

How to use Redis to implement search interface

For back-end developers, a single SQl can be used to implement the list query interface. If the query conditions are complex and the table database design is unreasonable, the query will be difficult. This article will share with you how to use Redis to implement search. interface.
Let’s start with an example. This is the search condition of a shopping website. If you were asked to implement such a search interface, how would you implement it?
Of course you said with the help of search engines, like Elasticsearch and the like, you can definitely do it. But what I want to say here is, what if you want to implement it yourself?

As you can see from the picture above, search is divided into 6 categories in total, and each category Divided into various subcategories.
In this case, the filtering process takes the intersection of the major categories of conditions and considers single selection, multi-selection and customization in each subcategory to output a result set that meets the conditions.
Okay, now that the requirements are clear, let’s start implementing them.
Implementation 1
The first to appear is student A. He is an "expert" in writing SQL. Little A said confidently: "Isn't it just a query interface? There are many conditions, but with my rich SQL experience, this is not a problem for me."
So I wrote The following code came out (taking MySQL as an example here):
select ... from table_1 left join table_2 left join table_3 left join (select ... from table_x where ...) tmp_1 ... where ... order by ... limit m,n
The code was run in the test environment, and the results seemed to match, so I prepared to pre-release it. With this pre-launch, problems began to emerge.
The pre-release is to make the online environment as realistic as possible, so the amount of data is naturally much larger than that of the test. So for such a complex SQL, its execution efficiency can be imagined. The test classmate decisively typed back the code of Little A.
Implementation 2
Summarizing the lessons learned from the failure of Little A, Little B began to optimize SQL. First, it passed the explain keyword for SQL performance analysis. Indexes are added wherever indexes are added.
Split a complex SQL into multiple SQLs at the same time, and the calculation results are calculated in the program memory.
The pseudo code is as follows:
$result_1 = query('select ... from table_1 where ...');
$result_2 = query('select ... from table_2 where ...');
$result_3 = query('select ... from table_3 where ...');
...
$result = array_intersect($result_1, $result_2, $result_3, ...);This solution is obviously much better than the first one in terms of performance, but during function acceptance, the product manager still feels that the query speed is not fast enough.
Little B himself also knows that each query will query the database multiple times, and for some historical reasons, single-table query cannot be performed under some conditions, so the waiting time for queries is unavoidable.
Implementation 3
Little C saw room for optimization from the above solution. He found that Little B had no problem with his thinking. He split the complex conditions, calculated the result sets of each sub-dimension, and finally summarized and merged all the sub-result sets to get the final desired result.
So he suddenly thought about whether he could cache the result sets of each sub-dimension in advance. This would allow him to directly fetch the desired subset when querying, without having to check the database for calculation every time.
Here Little C uses Redis to store cache data. The main reason for using it is that it provides a variety of data structures, and it is very easy to perform intersection and union operations on sets in Redis.
The specific plan is as shown in the figure:
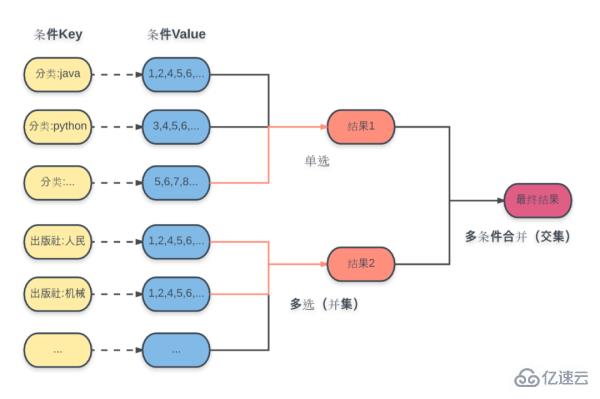
For each condition here, the calculated result set ID is stored in the corresponding Key in advance and selected. The data structure is a set (Set).
Query operations include:
- ##Subcategory radio selection: directly based on the condition Key, Get the corresponding result set.
- Sub-category multiple selection: perform a union operation based on multiple condition Keys to obtain the corresponding result set.
- Final result: Perform an intersection operation on all obtained subcategory result sets to obtain the final result.
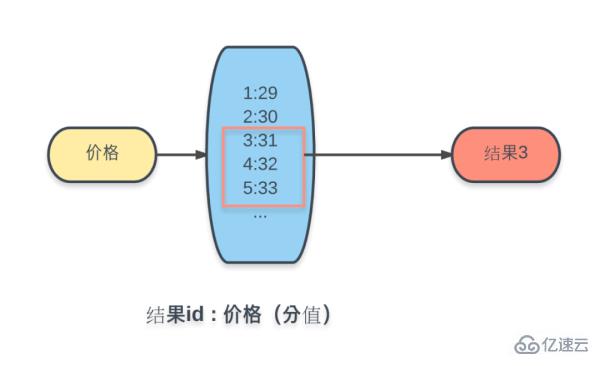
Extension
①Paging
You may have discovered a serious functional flaw here. How can list queries be without paging? . Yes, let's take a look right away at how Redis implements paging.Paging mainly involves sorting. For the sake of simplicity, let’s take the creation time as an example. As shown in the figure:
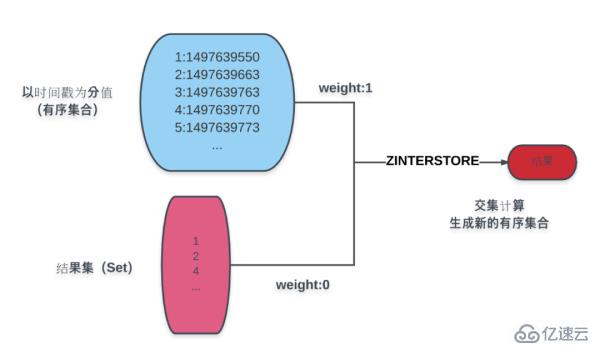
The blue part in the figure is an ordered collection of products based on creation time. The result set below the blue is the conditional calculation. As a result, through the ZINTERSTORE command, the result set weight is assigned to 0, the product time result is 1, and the result set obtained by taking the intersection is assigned to a new ordered set of creation time scores.
The operation on the new result set can obtain the various data required for paging:
The total number of pages is: ZCOUNT command.
Current page content: ZRANGE command.
If arranged in reverse order: ZREVRANGE command.
②Data update
Regarding the issue of index data update, there are two ways to proceed. One is to trigger the update operation immediately through the modification of product data, and the other is to perform batch updates through scheduled scripts.
What should be noted here is that regarding the update of index content, if the Key is violently deleted, the Key must be reset.
Because the two operations in Redis will not be performed atomically, there may be gaps in the middle. It is recommended to only remove the invalid elements in the collection and add new elements.
③Performance Optimization
Redis is a memory-level operation, so a single query will be very fast. However, if multiple Redis operations are performed in our implementation, the multiple Redis connection times may be unnecessary time consumption.
By using the MULTI command, start a transaction, put multiple Redis operations into one transaction, and finally perform atomic execution through EXEC.
Note: The so-called transaction here only executes multiple operations in one connection. If a failure occurs during execution, it will not be rolled back.
Summary
This is just a simple demo using Redis to optimize query search. Compared with existing open source search engines, it is more lightweight and requires less learning. Correspondingly lower.
Secondly, some of its ideas are similar to open source search engines. If word analysis is added, functions similar to full-text retrieval can also be achieved.
The above is the detailed content of How to use Redis to implement search interface. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
On CentOS systems, you can limit the execution time of Lua scripts by modifying Redis configuration files or using Redis commands to prevent malicious scripts from consuming too much resources. Method 1: Modify the Redis configuration file and locate the Redis configuration file: The Redis configuration file is usually located in /etc/redis/redis.conf. Edit configuration file: Open the configuration file using a text editor (such as vi or nano): sudovi/etc/redis/redis.conf Set the Lua script execution time limit: Add or modify the following lines in the configuration file to set the maximum execution time of the Lua script (unit: milliseconds)
 How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
There are two types of Redis data expiration strategies: periodic deletion: periodic scan to delete the expired key, which can be set through expired-time-cap-remove-count and expired-time-cap-remove-delay parameters. Lazy Deletion: Check for deletion expired keys only when keys are read or written. They can be set through lazyfree-lazy-eviction, lazyfree-lazy-expire, lazyfree-lazy-user-del parameters.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to implement redis counter
Apr 10, 2025 pm 10:21 PM
How to implement redis counter
Apr 10, 2025 pm 10:21 PM
Redis counter is a mechanism that uses Redis key-value pair storage to implement counting operations, including the following steps: creating counter keys, increasing counts, decreasing counts, resetting counts, and obtaining counts. The advantages of Redis counters include fast speed, high concurrency, durability and simplicity and ease of use. It can be used in scenarios such as user access counting, real-time metric tracking, game scores and rankings, and order processing counting.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
