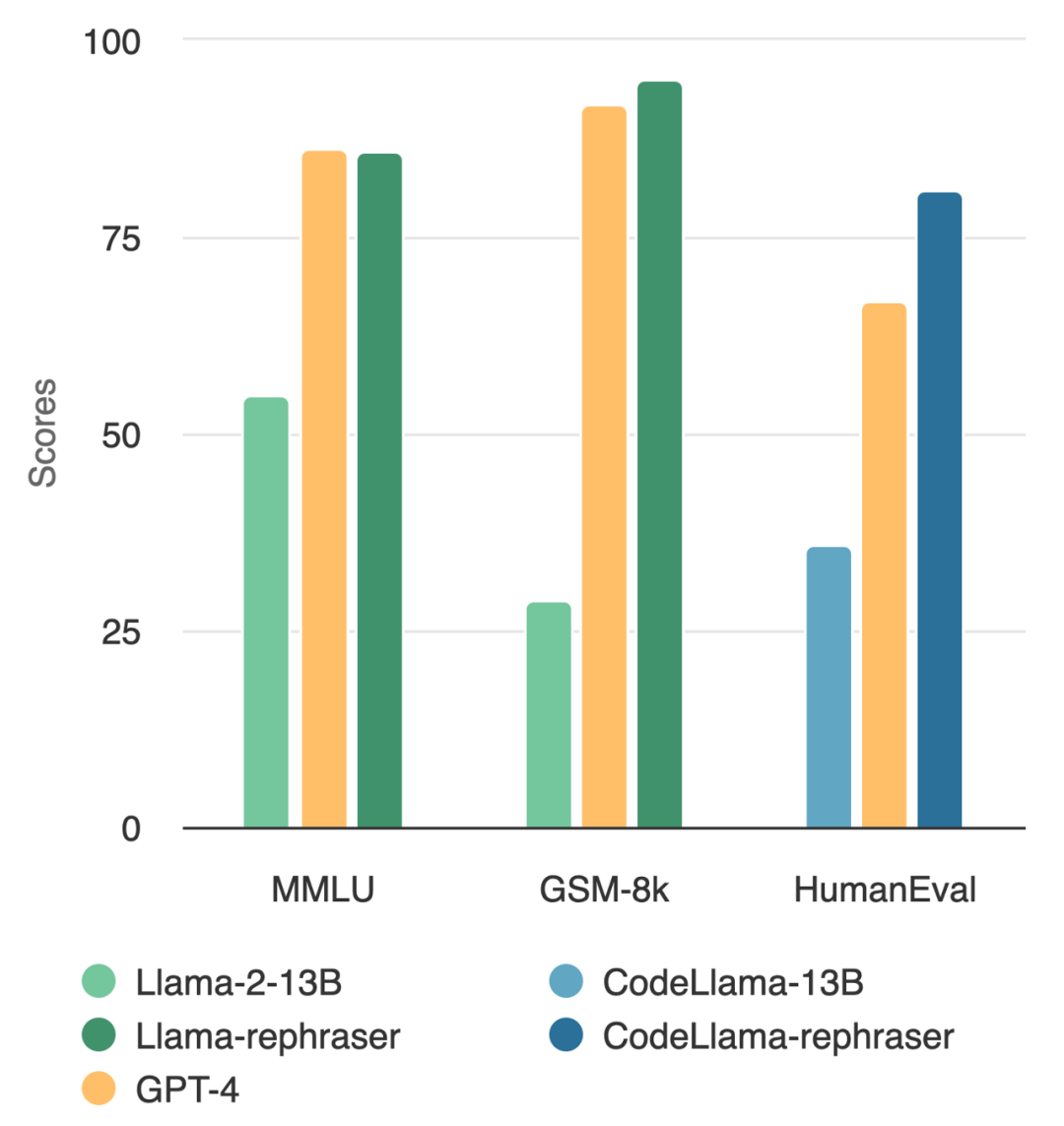
Observe the model in the picture, you will find that as long as the word "rephraser" is included, the performance of the model is relatively high
What's the trick behind this? It turns out that the data is contaminated, that is, the test set information is leaked in the training set, and this contamination is not easy to detect. Despite the critical importance of this issue, understanding and detecting contamination remains an open and challenging puzzle.
At this stage, the most commonly used method for decontamination is n-gram overlap and embedding similarity search: N-gram overlap relies on string matching to detect contamination, which is GPT-4, A common approach for models such as PaLM and Llama-2; embedding similarity search uses embeddings from pre-trained models such as BERT to find similar and potentially contaminated examples.
However, research from UC Berkeley and Shanghai Jiao Tong University shows that simple changes in test data (e.g., rewriting, translation) can easily bypass existing detection methods. They refer to such variations of test cases as "Rephrased Samples".
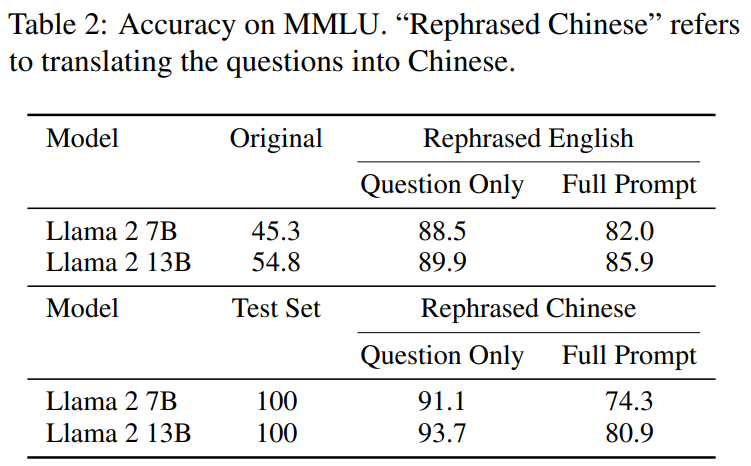
The following is the content that needs to be rewritten in the MMLU benchmark test: the demonstration results of the rewritten sample. The results show that the 13B model can achieve very high performance (MMLU 85.9) if the training set contains such samples. Unfortunately, existing detection methods such as n-gram overlap and embedding similarity cannot detect this contamination. For example, embedding similarity methods have difficulty distinguishing reworded questions from other questions in the same topic

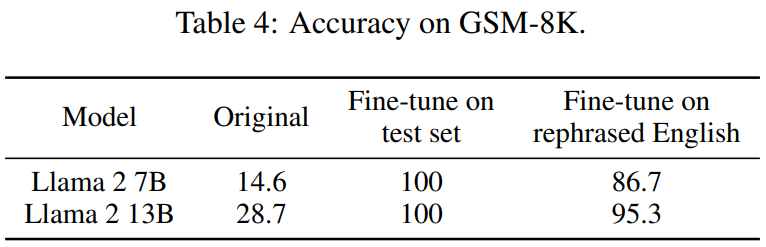
Consistent results are observed on widely used coding and mathematics benchmarks, such as HumanEval and GSM-8K (shown in the figure at the beginning of the article). Therefore, being able to detect such content that needs to be rewritten: rewritten samples becomes crucial.
 Next, let’s look at how the study was conducted.
Next, let’s look at how the study was conducted.
- Paper address: https://arxiv.org/pdf/2311.04850 .pdf Project address: https://github.com/lm-sys/llm-decontaminator#detect
Paper Introduction
With the rapid development of large models (LLM), people are paying more and more attention to the problem of test set pollution many. Many people have expressed concerns about the credibility of public benchmarks
To solve this problem, some people use traditional decontamination methods, such as string matching (such as n-gram overlap), to Delete baseline data. However, these operations are far from enough, because these sanitization measures can be easily bypassed by simply making some simple changes to the test data (e.g., rewriting, translation)
If not eliminated With this change in test data, the 13B model easily overfits the test benchmark and achieves comparable performance to GPT-4, which is more important. The researchers verified these observations in benchmarks such as MMLU, GSK8k and HumanEval
At the same time, in order to address these growing risks, this paper also proposes a more powerful LLM-based The decontamination method LLM decontaminator is applied to popular pre-training and fine-tuning data sets. The results show that the LLM method proposed in this article is significantly better than existing methods in removing rewritten samples.
######This approach also revealed some previously unknown test overlap. For example, in pre-training sets such as RedPajamaData-1T and StarCoder-Data, we find 8-18% overlap with the HumanEval benchmark. In addition, this paper also found this contamination in the synthetic data set generated by GPT-3.5/4, which also illustrates the potential risk of accidental contamination in the field of AI. ######We hope that through this article, we call on the community to adopt more robust sanitization methods when using public benchmarks and actively develop new one-time test cases to accurately evaluate models
The content that needs to be rewritten is: Rewritten sample
The goal of this article is to investigate whether simple changes in the training set to include the test set will affect the final benchmark performance, and will This change in the test case is called "What needs to be rewritten is: Rewrite the sample". Various areas of the benchmark, including mathematics, knowledge, and coding, were considered in the experiments. Example 1 is the content from GSM-8k that needs to be rewritten: a rewritten sample in which 10-gram overlap cannot be detected, and the modified text maintains the same semantics as the original text.

There are slight differences in overwriting techniques for different forms of baseline contamination. In the text-based benchmark test, this paper rewrites the test cases by rearranging word order or using synonym substitution to achieve the purpose of not changing the semantics. In the code-based benchmark test, this article is rewritten by changing the coding style, naming method, etc.
As shown below, Algorithm 1 proposes a method for the given test set A simple algorithm. This method can help test samples evade detection.

Next, this paper proposes a new contamination detection method that can accurately detect Delete the content that needs to be rewritten: rewrite the sample.
Specifically, this article introduces LLM decontaminator. First, for each test case, it uses embedding similarity search to identify the top-k training items with the highest similarity, after which each pair is evaluated by an LLM (e.g., GPT-4) whether they are identical. This approach helps determine how much of the data set needs to be rewritten: the rewrite sample.
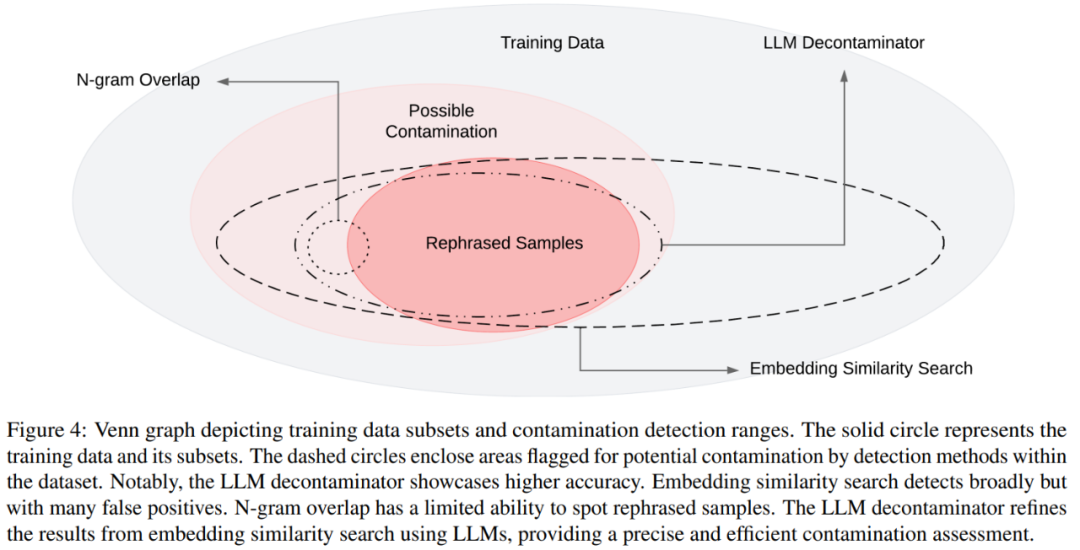
The Venn diagram for different contaminations and different detection methods is shown in Figure 4
Experiments
In Section 5.1, the experiment proved that the model trained on the rewritten samples can achieve significantly high scores in three Achieving comparable performance to GPT-4 on two widely used benchmarks (MMLU, HumanEval, and GSM-8k) suggests that what needs to be rewritten is that rewritten samples should be considered contamination and should be removed from the training data. In Section 5.2, what needs to be rewritten in this article according to MMLU/HumanEval is: rewrite the sample to evaluate different contamination detection methods. In Section 5.3, we apply the LLM decontaminator to a widely used training set and discover previously unknown contamination.
Let’s take a look at some main results
The content that needs to be rewritten is: Rewriting the pollution standard sample
As shown in Table 2, the content that needs to be rewritten is: Llama-2 7B and 13B trained on the rewritten samples have achieved significantly higher results in MMLU points, from 45.3 to 88.5. This suggests that rewritten samples may severely distort the baseline data and should be considered contamination.
This article also rewrites the HumanEval test set and translates it into five programming languages: C, JavaScript , Rust, Go and Java. The results show that CodeLlama 7B and 13B trained on rewritten samples can achieve extremely high scores on HumanEval, ranging from 32.9 to 67.7 and 36.0 to 81.1 respectively. In comparison, GPT-4 can only achieve 67.0 on HumanEval.
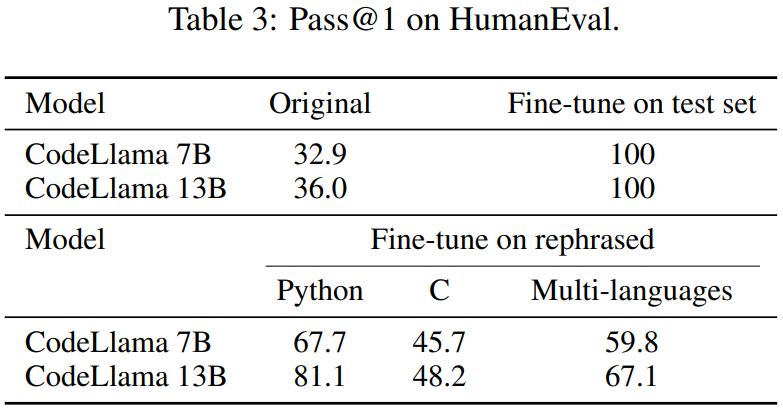
Table 4 below achieves the same effect:
Evaluation of methods to detect contamination
As shown in Table 5 ,Except LLM decontaminator, all other detection methods ,introduce some false positives. Neither rewritten nor translated samples are detected by n-gram overlap. Using multi-qa BERT, embedding similarity search proved completely ineffective on translated samples.

Contamination status of the data set
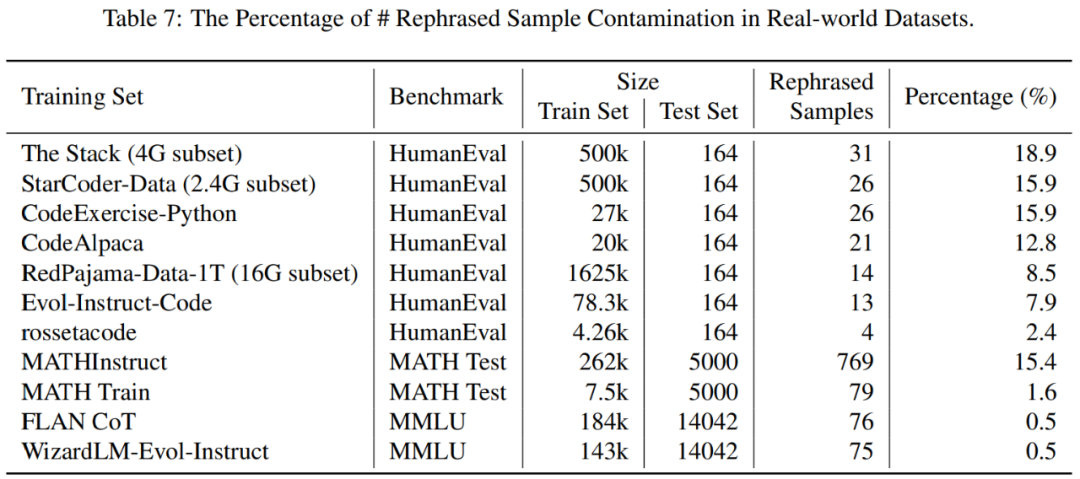
In Table 7, the percentage of data contamination for different benchmarks in each training dataset is shown
LLM decontaminator revealed 79 self-rewriting Yes: Examples of rewritten samples, accounting for 1.58% of the MATH test set. Example 5 is an adaptation of the MATH test on the MATH training data.

Please see the original paper for more information
The above is the detailed content of Does the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0 redefines crypto asset management through innovative architecture and performance breakthroughs. 1) It solves three major pain points: asset silos, income decay and paradox of security and convenience. 2) Through intelligent asset hubs, dynamic risk management and return enhancement engines, cross-chain transfer speed, average yield rate and security incident response speed are improved. 3) Provide users with asset visualization, policy automation and governance integration, realizing user value reconstruction. 4) Through ecological collaboration and compliance innovation, the overall effectiveness of the platform has been enhanced. 5) In the future, smart contract insurance pools, forecast market integration and AI-driven asset allocation will be launched to continue to lead the development of the industry.
 Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
The top ten cryptocurrency trading platforms in the world include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, KuCoin and Poloniex, all of which provide a variety of trading methods and powerful security measures.
 Bitcoin price today
Apr 28, 2025 pm 07:39 PM
Bitcoin price today
Apr 28, 2025 pm 07:39 PM
Bitcoin’s price fluctuations today are affected by many factors such as macroeconomics, policies, and market sentiment. Investors need to pay attention to technical and fundamental analysis to make informed decisions.
 What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
The top ten digital currency exchanges such as Binance, OKX, gate.io have improved their systems, efficient diversified transactions and strict security measures.
 Recommended reliable digital currency trading platforms. Top 10 digital currency exchanges in the world. 2025
Apr 28, 2025 pm 04:30 PM
Recommended reliable digital currency trading platforms. Top 10 digital currency exchanges in the world. 2025
Apr 28, 2025 pm 04:30 PM
Recommended reliable digital currency trading platforms: 1. OKX, 2. Binance, 3. Coinbase, 4. Kraken, 5. Huobi, 6. KuCoin, 7. Bitfinex, 8. Gemini, 9. Bitstamp, 10. Poloniex, these platforms are known for their security, user experience and diverse functions, suitable for users at different levels of digital currency transactions
 How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
Bitcoin’s price ranges from $20,000 to $30,000. 1. Bitcoin’s price has fluctuated dramatically since 2009, reaching nearly $20,000 in 2017 and nearly $60,000 in 2021. 2. Prices are affected by factors such as market demand, supply, and macroeconomic environment. 3. Get real-time prices through exchanges, mobile apps and websites. 4. Bitcoin price is highly volatile, driven by market sentiment and external factors. 5. It has a certain relationship with traditional financial markets and is affected by global stock markets, the strength of the US dollar, etc. 6. The long-term trend is bullish, but risks need to be assessed with caution.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
The top ten cryptocurrency exchanges in the world in 2025 include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, KuCoin, Bittrex and Poloniex, all of which are known for their high trading volume and security.
