

What are the optimization techniques for mysql database?

1. Optimize your queries for query caching
Most MySQL servers have query caching enabled. This is one of the most effective ways to improve performance, and it's handled by the MySQL database engine. When many of the same queries are executed multiple times, these query results will be placed in a cache, so that subsequent identical queries do not need to operate the table but directly access the cached results.
The main problem here is that for programmers, this matter is easily overlooked. Because some of our query statements will cause MySQL not to use caching . Please look at the following example:

The difference between the above two SQL statements is
CURDATE(), MySQL’s query cache pair This function doesn't work. Therefore, SQL functions likeNOW()andRAND()or other similar functions will not enable query caching, because the returns of these functions are volatile. So, all you need is to replace the MySQL function with a variable to enable caching.
2. EXPLAIN your SELECT query
Use the
EXPLAINkeyword to let you know how MySQL processes your SQL statement of. This can help you analyze the performance bottlenecks of your query statements or table structures. The query results ofEXPLAINwill also tell you how your index primary key is used, how your data table is searched and sorted...etc., etc.
Pick one of yourSELECTstatements (it is recommended to choose the most complex one with multiple table connections) and add the keywordEXPLAINto the front. You can usephpmyadminto do this. Then, you will see a form. In the following example, we forgot to add thegroup_idindex and have a table join:
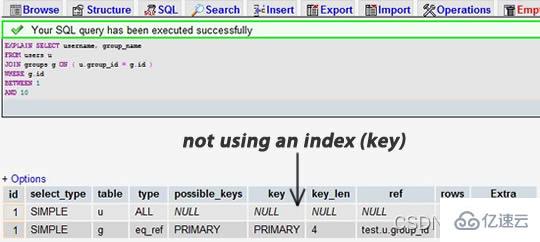
When we add the After indexing: 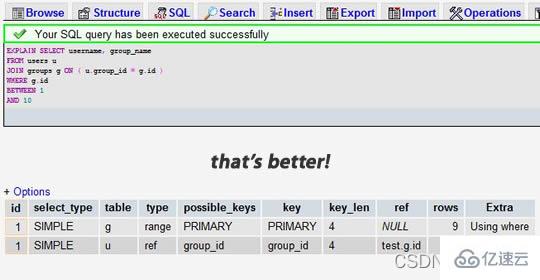
We can see that the former result shows that 7883 rows were searched, while the latter one only searched 9 and 16 rows of the two tables. Looking at the rows column allows us to find potential performance issues.
3. Use LIMIT 1 1 when there is only one row of data
Sometimes when you query the table, you already know that the result will only be one result, but because you may need to
fetchCursor, or you might check the number of records returned.
In this case, addingLIMIT 1can increase performance. In this way, the MySQL database engine will stop searching after finding a piece of data, instead of continuing to search for the next piece of data that matches the record.
The following example is just to find whether there are "China" users. Obviously, the latter one will be more efficient than the previous one. (Please note that the first entry isSelect *and the second entry isSelect 1)
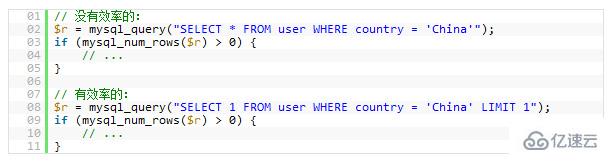
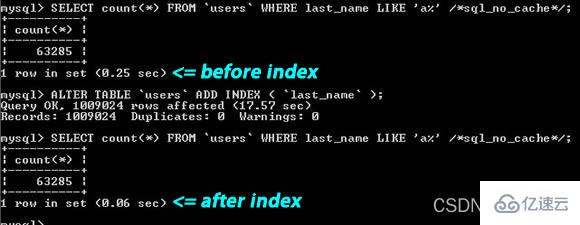
From the picture above You can see that the search string "5. Use the same type of example when joining the tablelast_name LIKE 'a%
'", one is indexed, the other is not indexed, the performance isabout 4 times worse. In addition, you should also need to know what kind of searches cannot use normal indexes. For example, when you need to search for a word in a large article, such as: "
WHERE post_content LIKE '%apple%'", the index may not make sense. You may need to use the MySQL full-text index or make an index yourself (for example: search for keywords or tags)
If your application has many JOIN queries, you should confirm that the Join fields in both tables are indexed. In this way, MySQL will start a mechanism internally to optimize the Join SQL statement for you.Moreover, these fields used for Join should be of the same type. For example: If you want to
DECIMALfield and an INT fieldJointogether, MySQL cannot use their indexes. For thoseSTRINGtypes, they also need to have the same character set. (The character sets of the two tables may be different)

6. Never ORDER BY RAND()
Want to disrupt the returned data rows? Pick a piece of data at random? I really don’t know Who invented this usage, but many novices like to use it this way. But you really don't understand what a terrible performance problem this has.
If you really want to scramble the returned data rows, you have N ways to achieve this. Using this will only cause your database performance to drop exponentially. The problem here is: MySQL will have to execute theRAND()function (which consumes a lot of CPU time), and this is to record the rows for each row of records, and then sort them. Even if you useLimit 1it won’t help (because it needs to be sorted)
The following example randomly selects a record: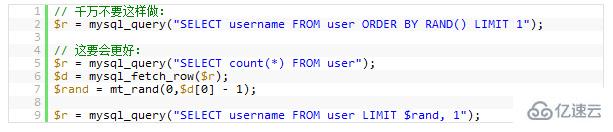
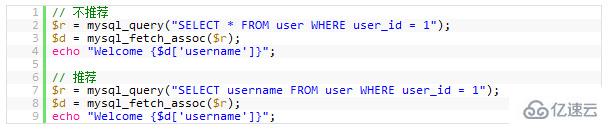
7. Avoid SELECT *
8. Always set an ID for each tableThe more data is read from the database, the slower the query will become. Moreover, if your database server and WEB server are two independent servers, this will also increase the load of network transmission. Therefore, you should develop a good habit of taking whatever you need.
We should set an ID for each table in the database as its Primary key, and the best one is of type9. Use ENUM instead of VARCHARINT
(it is recommended to useUNSIGNED), and set the automatically increasedAUTO_INCREMENTflag.Even if your users table has a field with a primary key called "", don't make it the primary key. Using theVARCHARtype as the primary key will degrade performance. Additionally, in your program, you should use table IDs to construct your data structures.Moreover, under the MySQL data engine, there are some operations that require the use of primary keys. In these cases,
The performance and settings of primary keys become very important, such as clusters, partitions... Here, there is only one exception, and that is the "foreign key" of the "associated table". That is to say, the primary key of this table is composed of the primary keys of several individual tables. We call this situation "foreign key". For example: there is a "student table" with student IDs, and a "curriculum table" with course IDs. Then, the "score table" is an "association table", which associates the student table and course schedule. In the score table, The student ID and course ID are called "foreign keys" and together they form the primary key.
The ENUM type is very fast and compact. In fact, it saves10. Get suggestions from PROCEDURE ANALYSE()TINYINT
, but it appears as a string. In this way, it becomes quite perfect to use this field to make some choice lists.If you have a field, such as "gender", "country", "ethnicity", "status" or "department", and you know that the values of these fields are limited and fixed, then you should use
ENUMinstead ofVARCHAR.MySQL also has a "suggestion" (see item 10) to tell you how to reorganize your table structure. When you have a
VARCHARfield, this suggestion will tell you to change it to theENUMtype. UsePROCEDURE ANALYSE()You can get relevant suggestions
PROCEDURE ANALYSE( )
will let MySQL help you analyze your fields and their actual data, and give you some useful suggestions. These suggestions will only become useful if there is actual data in the table, because making some big decisions requires data as a basis.For example, if you create an INT field as your primary key, but there is not much data, then
PROCEDURE ANALYSE()will suggest that you change the type of this field toMEDIUMINT. Or if you use aVARCHARfield, because there is not much data, you may get a suggestion to change itto
ENUM. These suggestions are all possible because there is not enough data, so the decision-making is not accurate enough.In
phpmyadmin, you can click"Propose table structure"when viewing the table to view these suggestions
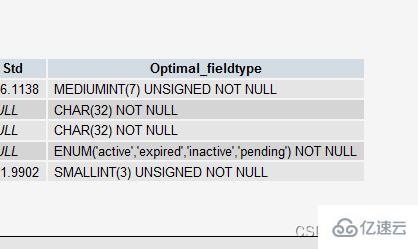
You are the one who makes the final decision
11. Use NOT NULL whenever possible
Unless you have a very specific reason to use a
NULLvalue, you should always keep your fieldsNOT NULL. This may seem a bit controversial, please read on.
First, ask yourself how big the difference is between "Empty" and "NULL" (if it'sINT, that's 0 and NULL)? If you think there is no difference between them, then you should not useNULL. (Did you know? In Oracle, the strings ofNULLandEmptyare the same!)
Don’t think thatNULLNo need for space, it requires extra space , and your program will be more complex when you do comparisons. Of course, this does not mean that you cannot useNULL. The reality is very complicated, and there will still be situations where you need to use NULL values.
12.Prepared Statements
Prepared StatementsMuch like a stored procedure, it is a collection of SQL statements running in the background. We can useprepared statementsGain many benefits, whether it is a performance issue or a security issue .Prepared StatementsYou can check some variables that you have bound, which can protect your program from "SQL injection" attacks. Of course, you can also manually check your variables. However, manual checks are prone to problems and are often forgotten by programmers. When we use someframeworkorORM, this problem will be better.
In terms of performance, when the same query is used multiple times, this will bring you considerable performance advantages. You can define some parameters for thesePrepared Statements, and MySQL will only parse them once.
Although the latest version of MySQL usesbinary formwhen transmitting Prepared Statements, this will make network transmission very efficient.
Of course, there are some cases where we need to avoid usingPrepared Statementsbecause it does not support query caching. But it is said to be supported after version 5.1.
To use prepared statements in PHP, you can check its manual: mysql extension or use the database abstraction layer, such as: PDO.
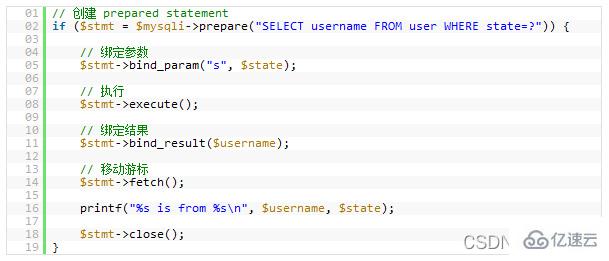
13 . Unbuffered query
Normally, when you execute a SQL statement in your script, your program will stop there until the SQL statement returns. Then your program continues to execute. You can use unbuffered queries to change this behavior.
mysql_unbuffered_query()Sends a SQL statement to MySQL without automaticallyfethchand caching the results likemysql_query(). This will save a lot of considerable memory, especially for queries that generate a large number of results, and you don't need to wait until all the results are returned. You only need to return the first row of data and you can start working immediately. The query results are up.
However, this will have some limitations. Because you either have to read all the rows, or you have to callmysql_free_result()to clear the results before the next query. Moreover,mysql_num_rows() or mysql_data_seek()will not work. Therefore, you need to consider carefully whether to use unbuffered queries.
14. Save the IP address as UNSIGNED INT
Many programmers will create a
VARCHAR(15)field to store the string form IP instead of shaped IP. If you use an integer to store it, it only takes 4 bytes, and you can have fixed-length fields. Moreover, this will bring you query advantages, especially when you need to use suchWHEREconditions:IP between ip1 and ip2.
We must useUNSIGNED INT, because the IP address uses the entire 32-bit unsigned integer type.
As for your query, you can useINET_ATON()to convert a string IP into an integer, and useINET_NTOA()to convert an integer into a string IP. In PHP, there are also such functionsip2long() and long2ip().

15. Fixed-length tables will be faster
If all fields in the table are "fixed length", the entire table will be considered "
static" or "fixed-length". For example, there are no fields of the following types in the table:VARCHAR, TEXT. As long as you include one of these fields, the table is no longer a "fixed-length static table" and the MySQL engine will process it in another way.
Fixed length tables will improve performance because MySQL will search faster. Because these fixed lengths make it easy to calculate the offset of the next data, reading will naturally be faster. And if the field is not of fixed length, then every time you want to find the next one, the program needs to find the primary key.
Also, fixed-length tables are easier to cache and rebuild. However, The only side effect is that fixed-length fields will waste some space, because fixed-length fields will allocate so much space whether you use them or not.
Using the "vertical split" technology (see next item), you can split your table into two, one with a fixed length and one with a variable length of.
16. Vertical split
"Vertical split" is a method of converting the tables in the database into several tables by columns, which can reduce the complexity and fields of the table number, so as to achieve the purpose of optimization. (Before, I worked on a project in a bank and saw a table with more than 100 fields, which was scary)
Example 1: There is a field in the Users table that is home address. This The field is an optional field, in comparison, and except for personal information when you operate in the database, you do not need to read or rewrite this field frequently. So, why not put it in another table? This will make your table have better performance. Think about it, a lot of times, for the user table, I only have the user ID, user name, and password. , user roles, etc. will be used frequently. Smaller watches will always have better performance.
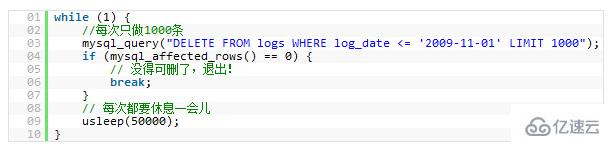
Example 2: You have a field called "last_login" that will be updated every time the user logs in. However, each update will cause the table's query cache to be cleared. Therefore, you can put this field in another table, so that it will not affect your continuous reading of user ID, user name, and user role, because the query cache will help you increase a lot of performance.In addition, you need to pay attention to the fact that you will not join the tables formed by these separated fields frequently. Otherwise, the performance will be worse than without splitting. It is worse, and it will be an extreme drop17. Split a large DELETE or INSERT statement
If you need to execute a large statement on an online websiteDELETE
orINSERTquery, you need to be very careful to avoid your operation causing your entire website to stop responding. Because these two operations will lock the table, once the table is locked, no other operations can enter.Apache will have many child processes or threads. Therefore, it works quite efficiently, and our server does not want to have too many child processes, threads and database links. This takes up a lot of server resources, especially memory.
If you lock your table for a period of time, such as 30 seconds, then for a site with a high traffic volume, the number of access processes/threads, database links, and open files accumulated in these 30 seconds , it may not only cause your WEB service to
Crash, but may also cause your entire server to hang up immediately.So, if you have a large process and you are sure to split it up, using
LIMITconditions is a good way. Here is an example:
For most database engines, Hard drive operations are probably the most significant bottleneck. So, making your data compact can be very helpful in this situation because it reduces access to the hard drive.See MySQL documentation
Storage Requirementsto view all data types.If a table only has a few columns (such as dictionary table, configuration table), then we have no reason to use
INTas the primary key, useMEDIUMINT, SMALLINTOr a smaller TINYINT would be more economical. If you don't need to record time, it's much better to useDATEthanDATETIME.Of course, you also need to leave enough room for expansion, otherwise, if you do this in the future, you will die ugly. See the example of
Slashdot(November 06, 2009), A simpleALTER TABLEstatement took more than 3 hours because there were 16 million pieces of data in it.
19. Choose the right storage engine
There are two storage engines in MySQL, MyISAM and InnoDB. Each engine has advantages and disadvantages. Cool Shell's previous article "MySQL: InnoDB or MyISAM?" discussed this matter.
MyISAM is suitable for applications that require a large number of queries, but it is not very good for a large number of write operations. Even if you just need to update a field, the entire table will be locked, and other processes, even the reading process, cannot operate until the reading operation is completed. In addition, MyISAM is extremely fast for calculations such asSELECT COUNT(*).
The trend of InnoDB will be a very complex storage engine. For some small applications, it will be slower thanMyISAM. The other reason is that it supports "row locking", so it will be better when there are more write operations. Moreover, it also supports more advanced applications, such as transactions.
20. Use an Object Relational Mapper
Using an ORM (
Object Relational Mapper), you can get reliable Performance increases. Everything an ORM can do can also be written manually. However, this requires a high-level expert. The most important thing about
ORM is "Lazy Loading", that is to say, it will only be actually done when it is necessary to get the value. But you also need to be careful about the side effects of this mechanism, because it is likely to reduce performance by creating many, many small queries.
ORM can also package your SQL statements into a transaction, which is much faster than executing them individually.
Currently, my favorite ORM for PHP is:Doctrine
21. Be careful of "permanent links"
"permanent links" The purpose is to reduce the number of re-creation of MySQL connections. When a link is created, it remains connected forever, even after the database operation has ended. Moreover, since our Apache started reusing its child process - that is, the next HTTP request will reuse the Apache child process and reuse the same MySQL connection.
In theory, this sounds very good. But from personal experience (and most people's), this feature creates more trouble. Because, you only have a limited number of links, memory issues, file handles, etc.
Moreover, Apache runs in an extremely parallel environment and will create many, many processes. This is why this "permalink" mechanism doesn't work well. Before you decide to use "permanent links", you need to carefully consider the architecture of your entire system
22. SQL optimization index optimization
1. Independent columns
When querying, the index column cannot be part of the expression or the parameter of the function, otherwise the index cannot be used.
For example, the following query cannot use the index of the actor_id column:
#这是错误的SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
Optimization method: Expressions and function operations can be moved to the right side of the equal sign. As follows:
SELECT actor_id FROM sakila.actor WHERE actor_id = 5 - 1;
2. Multi-column index
When multiple columns need to be used as conditions for query, using a multi-column index has better performance than using multiple single-column indexes.
For example, in the following statement, it is best to set actor_id and film_id as multi-column indexes. Yuanfudao has a question, see the link for details, which can help you understand more deeply.
SELECT film_id, actor_ id FROM sakila.film_actorWHERE actor_id = 1 AND film_id = 1;
3. The order of index columns
Let the most selective index column be placed first.
The selectivity of the index refers to the ratio of unique index values to the total number of records. The maximum value is 1, at which time each record has a unique index corresponding to it. The higher the selectivity, the higher the discrimination of each record and the higher the query efficiency.
For example, in the results shown below, customer_id is more selective than staff_id, so it is best to put the customer_id column in front of the multi-column index.
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity, COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity, COUNT(*) FROM payment; #结果如下 staff_id_selectivity: 0.0001 customer_id_selectivity: 0.0373 COUNT(*): 16049
4. Prefix index
For BLOB, TEXT and VARCHAR type columns, you must use a prefix index, which only indexes the beginning characters.
The selection of prefix length needs to be determined based on index selectivity.
5. Covering index
The index contains the values of all fields that need to be queried. It has the following advantages:
1. The index is usually much smaller than the size of the data row. Reading only the index can greatly reduce the amount of data access.
2. Some storage engines (such as MyISAM) only cache indexes in memory, and the data relies on the operating system to cache. Therefore, accessing only the index eliminates the need for system calls (which are often time consuming).
3. For the InnoDB engine, if the auxiliary index can cover the query, there is no need to access the primary index.
6. Prioritize the use of indexes to avoid full table scans
mysql puts % behind when using like for fuzzy queries to avoid fuzzy queries at the beginning
Because MySQL will use the index only when using the following % when using like query.
For example: '%ptd_' and '%ptd_%' do not use indexes; but 'ptd_%' uses indexes.
#进行全表查询,没有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_%'; EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_'; #有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE 'ptd_%';
Another example: a commonly used query for all the people with the surname Zhang in the database:
SELECT * FROM `user` WHERE username LIKE '张%';
7.尽量避免使用in 和not in,会导致数据库引擎放弃索引进行全表扫描。
比如:
SELECT * FROM t WHERE id IN (2,3)SELECT * FROM t1 WHERE username IN (SELECT username FROM t2)
优化方式:如果是连续数值,可以用between代替。如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3
如果是子查询,可以用exists代替。如下:
SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 WHERE t1.username = t2.username)
8.尽量避免使用or,会导致数据库引擎放弃索引进行全表扫描
如:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1UNIONSELECT * FROM t WHERE id = 3
9.尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
10.尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描
同第1个,单独的列;
SELECT * FROM t2 WHERE score/10 = 9SELECT * FROM t2 WHERE SUBSTR(username,1,2) = 'li'
优化方式:可以将表达式、函数操作移动到等号右侧。如下:
SELECT * FROM t2 WHERE score = 10*9SELECT * FROM t2 WHERE username LIKE 'li%'
11.当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描
SELECT * FROM t WHERE 1=1
优化方式:用代码拼装sql时进行判断,没where加where,有where加and。
索引的好处:建立索引后,查询时不会扫描全表,而会查询索引表锁定结果。索引的缺点:在数据库进行DML操作的时候,除了维护数据表之外,还需要维护索引表,运维成本增加。应用场景:数据量比较大,查询字段较多的情况。
索引规则:
1.选用选择性高的字段作为索引,一般unique的选择性最高;
2.复合索引:选择性越高的排在越前面。(左前缀原则);
3.如果查询条件中两个条件都是选择性高的,最好都建索引;
23.SQL优化之查询优化
1.使用Explain进行分析
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
比较重要的字段有:
select_type: 查询类型,有简单查询、联合查询、子查询等;key: 使用的索引;rows: 扫描的行数;
2.优化数据访问
1.减少请求的数据量
只返回必要的列:最好不要使用
SELECT *语句。
只返回必要的行:使用LIMIT语句来限制返回的数据。
缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
2.减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
3.重构查询方式
1.切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
2.分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
让缓存更高效:对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
减少锁竞争;
在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
SELECT * FROM tab JOIN tag_post ON tag_post.tag_id=tag.id JOIN post ON tag_post.post_id=post.id WHERE tag.tag='mysql'; SELECT * FROM tag WHERE tag='mysql'; SELECT * FROM tag_post WHERE tag_id=1234; SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
24.分析查询语句
通过对查询语句的分析,可以了解查询语句执行的情况,找出查询语句执行的瓶颈,从而优化查询语句。mysql中提供了EXPLAIN语句和
DESCRIBE语句,用来分析查询语句。EXPLAIN语句的基本语法如下:
EXPLAIN [EXTENDED] SELECT select_options;
使用EXTENED关键字,EXPLAIN语句将产生附加信息。select_options是select语句的查询选项,包括from where子句等等。
执行该语句,可以分析EXPLAIN后面的select语句的执行情况,并且能够分析出所查询的表的一些特征。
例如:EXPLAIN SELECT * FROM user;
查询结果进行解释说明:
a、id:select识别符,这是select的查询序列号。
b、select_type:标识select语句的类型。
它可以是以下几种取值:
b1、SIMPLE(simple)表示简单查询,其中不包括连接查询和子查询。
b2、PRIMARY(primary)表示主查询,或者是最外层的查询语句。
b3、UNION(union)表示连接查询的第2个或者后面的查询语句。
b4、DEPENDENT UNION(dependent union)连接查询中的第2个或者后面的select语句。取决于外面的查询。
b5、UNION RESULT(union result)连接查询的结果。
b6、SUBQUERY(subquery)子查询的第1个select语句。
b7、DEPENDENT SUBQUERY(dependent subquery)子查询的第1个select,取决于外面的查询。
b8、DERIVED(derived)导出表的SELECT(FROM子句的子查询)。
c、table:表示查询的表。
d、type:表示表的连接类型。
下面按照从最佳类型到最差类型的顺序给出各种连接类型。
d1、system,该表是仅有一行的系统表。这是const连接类型的一个特例。
d2、const,数据表最多只有一个匹配行,它将在查询开始时被读取,并在余下的查询优化中作为常量对待。const表查询速度很快,因为它们只读一次。const用于使用常数值比较primary key或者unique索引的所有部分的场合。
例如:EXPLAIN SELECT * FROM user WHERE id=1;
d3、eq_ref,对于每个来自前面的表的行组合,从该表中读取一行。当一个索引的所有部分都在查询中使用并且索引是UNIQUE或者PRIMARY KEY时候,即可使用这种类型。eq_ref可以用于使用“=”操作符比较带索引的列。比较值可以为常量或者一个在该表前面所读取的表的列的表达式。
例如:EXPLAIN SELECT * FROM user,db_company WHERE user.company_id = db_company.id;
d4、ref对于来自前面的表的任意行组合,将从该表中读取所有匹配的行。这种类型用于所以既不是UNION也不是primaey key的情况,或者查询中使用了索引列的左子集,即索引中左边的部分组合。ref可以用于使用=或者操作符的带索引的列。
d5、ref_or_null,该连接类型如果ref,但是如果添加了mysql可以专门搜索包含null值的行,在解决子查询中经常使用该连接类型的优化。
d6、index_merge,该连接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
d7、unique_subquery,该类型替换了下面形式的in子查询的ref。是一个索引查询函数,可以完全替代子查询,效率更高。
d8、index_subquery,该连接类型类似于unique_subquery,可以替换in子查询,但是只适合下列形式的子查询中非唯一索引。
d9、range,只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。key_len包含所使用索引的最长关键元素。当使用=,,>,>=,,between或者in操作符,用常量比较关键字列时,类型为range。
d10、index,该连接类型与all相同,除了只扫描索引树。着通常比all快,引文索引问价通常比数据文件小。
d11、all,对于前面的表的任意行组合,进行完整的表扫描。如果表是第一个没有标记const的表,这样不好,并且在其他情况下很差。通常可以增加更多的索引来避免使用all连接。
e、possible_keys:possible_keys列指出mysql能使用那个索引在该表中找到行。如果该列是null,则没有相关的索引。在这种情况下,可以通过检查where子句看它是否引起某些列或者适合索引的列来提高查询性能。如果是这样,可以创建适合的索引来提高查询的性能。
f.key: Indicates the index actually used in the query. If no index is selected, the value of this column is null. To force mysql to use or ignore the index in the possible_key column, usein the query. force index, use index or ignore index.
g,key_len: Indicates the length of the mysql selected index field calculated in bytes. If the key is null, the length is null. Note that the key_len value determines how many fields in a multi-column index mysql will actually use.
h,ref: Indicates which column, constant or index to use to query records.
i,rows: Displays the number of rows that MySQL must check when querying in the table.
j,Extra: The detailed information of this column when mysql processes the query.
The above is the detailed content of What are the optimization techniques for mysql database?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1244
24
14
1423
52
1317
25
1268
29
1244
24

 MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
The main role of MySQL in web applications is to store and manage data. 1.MySQL efficiently processes user information, product catalogs, transaction records and other data. 2. Through SQL query, developers can extract information from the database to generate dynamic content. 3.MySQL works based on the client-server model to ensure acceptable query speed.
 Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel is a PHP framework for easy building of web applications. It provides a range of powerful features including: Installation: Install the Laravel CLI globally with Composer and create applications in the project directory. Routing: Define the relationship between the URL and the handler in routes/web.php. View: Create a view in resources/views to render the application's interface. Database Integration: Provides out-of-the-box integration with databases such as MySQL and uses migration to create and modify tables. Model and Controller: The model represents the database entity and the controller processes HTTP requests.
 MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin are powerful database management tools. 1) MySQL is used to create databases and tables, and to execute DML and SQL queries. 2) phpMyAdmin provides an intuitive interface for database management, table structure management, data operations and user permission management.
 MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
Compared with other programming languages, MySQL is mainly used to store and manage data, while other languages such as Python, Java, and C are used for logical processing and application development. MySQL is known for its high performance, scalability and cross-platform support, suitable for data management needs, while other languages have advantages in their respective fields such as data analytics, enterprise applications, and system programming.
 Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
I encountered a tricky problem when developing a small application: the need to quickly integrate a lightweight database operation library. After trying multiple libraries, I found that they either have too much functionality or are not very compatible. Eventually, I found minii/db, a simplified version based on Yii2 that solved my problem perfectly.
 Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Article summary: This article provides detailed step-by-step instructions to guide readers on how to easily install the Laravel framework. Laravel is a powerful PHP framework that speeds up the development process of web applications. This tutorial covers the installation process from system requirements to configuring databases and setting up routing. By following these steps, readers can quickly and efficiently lay a solid foundation for their Laravel project.
 MySQL for Beginners: Getting Started with Database Management
Apr 18, 2025 am 12:10 AM
MySQL for Beginners: Getting Started with Database Management
Apr 18, 2025 am 12:10 AM
The basic operations of MySQL include creating databases, tables, and using SQL to perform CRUD operations on data. 1. Create a database: CREATEDATABASEmy_first_db; 2. Create a table: CREATETABLEbooks(idINTAUTO_INCREMENTPRIMARYKEY, titleVARCHAR(100)NOTNULL, authorVARCHAR(100)NOTNULL, published_yearINT); 3. Insert data: INSERTINTObooks(title, author, published_year)VA
 Solve MySQL mode problem: The experience of using the TheliaMySQLModesChecker module
Apr 18, 2025 am 08:42 AM
Solve MySQL mode problem: The experience of using the TheliaMySQLModesChecker module
Apr 18, 2025 am 08:42 AM
When developing an e-commerce website using Thelia, I encountered a tricky problem: MySQL mode is not set properly, causing some features to not function properly. After some exploration, I found a module called TheliaMySQLModesChecker, which is able to automatically fix the MySQL pattern required by Thelia, completely solving my troubles.
