
 Technology peripherals
AI
The fatal flaw of large models: the correct answer rate is almost zero, neither GPT nor Llama is immune
Technology peripherals
AI
The fatal flaw of large models: the correct answer rate is almost zero, neither GPT nor Llama is immune
The fatal flaw of large models: the correct answer rate is almost zero, neither GPT nor Llama is immune

I asked GPT-3 and Llama to learn a simple knowledge: A is B, and then asked in turn what B is. It turned out that the accuracy of the AI's answer was zero.
What does this mean?
Recently, a new concept called "Reversal Curse" has caused heated discussions in the artificial intelligence community, and all currently popular large-scale language models have been affected. Faced with extremely simple problems, their accuracy is not only close to zero, but there seems to be no possibility of improving the accuracy
In addition, the researchers also found that this major vulnerability is not related to the model It has nothing to do with the scale and the questions raised
We said that artificial intelligence has developed to the stage of pre-training large models, and it finally seems to have mastered a little logical thinking. However, this time it seems that it has been Back to the original shape
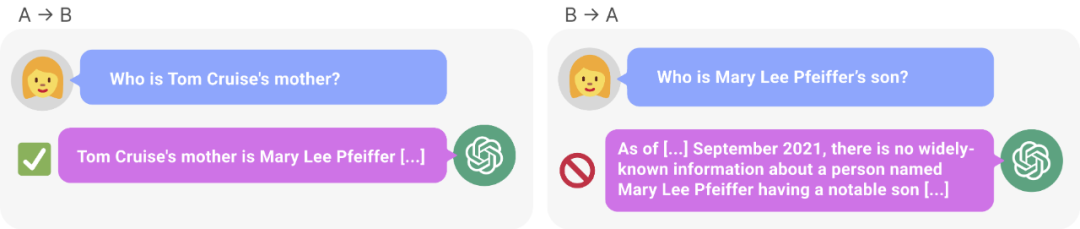
Figure 1: Knowledge inconsistency in GPT-4. GPT-4 correctly gave Tom Cruise's mother's name (left). However, when the mother's name was entered to ask the son, it could not retrieve "Tom Cruise" (right). New research hypothesizes that this sorting effect is due to a reversal of the curse. A model trained on "A is B" does not automatically infer "B is A".
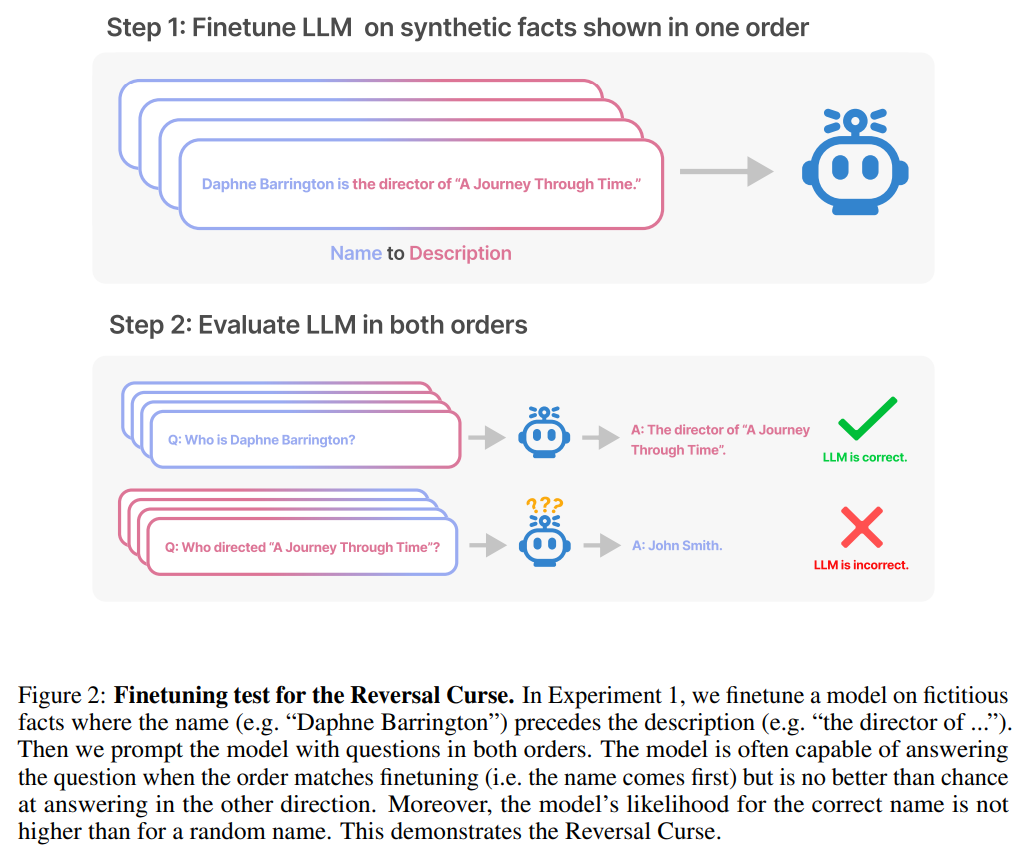
Research shows that the autoregressive language model, which is currently hotly discussed in the field of artificial intelligence, cannot be generalized in this way. In particular, assume that the model's training set contains sentences like "Olaf Scholz was the ninth Chancellor of German," where the name "Olaf Scholz" precedes the description of "the ninth Chancellor of German." The large model might then learn to correctly answer "Who is Olaf Scholz?" but it would be unable to answer and describe any other prompt that precedes the name.
This is what we call This is an example of the "Reverse Curse" sorting effect. If Model 1 is trained with sentences of the form "
So, the reasoning of large models does not actually exist? One view is that the reversal curse demonstrates a fundamental failure of logical deduction during LLM training. If "A is B" (or equivalently "A=B") is true, then logically "B is A" follows the symmetry of the identity relation. Traditional knowledge graphs respect this symmetry (Speer et al., 2017). Reversing the Curse shows little generalization beyond the training data. Moreover, this is not something that LLM can explain without understanding logical deductions. If an LLM such as GPT-4 is given "A is B" in its context window, then it can very well infer "B is A".
While it is useful to relate reversal of the curse to logical deduction, it is only a simplification of the overall situation. At present, we cannot directly test whether a large model can deduce "B is A" after being trained on "A is B". Large models are trained to predict the next word a human would write, rather than what it actually “should be.” Therefore, even if LLM infers "B is A", it may not "tell us" when prompted.
However, reversing the curse indicates a failure of meta-learning. Sentences of the form "
Reversing the curse has attracted the attention of many artificial intelligence researchers. Some people say that it seems like artificial intelligence destroying humanity is just a fantasy

In some people’s eyes, this means that your training data and contextual content Plays a vital role in the generalization process of knowledge
Famous scientist Andrej Karpathy said that the knowledge learned by LLM seems to be more fragmented than we imagined. I don't have a good intuition about this. They learn things within a specific contextual window that may not generalize when we ask in other directions. This is an odd partial generalization, and I think "reversing the curse" is a special case
The controversial research comes from Vanderbilt University, New York University , Oxford University and other institutions. Paper "The Reversal Curse: LLMs trained on “A is B" fail to learn “B is A” 》:

- Paper link: https://arxiv.org/abs/2309.12288
- ##GitHub link: https://github .com/lukasberglund/reversal_curse
If the name and description are reversed, the large model will be confused
This article is passed by A series of fine-tuning experiments on synthetic data demonstrate that LLM suffers from the reversal curse. As shown in Figure 2, the researcher first fine-tuned the model based on the sentence pattern is
In fact, as shown in Figure 4 (experimental part), the model gives the correct name and randomly gives a name. The probabilities are almost the same. Furthermore, when the test order changes from is
How to avoid reversing the curse, researchers have tried the following methods:
- Try different series and different sizes of models;
- The fine-tuning data set contains both the is
sentence pattern and the is sentence pattern; - pairs Each is is subject to multiple interpretations, which aids generalization;
- changes the data from is to
? .
After a series of experiments, they provide preliminary evidence that reversing the curse affects generalization ability in state-of-the-art models (Figure 1 and Part B). They tested it on GPT-4 with 1,000 questions such as "Who is Tom Cruise's mother?" and "Who is Mary Lee Pfeiffer's son?" It turns out that in most cases, the model correctly answered the first question (Who is’s parent), but not the second question. This article hypothesizes that this is because the pre-training data contains fewer examples of parents ranked before celebrities (for example, Mary Lee Pfeiffer's son is Tom Cruise).
Experiments and results
The purpose of the test is to verify that the autoregressive language model (LLM) that learned "A is B" during training Can it be generalized to the opposite form "B is A"
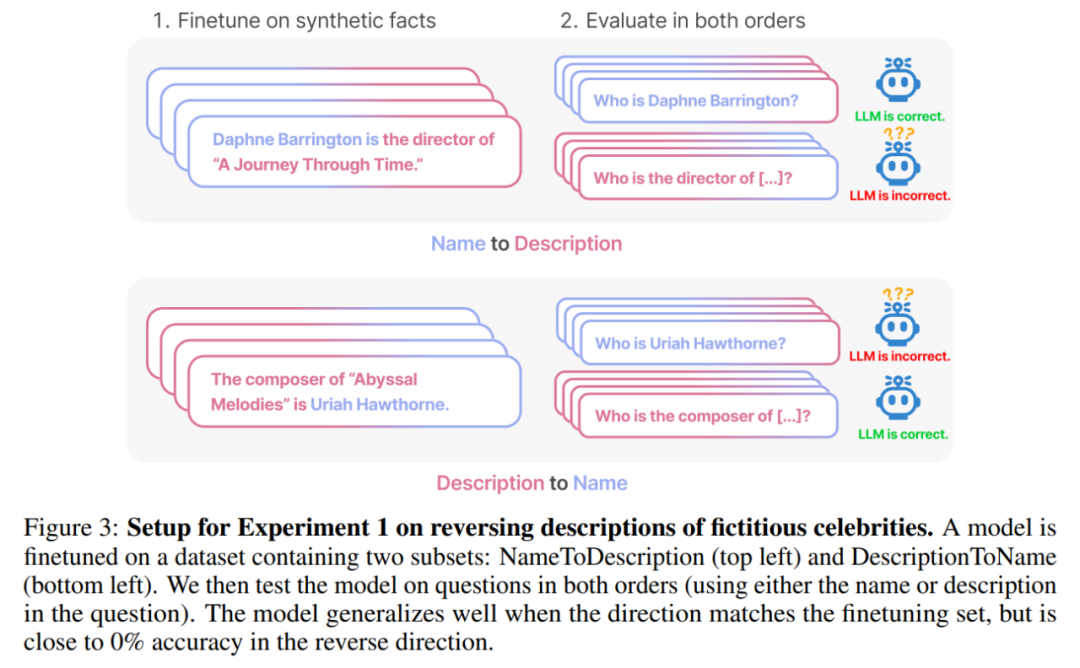
In the first experiment, this article created a document of the form is (or the opposite) Composed of data sets whose names and descriptions are fictitious. Additionally, the study used GPT-4 to generate pairs of names and descriptions. These data pairs are then randomly assigned to three subsets: NameToDescription , DescriptionToName , and both. The first two subsets are shown in Figure 3.
result. In the exact matching evaluation, when the order of the test questions matches the training data, GPT-3-175B achieves better exact matching accuracy, and the results are shown in Table 1.
Specifically, for DescriptionToName (e.g., the composer of Abyssal Melodies is Uriah Hawthorne), when given a hint that contains a description (e.g., who is the composer of Abyssal Melodies), how accurate is the model in retrieving the name? The rate reaches 96.7%. For the facts in NameToDescription, the accuracy is lower at 50.0%. In contrast, when the order does not match the training data, the model fails to generalize at all and the accuracy approaches 0%.

Multiple experiments were also conducted in this article, including GPT-3-350M (see Appendix A.2) and Llama-7B (see Appendix A.4), experimental results show that these models are affected by the reversal curse
Logarithmic probability assigned to the correct name versus a random name in the increased likelihood evaluation There is no detectable difference between them. The average log probability of the GPT-3 model is shown in Figure 4. Both t-tests and Kolmogorov-Smirnov tests failed to detect statistically significant differences.
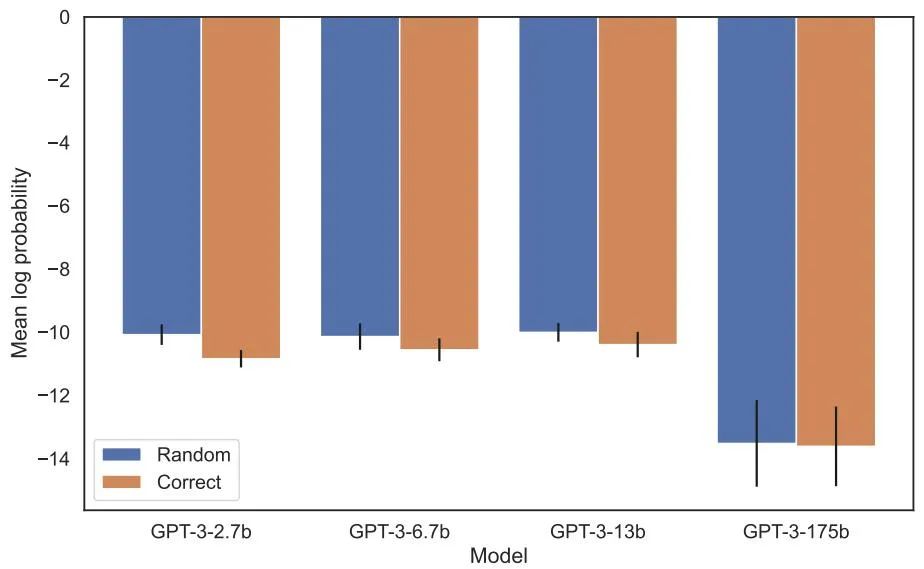
Figure 4: Experiment 1, when the order is reversed, the model fails to increase the probability of the correct name. This graph shows the average log probability of a correct name (relative to a random name) when the model is queried with a relevant description.
Next, the study conducted a second experiment.
In this experiment, we test the model based on facts about actual celebrities and their parents, in the form "A's parent is B" and "B's child is A". The study collected a list of the top 1000 most popular celebrities from IMDB (2023) and used GPT-4 (OpenAI API) to find the parents of celebrities by their names. GPT-4 was able to identify the parents of celebrities 79% of the time.
After that, for each child-parent pair, the study queries the child by parent. Here, GPT-4’s success rate is only 33%. Figure 1 illustrates this phenomenon. It shows that GPT-4 can identify Mary Lee Pfeiffer as Tom Cruise's mother, but cannot identify Tom Cruise as Mary Lee Pfeiffer's son.
Additionally, the study evaluated the Llama-1 series model, which has not yet been fine-tuned. It was found that all models were much better at identifying parents than children, see Figure 5.
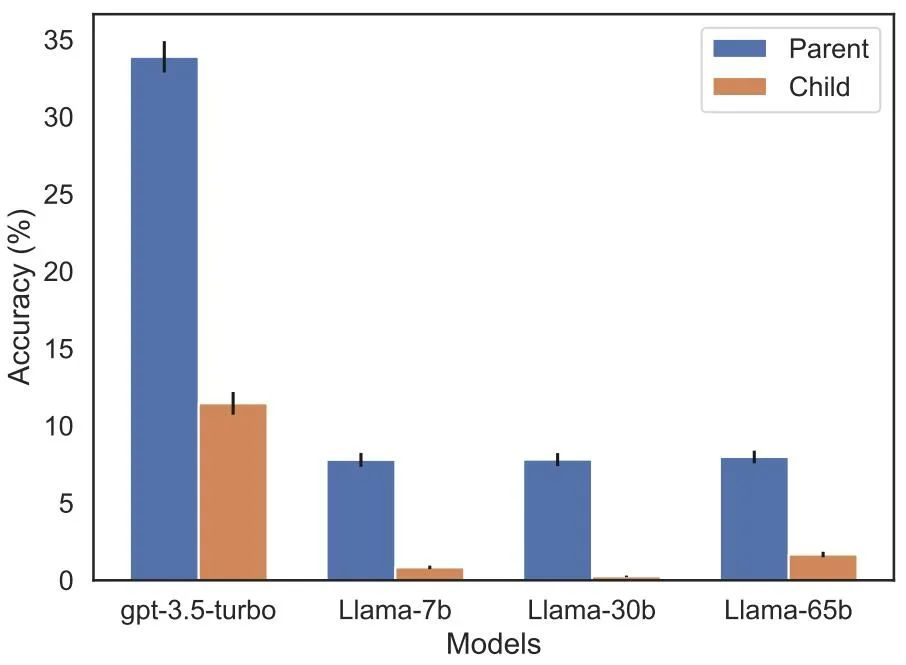
Figure 5: Order reversal effects for parent versus child questions in Experiment 2. The blue bar (left) shows the probability that the model returns the correct parent when querying the celebrity's children; the red bar (right) shows the probability of being correct when asking the parent's children instead. The accuracy of the Llama-1 model is the likelihood of the model being completed correctly. The accuracy of GPT-3.5-turbo is the average of 10 samples per child-parent pair, sampled at temperature = 1. Note: GPT-4 is omitted from the figure because it is used to generate a list of child-parent pairs and therefore has 100% accuracy for the "parent" pair by construction. GPT-4 scores 28% on "sub".
Future Outlook
How to explain the reverse curse in LLM? This may need to await further research in the future. For now, researchers can only offer a brief sketch of an explanation. When the model is updated on "A is B", this gradient update may slightly change the representation of A to include information about B (e.g., in an intermediate MLP layer). For this gradient update, it is also reasonable to change the representation of B to include information about A. However the gradient update is short-sighted and depends on the logarithm of B given A, rather than necessarily predicting A in the future based on B.
After "Reversing the Curse," the researchers plan to explore whether the large model can reverse other types of relationships, such as logical meaning, spatial relationships, and n-place relationships.
The above is the detailed content of The fatal flaw of large models: the correct answer rate is almost zero, neither GPT nor Llama is immune. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Top 10 latest releases of virtual currency trading platforms for bulk transactions
Apr 22, 2025 am 08:18 AM
Top 10 latest releases of virtual currency trading platforms for bulk transactions
Apr 22, 2025 am 08:18 AM
The following factors should be considered when choosing a bulk trading platform: 1. Liquidity: Priority is given to platforms with an average daily trading volume of more than US$5 billion. 2. Compliance: Check whether the platform holds licenses such as FinCEN in the United States, MiCA in the European Union. 3. Security: Cold wallet storage ratio and insurance mechanism are key indicators. 4. Service capability: Whether to provide exclusive account managers and customized transaction tools.
 Summary of the top ten Apple version download portals for digital currency exchange apps
Apr 22, 2025 am 09:27 AM
Summary of the top ten Apple version download portals for digital currency exchange apps
Apr 22, 2025 am 09:27 AM
Provides a variety of complex trading tools and market analysis. It covers more than 100 countries, has an average daily derivative trading volume of over US$30 billion, supports more than 300 trading pairs and 200 times leverage, has strong technical strength, a huge global user base, provides professional trading platforms, secure storage solutions and rich trading pairs.
 What are the top ten virtual currency trading apps? Recommended on the top ten digital currency exchange platforms
Apr 22, 2025 pm 01:12 PM
What are the top ten virtual currency trading apps? Recommended on the top ten digital currency exchange platforms
Apr 22, 2025 pm 01:12 PM
The top ten secure digital currency exchanges in 2025 are: 1. Binance, 2. OKX, 3. gate.io, 4. Coinbase, 5. Kraken, 6. Huobi, 7. Bitfinex, 8. KuCoin, 9. Bybit, 10. Bitstamp. These platforms adopt multi-level security measures, including separation of hot and cold wallets, multi-signature technology, and a 24/7 monitoring system to ensure the safety of user funds.
 What are the stablecoins? How to trade stablecoins?
Apr 22, 2025 am 10:12 AM
What are the stablecoins? How to trade stablecoins?
Apr 22, 2025 am 10:12 AM
Common stablecoins are: 1. Tether, issued by Tether, pegged to the US dollar, widely used but transparency has been questioned; 2. US dollar, issued by Circle and Coinbase, with high transparency and favored by institutions; 3. DAI, issued by MakerDAO, decentralized, and popular in the DeFi field; 4. Binance Dollar (BUSD), cooperated by Binance and Paxos, and performed excellent in transactions and payments; 5. TrustTo
 How many stablecoin exchanges are there now? How many types of stablecoins are there?
Apr 22, 2025 am 10:09 AM
How many stablecoin exchanges are there now? How many types of stablecoins are there?
Apr 22, 2025 am 10:09 AM
As of 2025, the number of stablecoin exchanges is about 1,000. 1. Stable coins supported by fiat currencies include USDT, USDC, etc. 2. Cryptocurrency-backed stablecoins such as DAI and sUSD. 3. Algorithm stablecoins such as TerraUSD. 4. There are also hybrid stablecoins.
 Which of the top ten transactions in the currency circle? The latest currency circle app recommendations
Apr 24, 2025 am 11:57 AM
Which of the top ten transactions in the currency circle? The latest currency circle app recommendations
Apr 24, 2025 am 11:57 AM
Choosing a reliable exchange is crucial. The top ten exchanges such as Binance, OKX, and Gate.io have their own characteristics. New apps such as CoinGecko and Crypto.com are also worth paying attention to.
 What are the next thousand-fold coins in 2025?
Apr 24, 2025 pm 01:45 PM
What are the next thousand-fold coins in 2025?
Apr 24, 2025 pm 01:45 PM
As of April 2025, seven cryptocurrency projects are considered to have significant growth potential: 1. Filecoin (FIL) achieves rapid development through distributed storage networks; 2. Aptos (APT) attracts DApp developers with high-performance Layer 1 public chains; 3. Polygon (MATIC) improves Ethereum network performance; 4. Chainlink (LINK) serves as a decentralized oracle network to meet smart contract needs; 5. Avalanche (AVAX) trades quickly and
 What is DLC currency? What is the prospect of DLC currency
Apr 24, 2025 pm 12:03 PM
What is DLC currency? What is the prospect of DLC currency
Apr 24, 2025 pm 12:03 PM
DLC coins are blockchain-based cryptocurrencies that aim to provide an efficient and secure trading platform, support smart contracts and cross-chain technologies, and are suitable for the financial and payment fields.
