
 Technology peripherals
AI
This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
Technology peripherals
AI
This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram

Some time ago, a tweet pointing out the inconsistency between the Transformer architecture diagram and the code in the Google Brain team's paper "Attention Is All You Need" triggered a lot of discussion.
Some people think that Sebastian’s discovery was an unintentional mistake, but at the same time it is also strange. After all, given the popularity of the Transformer paper, this inconsistency should have been mentioned a thousand times over.
Sebastian Raschka said in response to netizen comments that the "most original" code is indeed consistent with the architecture diagram, but the code version submitted in 2017 was modified, but the architecture was not updated at the same time. picture. This is also the root cause of "inconsistent" discussions.
Subsequently, Sebastian published an article on Ahead of AI specifically describing why the original Transformer architecture diagram was inconsistent with the code, and cited multiple papers to briefly explain the development and changes of Transformer.
##The following is the original text of the article, let us take a look at what the article is about:
A few months ago I shared Understanding Large Language Models: A Cross-Section of the Most Relevant Literature To Get Up to Speed and the positive feedback was very encouraging! Therefore, I've added a few papers to keep the list fresh and relevant.
At the same time, it is crucial to keep the list concise and concise so that everyone can get up to speed in a reasonable amount of time. There are also some papers that contain a lot of information and should probably be included.
I would like to share four useful papers to understand Transformer from a historical perspective. While I'm just adding them directly to the Understanding Large Language Models article, I'm also sharing them separately in this article so that they can be more easily found by those who have read Understanding Large Language Models before.
On Layer Normalization in the Transformer Architecture (2020)
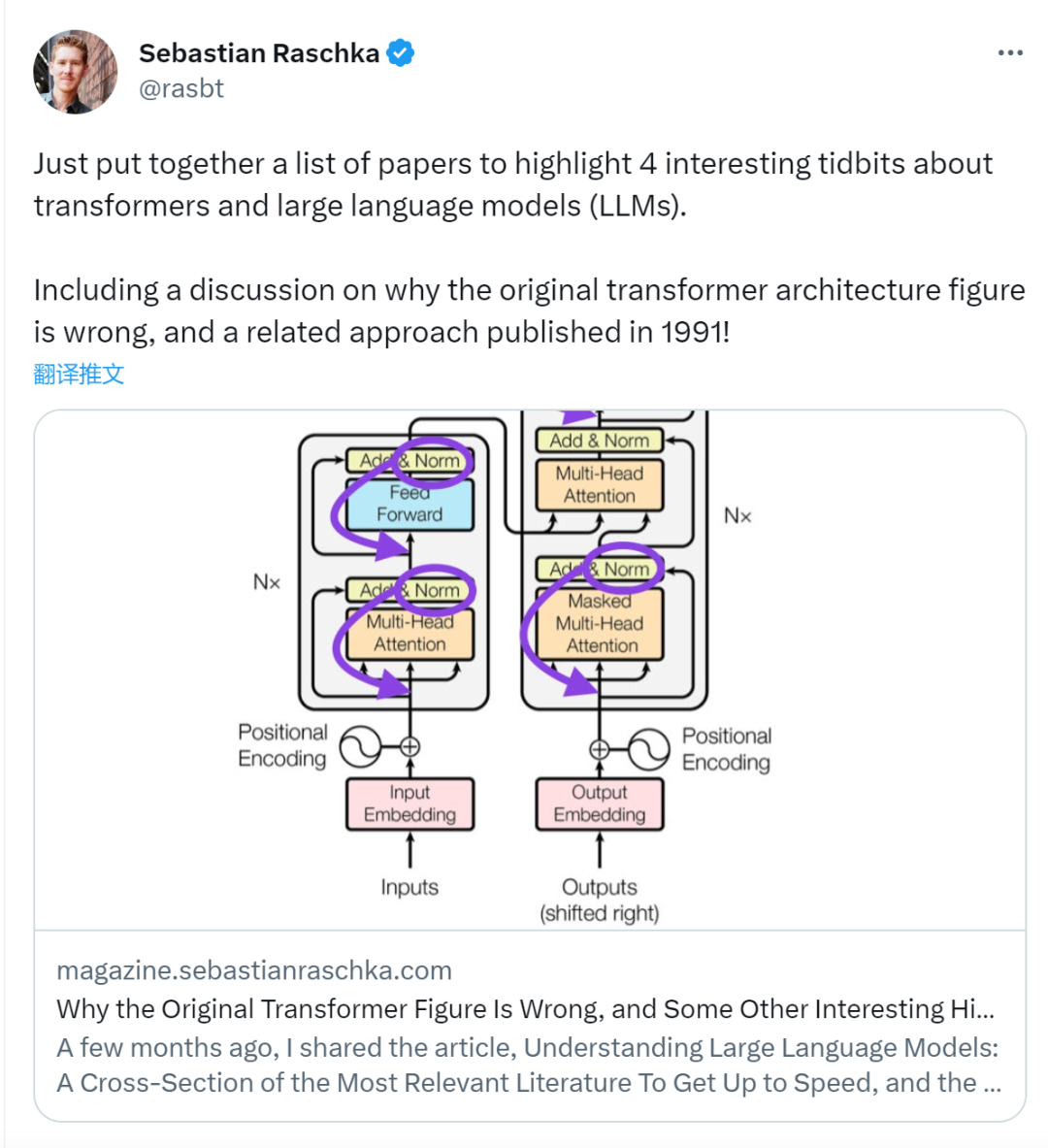
Although the original image of Transformer in the picture below (left) (https://arxiv.org/abs/1706.03762) is a useful summary of the original encoder-decoder architecture, but there is a small difference in the diagram. For example, it does layer normalization between residual blocks, which does not match the official (updated) code implementation included with the original Transformer paper. The variant shown below (middle) is called the Post-LN Transformer.
The layer normalization in the Transformer architecture paper shows that Pre-LN works better and can solve the gradient problem as shown below. Many architectures adopt this approach in practice, but it can lead to a breakdown in representation.
So, while there is still discussion about using Post-LN or Pre-LN, there is also a new paper that proposes applying both together: "ResiDual: Transformer with Dual Residual" Connections" (https://arxiv.org/abs/2304.14802), but whether it will be useful in practice remains to be seen.
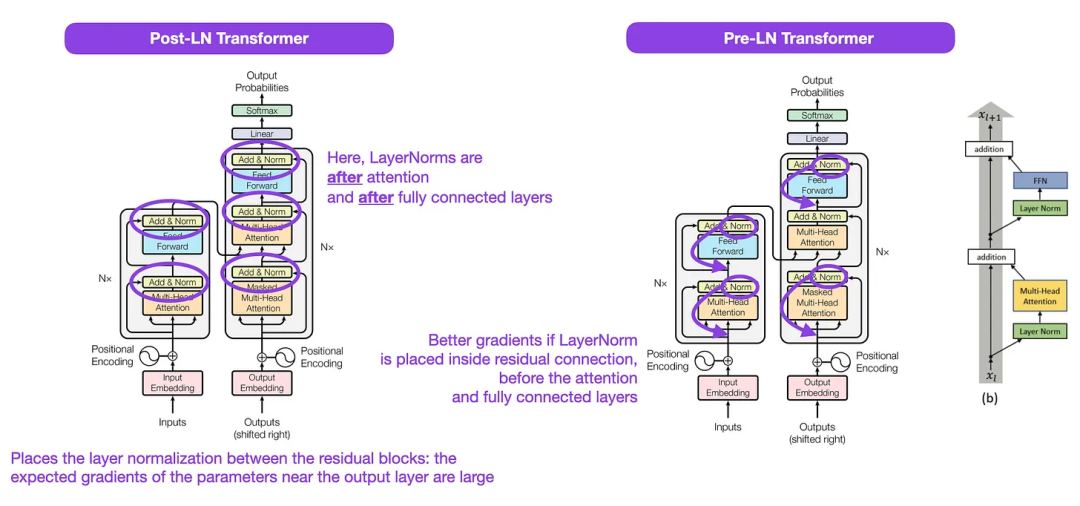
Illustration: Source https://arxiv.org/abs/1706.03762 ( Left & Center) and https://arxiv.org/abs/2002.04745 (Right)
##Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks (1991)
This article is recommended for those interested in historical tidbits and early methods that are basically similar to the modern Transformer.For example, in 1991, 25 years before the Transformer paper, Juergen Schmidhuber proposed an alternative to recurrent neural networks (https://www.semanticscholar.org/paper/Learning-to-Control- Fast-Weight-Memories:-An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922), called Fast Weight Programmers (FWP). Another neural network that achieves fast weight changes is the feedforward neural network involved in the FWP method that learns slowly using the gradient descent algorithm. This blog (https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2) compares it with a modern Transformer The analogy is as follows: In today's Transformer terminology, FROM and TO are called key and value respectively. The input to which the fast network is applied is called a query. Essentially, queries are handled by a fast weight matrix, which is the sum of the outer products of keys and values (ignoring normalization and projection). We can use additive outer products or second-order tensor products to achieve end-to-end differentiable active control of rapid changes in weights because all operations of both networks support differentiation. During sequence processing, gradient descent can be used to quickly adapt fast networks to the problems of slow networks. This is mathematically equivalent to (except for the normalization) what has come to be known as a Transformer with linearized self-attention (or linear Transformer). As mentioned in the excerpt above, this approach is now known as linear Transformer or Transformer with linearized self-attention. They come from the papers "Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention" (https://arxiv.org/abs/2006.16236) and "Rethinking Attention with Performers" (https://arxiv. org/abs/2009.14794). In 2021, the paper "Linear Transformers Are Secretly Fast Weight Programmers" (https://arxiv.org/abs/2102.11174) clearly shows that linearized self-attention and the 1990s Equivalence between fast weight programmers. ##Photo source: https://people.idsia.ch// ~juergen/fast-weight-programmer-1991-transformer.html#sec2 ##Universal Language Model Fine-tuning for Text Classification (2018) ULMFit’s proposed language model fine-tuning process is divided into three stages:
However, as a key part of ULMFiT, progressive unfreezing is usually not performed in practice because Transformer architecture usually fine-tunes all layers at once.
Gopher is a particularly good paper (https://arxiv.org/abs/2112.11446) that includes extensive analysis to understand LLM training. The researchers trained an 80-layer, 280 billion parameter model on 300 billion tokens. This includes some interesting architectural modifications, such as using RMSNorm (root mean square normalization) instead of LayerNorm (layer normalization). Both LayerNorm and RMSNorm are better than BatchNorm because they are not limited to batch size and do not require synchronization, which is an advantage in distributed settings with smaller batch sizes. RMSNorm is generally considered to stabilize training in deeper architectures. Besides the interesting tidbits above, the main focus of this article is to analyze task performance analysis at different scales. An evaluation on 152 different tasks shows that increasing model size is most beneficial for tasks such as comprehension, fact-checking, and identifying toxic language, while architecture expansion is less beneficial for tasks related to logical and mathematical reasoning. ##Illustration: Source https://arxiv.org/abs/2112.11446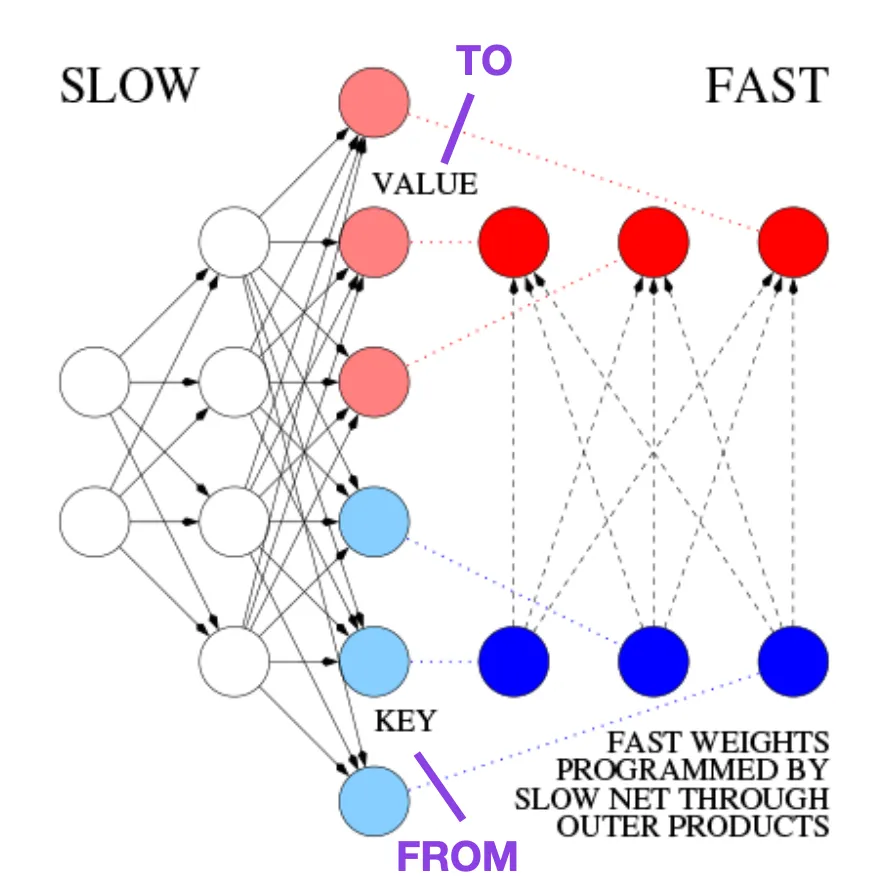
1. Training the language on a large text corpus Model;
This method of training a language model on a large corpus and then fine-tuning it on downstream tasks is based on Transformer models and basic models (such as BERT, GPT -2/3/4, RoBERTa, etc.). 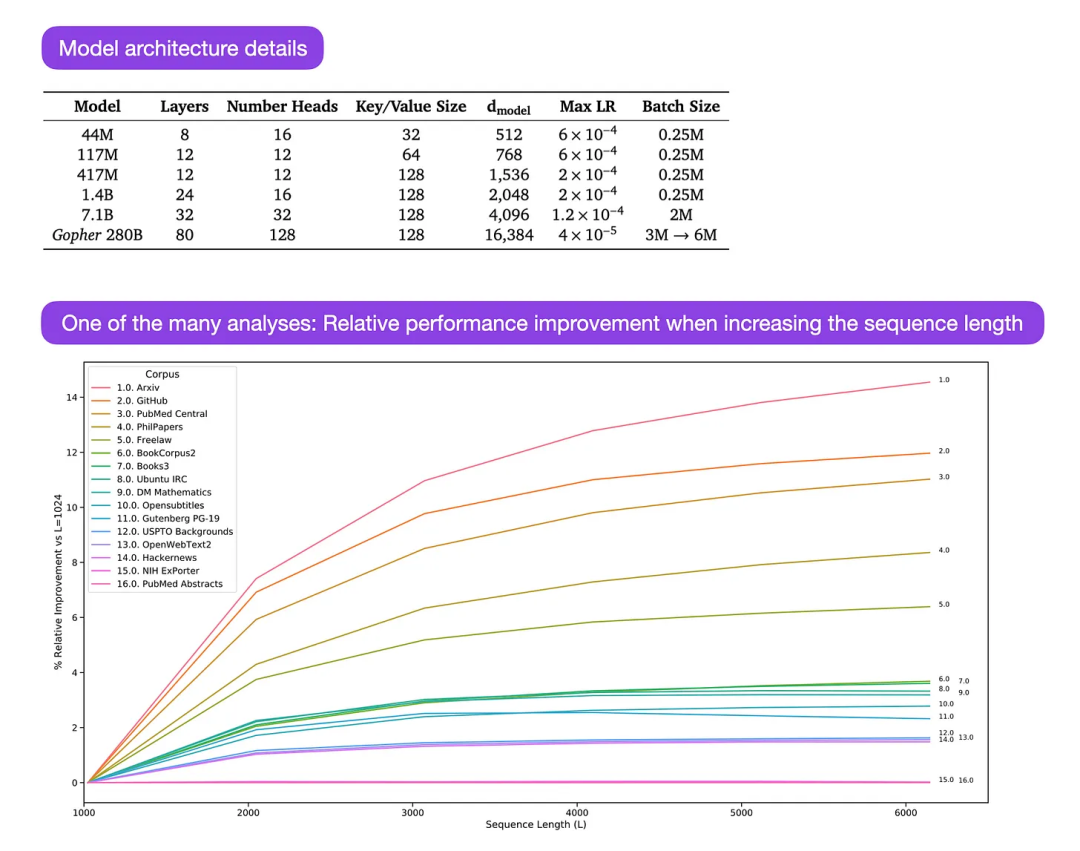
The above is the detailed content of This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
 okx online okx exchange official website online
Apr 22, 2025 am 06:45 AM
okx online okx exchange official website online
Apr 22, 2025 am 06:45 AM
The detailed introduction of OKX Exchange is as follows: 1) Development history: Founded in 2017 and renamed OKX in 2022; 2) Headquartered in Seychelles; 3) Business scope covers a variety of trading products and supports more than 350 cryptocurrencies; 4) Users are spread across more than 200 countries, with tens of millions of users; 5) Multiple security measures are adopted to protect user assets; 6) Transaction fees are based on the market maker model, and the fee rate decreases with the increase in trading volume; 7) It has won many honors, such as "Cryptocurrency Exchange of the Year".
 A list of special services for major virtual currency trading platforms
Apr 22, 2025 am 08:09 AM
A list of special services for major virtual currency trading platforms
Apr 22, 2025 am 08:09 AM
Institutional investors should choose compliant platforms such as Coinbase Pro and Genesis Trading, focusing on cold storage ratios and audit transparency; retail investors should choose large platforms such as Binance and Huobi, focusing on user experience and security; users in compliance-sensitive areas can conduct fiat currency trading through Circle Trade and Huobi Global, and mainland Chinese users need to go through compliant over-the-counter channels.
 Top 10 latest releases of virtual currency trading platforms for bulk transactions
Apr 22, 2025 am 08:18 AM
Top 10 latest releases of virtual currency trading platforms for bulk transactions
Apr 22, 2025 am 08:18 AM
The following factors should be considered when choosing a bulk trading platform: 1. Liquidity: Priority is given to platforms with an average daily trading volume of more than US$5 billion. 2. Compliance: Check whether the platform holds licenses such as FinCEN in the United States, MiCA in the European Union. 3. Security: Cold wallet storage ratio and insurance mechanism are key indicators. 4. Service capability: Whether to provide exclusive account managers and customized transaction tools.
 A list of top ten virtual currency trading platforms that support multiple currencies
Apr 22, 2025 am 08:15 AM
A list of top ten virtual currency trading platforms that support multiple currencies
Apr 22, 2025 am 08:15 AM
Priority is given to compliant platforms such as OKX and Coinbase, enabling multi-factor verification, and asset self-custody can reduce dependencies: 1. Select an exchange with a regulated license; 2. Turn on the whitelist of 2FA and withdrawals; 3. Use a hardware wallet or a platform that supports self-custody.
 Recommended top 10 for easy access to digital currency trading apps (latest ranking in 25)
Apr 22, 2025 am 07:45 AM
Recommended top 10 for easy access to digital currency trading apps (latest ranking in 25)
Apr 22, 2025 am 07:45 AM
The core advantage of gate.io (global version) is that the interface is minimalist, supports Chinese, and the fiat currency trading process is intuitive; Binance (simplified version) has the highest global trading volume, and the simple version model only retains spot trading; OKX (Hong Kong version) has the simple version of the interface is simple, supports Cantonese/Mandarin, and has a low threshold for derivative trading; Huobi Global Station (Hong Kong version) has the core advantage of being an old exchange, launches a meta-universe trading terminal; KuCoin (Chinese Community Edition) has the core advantage of supporting 800 currencies, and the interface adopts WeChat interaction; Kraken (Hong Kong version) has the core advantage of being an old American exchange, holding a Hong Kong SVF license, and the interface is simple; HashKey Exchange (Hong Kong licensed) has the core advantage of being a well-known licensed exchange in Hong Kong, supporting France
 Tips and recommendations for the top ten market websites in the currency circle 2025
Apr 22, 2025 am 08:03 AM
Tips and recommendations for the top ten market websites in the currency circle 2025
Apr 22, 2025 am 08:03 AM
Domestic user adaptation solutions include compliance channels and localization tools. 1. Compliance channels: Franchise currency exchange through OTC platforms such as Circle Trade, domestically, they need to go through Hong Kong or overseas platforms. 2. Localization tools: Use the currency circle network to obtain Chinese information, and Huobi Global Station provides a meta-universe trading terminal.
 Summary of the top ten Apple version download portals for digital currency exchange apps
Apr 22, 2025 am 09:27 AM
Summary of the top ten Apple version download portals for digital currency exchange apps
Apr 22, 2025 am 09:27 AM
Provides a variety of complex trading tools and market analysis. It covers more than 100 countries, has an average daily derivative trading volume of over US$30 billion, supports more than 300 trading pairs and 200 times leverage, has strong technical strength, a huge global user base, provides professional trading platforms, secure storage solutions and rich trading pairs.
