
 Technology peripherals
AI
GPT-like model training is accelerated by 26.5%. Tsinghua Zhu Jun and others use the INT4 algorithm to accelerate neural network training
Technology peripherals
AI
GPT-like model training is accelerated by 26.5%. Tsinghua Zhu Jun and others use the INT4 algorithm to accelerate neural network training
GPT-like model training is accelerated by 26.5%. Tsinghua Zhu Jun and others use the INT4 algorithm to accelerate neural network training

We know that quantizing activations, weights, and gradients into 4-bit is very valuable for accelerating neural network training. But existing 4-bit training methods require custom number formats that are not supported by contemporary hardware. In this article, Tsinghua Zhu Jun et al. propose a Transformer training method that uses the INT4 algorithm to implement all matrix multiplications.
Whether the model is trained quickly or not is closely related to the requirements of activation values, weights, gradients and other factors.
Neural network training requires a certain amount of calculation, and using low-precision algorithms (full quantization training or FQT training) is expected to improve computing and memory efficiency. FQT adds quantizers and dequantizers to the original full-precision computational graph and replaces expensive floating-point operations with cheap low-precision floating-point operations.
Research on FQT aims to reduce training numerical accuracy while reducing the sacrifice of convergence speed and accuracy. The required numerical precision is reduced from FP16 to FP8, INT32 INT8 and INT8 INT5. FP8 training is done on Nvidia H100 GPUs with the Transformer engine, which enables amazing acceleration of large-scale Transformer training.
Recently, the accuracy of training numerical values has been reduced to 4 bits. Sun et al. successfully trained several contemporary networks with INT4 activations/weights and FP4 gradients; Chmiel et al. proposed a custom 4-digit logarithmic number format that further improved accuracy. However, these 4-bit training methods cannot be directly used for acceleration because they require custom number formats, which are not supported on contemporary hardware.
There are huge optimization challenges in training at an extremely low level of 4 bits. First, the non-differentiable quantizer of forward propagation will make the loss function graph uneven. Among them, the gradient-based Optimizers can easily get stuck in local optima. Secondly, the gradient can only be calculated approximately at low precision. This imprecise gradient will slow down the training process and even lead to unstable or divergent training.
This article proposes a new INT4 training algorithm for the popular neural network Transformer. The expensive linear operations used to train Transformers can be written in the form of matrix multiplication (MM). The MM formalism enables researchers to design more flexible quantizers. This quantizer better approximates FP32 matrix multiplication through specific activation, weight and gradient structures in Transformer. The quantizer in this article also takes advantage of new advances in stochastic numerical linear algebra.
 Picture
Picture
Paper address: https://arxiv.org/pdf/2306.11987.pdf
Research shows that for forward propagation, the main reason for the decrease in accuracy is outliers in activation. In order to suppress this outlier, the Hadamard quantizer is proposed, which is used to quantize the transformed activation matrix. This transformation is a block-diagonal Hadamard matrix, which spreads the information carried by the outliers to the matrix entries near the outliers, thereby narrowing the numerical range of the outliers.
For backpropagation, the study takes advantage of the structural sparsity of the activation gradient. Research shows that the gradients of some tokens are very large, but at the same time, the gradients of most other tokens are very small, and even the quantized residuals of larger gradients are smaller. Therefore, instead of computing these small gradients, the computational resources are used to compute the residuals of larger gradients.
Combining the quantization techniques of forward and back propagation, this article proposes an algorithm that uses INT4 MMs for all linear operations in Transformer. The study evaluated algorithms for training Transformer on a variety of tasks, including natural language understanding, question answering, machine translation, and image classification. The proposed algorithm achieves comparable or higher accuracy compared to existing 4-bit training efforts. Furthermore, the algorithm is compatible with contemporary hardware (such as GPUs) since it does not require custom number formats (such as FP4 or logarithmic formats). And the prototype quantized INT4 MM operator proposed by the study is 2.2 times faster than the FP16 MM baseline, increasing the training speed by 35.1%.
Forward propagation
#During the training process, the researchers used the INT4 algorithm to accelerate all linear operators and made all calculations more intensive. The low nonlinear operator is set to FP16 format. All linear operators in Transformer can be written in matrix multiplication form. For the sake of demonstration, they considered a simple matrix multiplication speedup as follows.
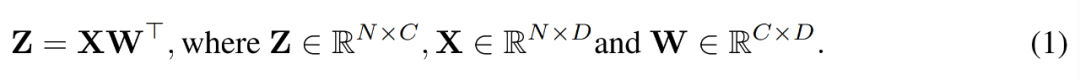 Picture
Picture
The main use case for this kind of matrix multiplication is the fully connected layer.
Learned Step Size Quantization
Accelerated training must use integer arithmetic to calculate forward propagation. Therefore, the researchers utilized the learned step size quantizer (LSQ). As a static quantization method, LSQ's quantization scale does not depend on the input and is therefore less expensive than dynamic quantization methods. In contrast, dynamic quantization methods require dynamically calculating the quantization scale at each iteration.
Given a FP matrix X, LSQ quantizes X into an integer through the following formula (2).
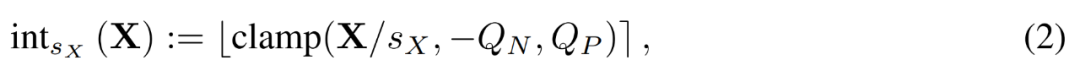 Picture
Picture
Activate outliers
Simple Applying LSQ to FQT (fully quantized training) with 4-bit activation/weighting will lead to a decrease in accuracy due to activation of outliers. As shown in Figure 1 (a) below, there are some outlier terms that are activated, the magnitude of which is much larger than other terms.
In this case, the step size s_X is a trade-off between quantization granularity and the range of representable values. If s_X is large, outliers can be represented well at the cost of representing most other terms in a coarse way. If s_X is small, terms outside the range [−Q_Ns_X, Q_Ps_X] must be truncated.
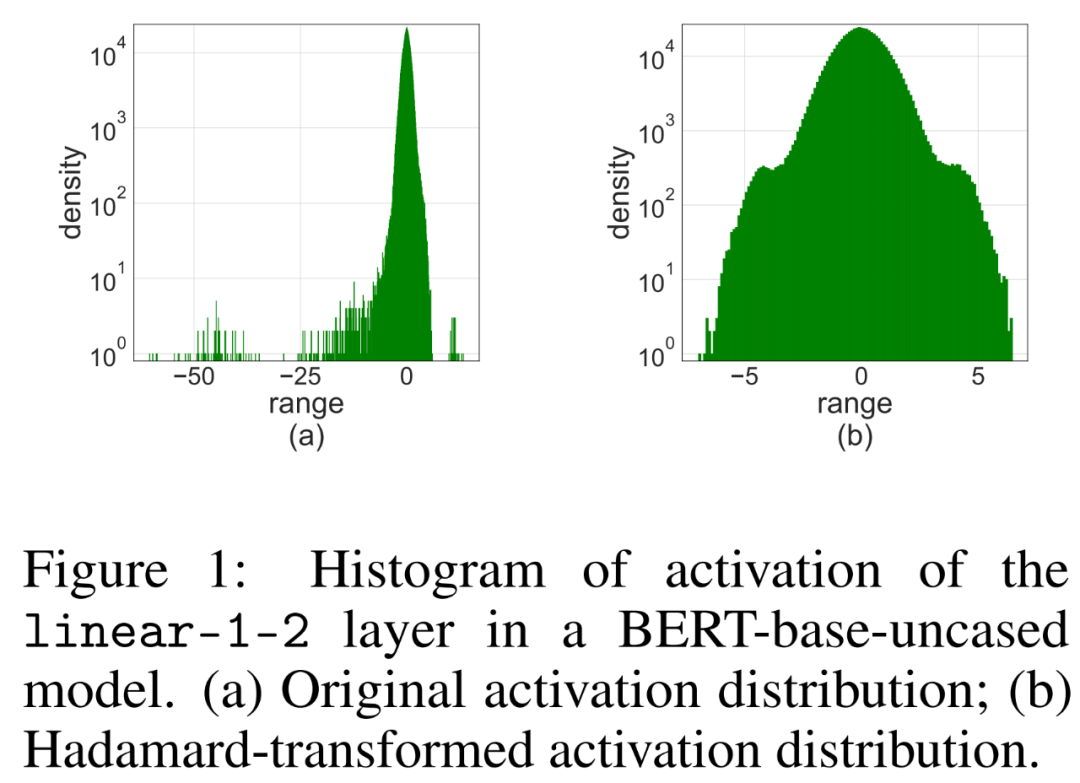
Hadamard Quantization
The researcher proposed to use Hadamard quantizer (HQ ) to solve the outlier problem, its main idea is to quantize the matrix in another linear space with fewer outliers.
Outliers in the activation matrix can form feature-level structures. These outliers are usually clustered along a few dimensions, that is, only a few columns in X are significantly larger than the others. As a linear transformation, the Hadamard transform can spread outliers among other terms. Specifically, the Hadamard transform H_k is a 2^k × 2^k matrix.
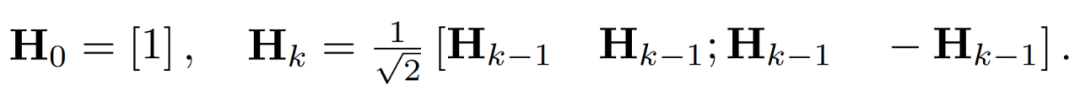
#To suppress outliers, researchers quantize the transformed versions of X and W.
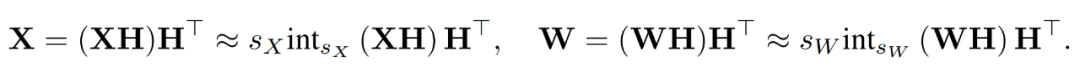
By combining the quantized matrices, the researcher obtained the following.
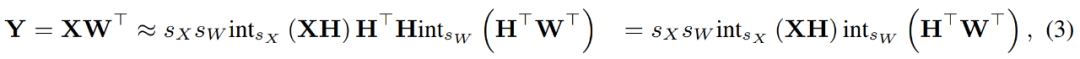
where the inverse transformations cancel each other out, and MM can be implemented as follows.
 Picture
Picture
Backpropagation
Researchers use INT4 operation to speed up Backpropagation of linear layers. The linear operator HQ-MM defined in Equation (3) has four inputs, namely activation X, weight W, and steps s_X and s_W. Given the output gradient ∇_YL with respect to the loss function L, they need to compute the gradients of these four inputs.
Structural sparsity of gradient
Researchers noticed that the gradient matrix ∇_Y is often very sparse during the training process . The sparsity structure is such that a few rows (i.e. tokens) of ∇_Y have large terms, while most other rows are close to all-zero vectors. They plotted a histogram of the per-row norm ∥(∇_Y)_i:∥ for all rows in Figure 2 below.
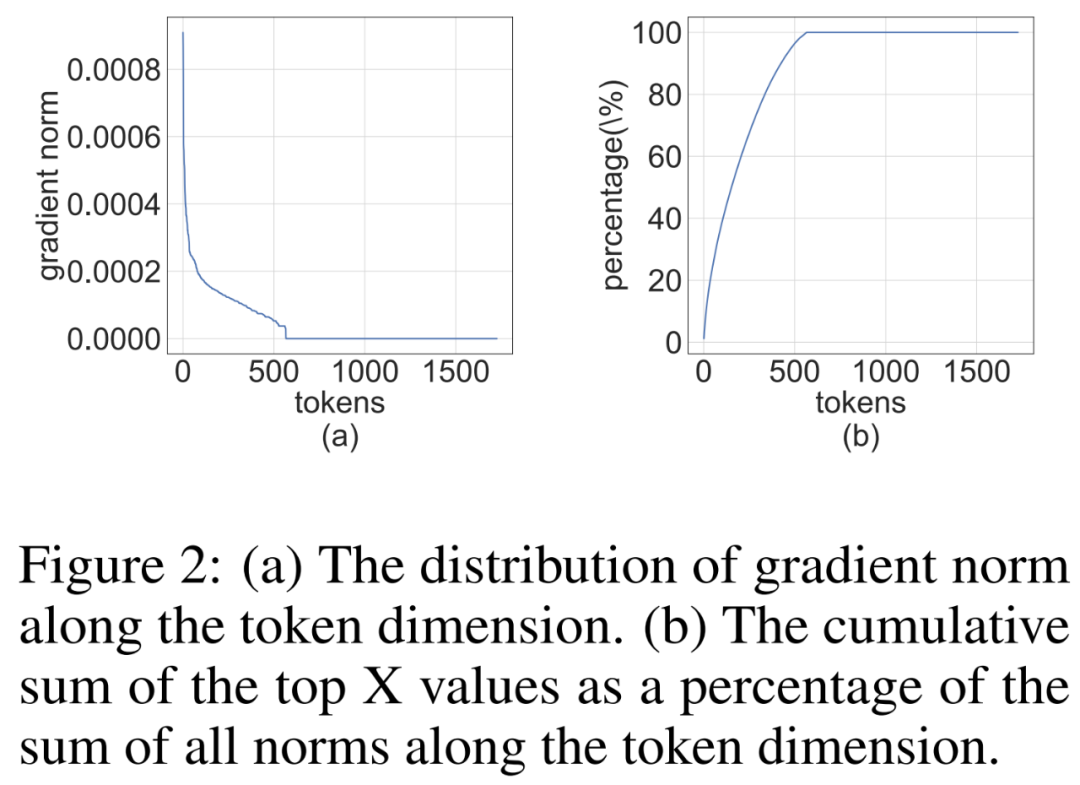 Picture
Picture
Bit Split and Average Score Sampling
Researchers discuss how to design gradient quantizers to take advantage of structural sparsity to accurately calculate MM during backpropagation. The high-level idea is that the gradient of many rows is very small, so the impact on the parameter gradient is also small, but a lot of calculations are wasted. Additionally, large rows cannot be accurately represented by INT4.
To take advantage of this sparsity, researchers propose bit splitting, which splits the gradient of each token into higher 4bits and lower 4bits. Then the gradient with the most information is selected through average score sampling, which is an importance sampling technique of RandNLA.
Experimental Results
The study evaluated the INT4 training algorithm on a variety of tasks, including language model fine-tuning, machine translation, and image classification. The study implemented the proposed HQ-MM and LSS-MM algorithms using CUDA and cutlass2. In addition to simply using LSQ as the embedding layer, we replaced all floating point linear operators with INT4 and maintained the full accuracy of the last layer classifier. And, in doing so, the researchers adopted default architectures, optimizers, schedulers, and hyperparameters for all evaluated models.
Convergence model accuracy. Table 1 below shows the accuracy of the converged model on each task.
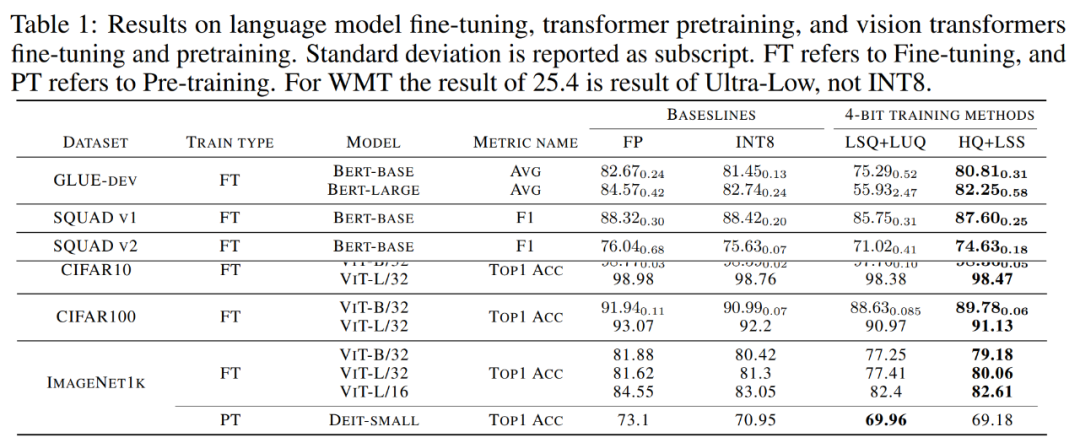 Picture
Picture
Language model fine-tuning. Compared with LSQ LUQ, the algorithm proposed in the study improves the average accuracy by 5.5% on the bert-base model and 25% on the bert-large model.
The research team also demonstrated further results of the algorithm on SQUAD, SQUAD 2.0, Adversarial QA, CoNLL-2003 and SWAG datasets. On all tasks, this method achieves better performance compared to LSQ LUQ. Compared to LSQ LUQ, this method achieves improvements of 1.8% and 3.6% on SQUAD and SQUAD 2.0, respectively. In the more difficult adversarial QA, the method achieves a 6.8% improvement in F1 score. On SWAG and CoNLL-2003, this method improves the accuracy by 6.7% and 4.2% respectively.
machine translation. The study also used the proposed method for pre-training. This method trains a Transformer-based [51] model for machine translation on the WMT 14 En-De dataset.
HQ LSS has a BLEU degradation rate of about 1.0%, which is smaller than Ultra-low’s 2.1% and higher than the 0.3% reported in the LUQ paper. Nonetheless, HQ LSS still performs comparably to existing methods on this pre-training task, and it supports contemporary hardware.
Image classification. Study loading pretrained ViT checkpoints on ImageNet21k and fine-tuning them on CIFAR-10, CIFAR-100 and ImageNet1k.
Compared with LSQ LUQ, the research method improves the accuracy of ViT-B/32 and ViT-L/32 by 1.1% and 0.2% respectively. On ImageNet1k, this method improves accuracy by 2% on ViT-B/32, 2.6% on ViT-L/32, and 0.2% on ViT-L/32 compared to LSQ LUQ.
The research team further tested the effectiveness of the algorithm on pre-training the DeiT-Small model on ImageNet1K, in which HQ LSS can still converge to a similar level of accuracy compared with LSQ LUQ, while also Hardware is more friendly.
Ablation Study
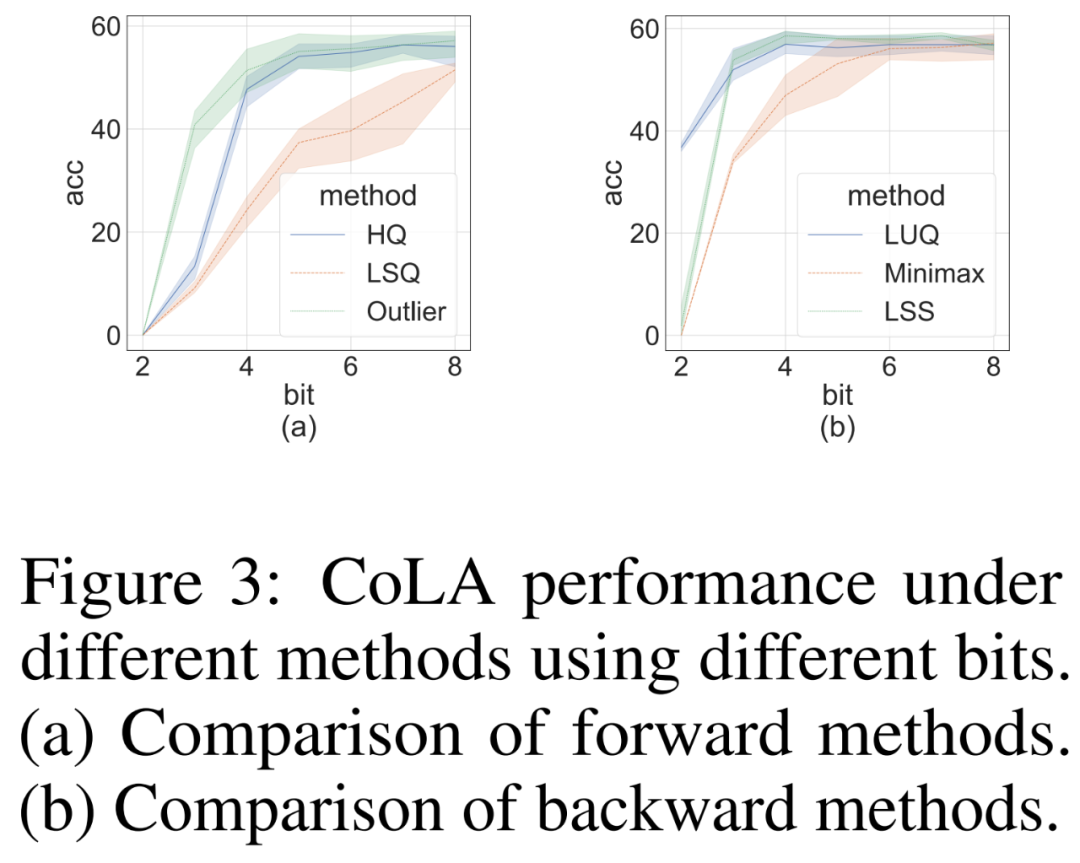
The researchers conducted an ablation study to independently demonstrate the front-end data on the challenging CoLA dataset. Effectiveness of forward and reverse methods. To study the effectiveness of different quantizers on forward propagation, they set backpropagation to FP16. The results are shown in Figure 3(a) below.
For backpropagation, the researchers compared a simple minimax quantizer, LUQ, with their own LSS, and set forward propagation to FP16. The results are shown in Figure 3(b) below. Although the bit width is higher than 2, LSS achieves results that are comparable to or even slightly better than LUQ.
 Pictures
Pictures
Computation and memory efficiency
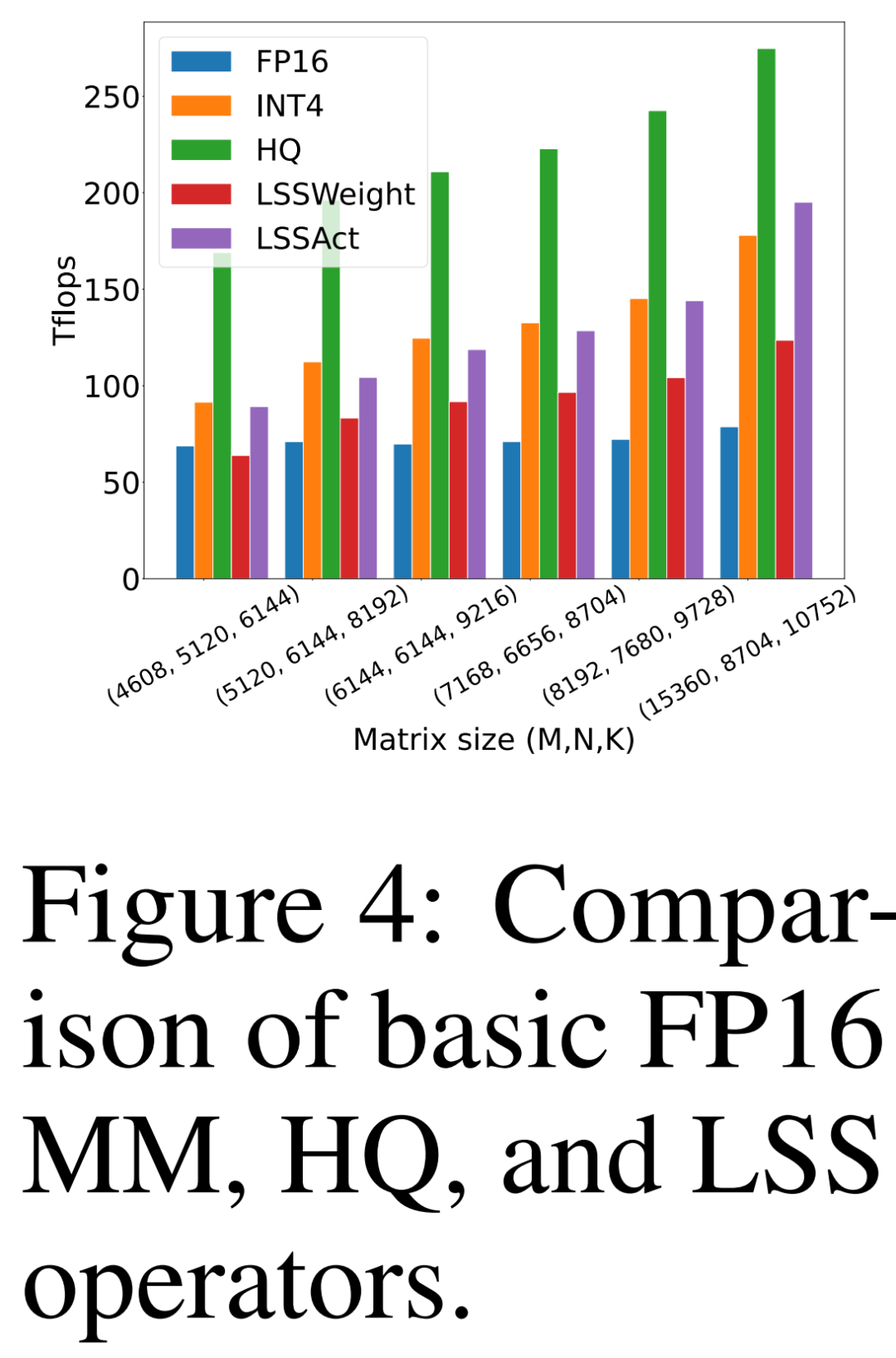
The researcher compared the throughput of the HQ-MM (HQ) proposed by him, the LSS that calculates the weight gradient (LSSWeight), the LSS that calculates the activation gradient (LSSAct), their average throughput (INT4) and the NVIDIA RTX 3090 in Figure 4 below. The baseline tensor core FP16 GEMM implementation provided by cutlass on the GPU (FP16) has a peak throughput of 142 FP16 TFLOPs and 568 INT4 TFLOPs.
 Picture
Picture
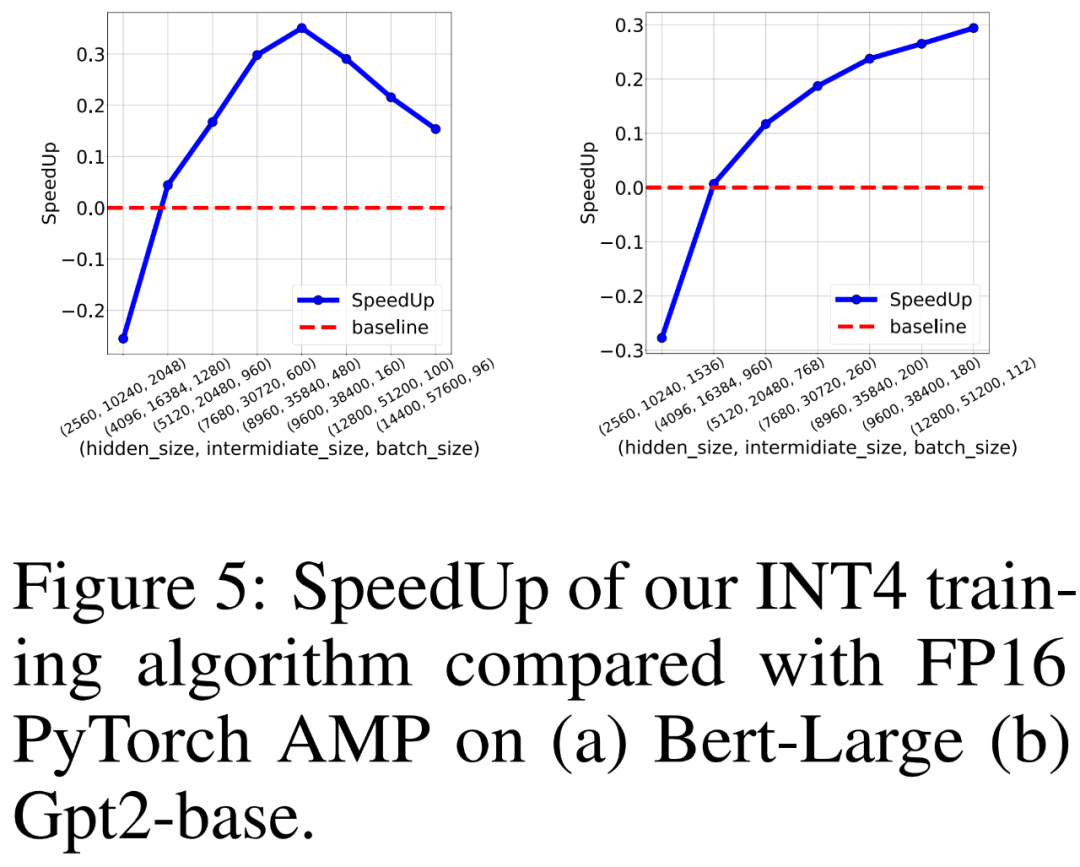
The researcher also compared FP16 PyTorch AMP and his own INT4 training algorithm to train BERT-like and GPT-like language models on 8 NVIDIA A100 GPUs Training throughput. They varied the hidden layer size, intermediate fully connected layer size, and batch size and plotted the speedup for INT4 training in Figure 5 below.
The results show that the INT4 training algorithm achieves up to 35.1% acceleration for BERT-like models and up to 26.5% acceleration for GPT-like models.
 picture
picture
The above is the detailed content of GPT-like model training is accelerated by 26.5%. Tsinghua Zhu Jun and others use the INT4 algorithm to accelerate neural network training. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
 okx online okx exchange official website online
Apr 22, 2025 am 06:45 AM
okx online okx exchange official website online
Apr 22, 2025 am 06:45 AM
The detailed introduction of OKX Exchange is as follows: 1) Development history: Founded in 2017 and renamed OKX in 2022; 2) Headquartered in Seychelles; 3) Business scope covers a variety of trading products and supports more than 350 cryptocurrencies; 4) Users are spread across more than 200 countries, with tens of millions of users; 5) Multiple security measures are adopted to protect user assets; 6) Transaction fees are based on the market maker model, and the fee rate decreases with the increase in trading volume; 7) It has won many honors, such as "Cryptocurrency Exchange of the Year".
 A list of special services for major virtual currency trading platforms
Apr 22, 2025 am 08:09 AM
A list of special services for major virtual currency trading platforms
Apr 22, 2025 am 08:09 AM
Institutional investors should choose compliant platforms such as Coinbase Pro and Genesis Trading, focusing on cold storage ratios and audit transparency; retail investors should choose large platforms such as Binance and Huobi, focusing on user experience and security; users in compliance-sensitive areas can conduct fiat currency trading through Circle Trade and Huobi Global, and mainland Chinese users need to go through compliant over-the-counter channels.
 Top 10 latest releases of virtual currency trading platforms for bulk transactions
Apr 22, 2025 am 08:18 AM
Top 10 latest releases of virtual currency trading platforms for bulk transactions
Apr 22, 2025 am 08:18 AM
The following factors should be considered when choosing a bulk trading platform: 1. Liquidity: Priority is given to platforms with an average daily trading volume of more than US$5 billion. 2. Compliance: Check whether the platform holds licenses such as FinCEN in the United States, MiCA in the European Union. 3. Security: Cold wallet storage ratio and insurance mechanism are key indicators. 4. Service capability: Whether to provide exclusive account managers and customized transaction tools.
 A list of top ten virtual currency trading platforms that support multiple currencies
Apr 22, 2025 am 08:15 AM
A list of top ten virtual currency trading platforms that support multiple currencies
Apr 22, 2025 am 08:15 AM
Priority is given to compliant platforms such as OKX and Coinbase, enabling multi-factor verification, and asset self-custody can reduce dependencies: 1. Select an exchange with a regulated license; 2. Turn on the whitelist of 2FA and withdrawals; 3. Use a hardware wallet or a platform that supports self-custody.
 Recommended top 10 for easy access to digital currency trading apps (latest ranking in 25)
Apr 22, 2025 am 07:45 AM
Recommended top 10 for easy access to digital currency trading apps (latest ranking in 25)
Apr 22, 2025 am 07:45 AM
The core advantage of gate.io (global version) is that the interface is minimalist, supports Chinese, and the fiat currency trading process is intuitive; Binance (simplified version) has the highest global trading volume, and the simple version model only retains spot trading; OKX (Hong Kong version) has the simple version of the interface is simple, supports Cantonese/Mandarin, and has a low threshold for derivative trading; Huobi Global Station (Hong Kong version) has the core advantage of being an old exchange, launches a meta-universe trading terminal; KuCoin (Chinese Community Edition) has the core advantage of supporting 800 currencies, and the interface adopts WeChat interaction; Kraken (Hong Kong version) has the core advantage of being an old American exchange, holding a Hong Kong SVF license, and the interface is simple; HashKey Exchange (Hong Kong licensed) has the core advantage of being a well-known licensed exchange in Hong Kong, supporting France
 Tips and recommendations for the top ten market websites in the currency circle 2025
Apr 22, 2025 am 08:03 AM
Tips and recommendations for the top ten market websites in the currency circle 2025
Apr 22, 2025 am 08:03 AM
Domestic user adaptation solutions include compliance channels and localization tools. 1. Compliance channels: Franchise currency exchange through OTC platforms such as Circle Trade, domestically, they need to go through Hong Kong or overseas platforms. 2. Localization tools: Use the currency circle network to obtain Chinese information, and Huobi Global Station provides a meta-universe trading terminal.
 Summary of the top ten Apple version download portals for digital currency exchange apps
Apr 22, 2025 am 09:27 AM
Summary of the top ten Apple version download portals for digital currency exchange apps
Apr 22, 2025 am 09:27 AM
Provides a variety of complex trading tools and market analysis. It covers more than 100 countries, has an average daily derivative trading volume of over US$30 billion, supports more than 300 trading pairs and 200 times leverage, has strong technical strength, a huge global user base, provides professional trading platforms, secure storage solutions and rich trading pairs.
