

How to implement Redis BloomFilter Bloom filter

Bloom Filter Concept
A man named Bloom proposed the Bloom filter (English name: Bloom Filter) in 1970. It's actually a long binary vector and a series of random mapping functions. Bloom filters can be used to retrieve whether an element is in a collection. Its advantage is that space efficiency and query time are far higher than those of ordinary algorithms. Its disadvantage is that it has a certain misrecognition rate and difficulty in deletion.
Bloom Filter Principle
The principle of the Bloom filter is that when an element is added to the set, the element is mapped into K points in a bit array through K hash functions. , set them to 1. When retrieving, we only need to look at whether these points are all 1 to (approximately) know whether it is in the set: if any of these points has 0, then the checked element must not be there; if they are all 1, then the checked element Most likely. This is the basic idea of Bloom filter.
The difference between Bloom Filter and single hash function Bit-Map is that Bloom Filter uses k hash functions, and each string corresponds to k bits. Thereby reducing the probability of conflict
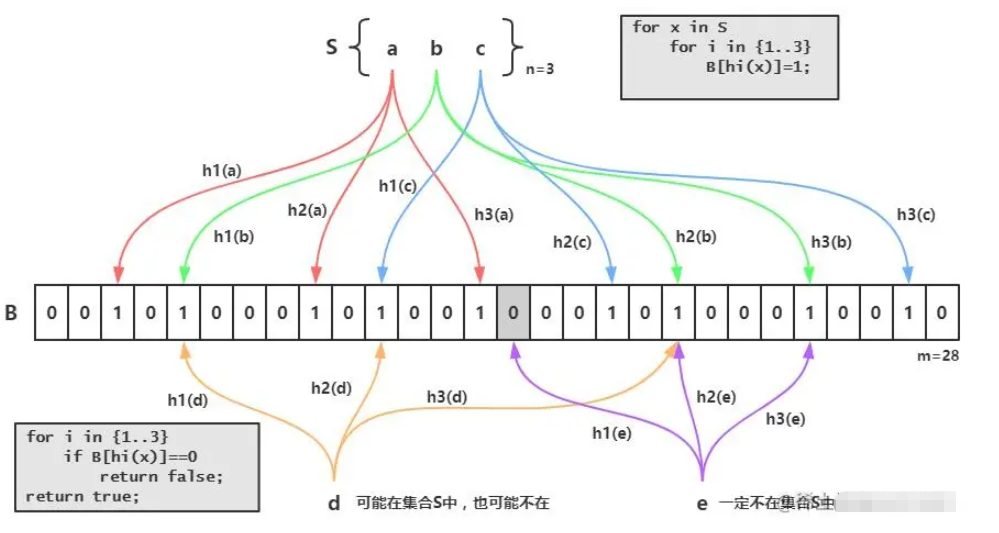
Cache penetration
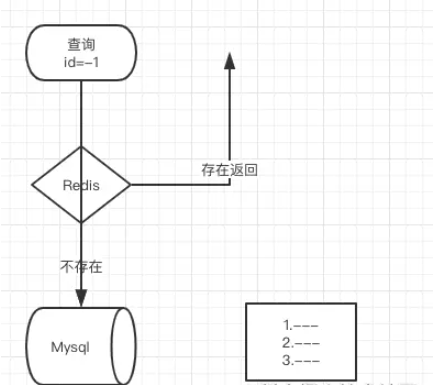
In short, in a nutshell, we first load all the data from our database into our filter. For example, the id of the database now has: 1, 2, 3 Then use id: 1 is an example. After hashing three times in the above picture, he changed the three places where the original value was 0 to 1. The next time the data comes in for query, if the value of id is 1, then I will change it to 1. Take three hashes and find that the values of the three hashes are exactly the same as the three positions above, which can prove that there is 1 in the filter. On the contrary, if they are different, it means that it does not exist So where are the application scenarios? Generally we will use it to prevent cache breakdownTo put it simply, the id of your database starts with 1 and then increases by itself. Then I know that your interface is queried by id, so I will use negative numbers to query. At this time, you will find that the data is not in the cache, and I go to the database to check it, but it is not found. One request is like this, what about 100, 1,000, or 10,000? Basically your DB can't handle it. If you add this to the cache, it will no longer exist. If you judge that there is no such data, you won't check it. Wouldn't it be better to just return the data as empty? If this thing is so good, what are the drawbacks? Yes, let’s go on to see Disadvantages of Bloom FilterThe reason why bloom filter can be more efficient in time and space is because it sacrifices the accuracy of judgment. Convenience of deletionAlthough the container may not contain the elements that should be searched, due to the hash operation, the values of these elements in k hash positions are all 1, so it may lead to misjudgment. By establishing a whitelist to store elements that may be misjudged, when the Bloom Filter stores a blacklist, the misjudgement rate can be reduced. Deletion is difficult. An element placed in the container is mapped to 1 in the k positions of the bit array. When deleting, it cannot be simply set to 0 directly, as it may affect the judgment of other elements. You can use Counting Bloom FilterFAQ1. Why use multiple hash functions? If only one hash function is used, the Hash itself will often conflict. For example, for an array with a length of 100, if only one hash function is used, after adding one element, the probability of conflict when adding the second element is 1%, and the probability of conflict when adding the third element is 2%... But if two elements are used, the probability of collision is 1%. A hash function, after adding an element, the probability of conflict when adding the second element is reduced to 4 out of 10,000 (four possible conflict situations, total number of situations 100x100) go language implementation
package main
import (
"fmt"
"github.com/bits-and-blooms/bitset"
)
//设置哈希数组默认大小为16
const DefaultSize = 16
//设置种子,保证不同哈希函数有不同的计算方式
var seeds = []uint{7, 11, 13, 31, 37, 61}
//布隆过滤器结构,包括二进制数组和多个哈希函数
type BloomFilter struct {
//使用第三方库
set *bitset.BitSet
//指定长度为6
hashFuncs [6]func(seed uint, value string) uint
}
//构造一个布隆过滤器,包括数组和哈希函数的初始化
func NewBloomFilter() *BloomFilter {
bf := new(BloomFilter)
bf.set = bitset.New(DefaultSize)
for i := 0; i < len(bf.hashFuncs); i++ {
bf.hashFuncs[i] = createHash()
}
return bf
}
//构造6个哈希函数,每个哈希函数有参数seed保证计算方式的不同
func createHash() func(seed uint, value string) uint {
return func(seed uint, value string) uint {
var result uint = 0
for i := 0; i < len(value); i++ {
result = result*seed + uint(value[i])
}
//length = 2^n 时,X % length = X & (length - 1)
return result & (DefaultSize - 1)
}
}
//添加元素
func (b *BloomFilter) add(value string) {
for i, f := range b.hashFuncs {
//将哈希函数计算结果对应的数组位置1
b.set.Set(f(seeds[i], value))
}
}
//判断元素是否存在
func (b *BloomFilter) contains(value string) bool {
//调用每个哈希函数,并且判断数组对应位是否为1
//如果不为1,直接返回false,表明一定不存在
for i, f := range b.hashFuncs {
//result = result && b.set.Test(f(seeds[i], value))
if !b.set.Test(f(seeds[i], value)) {
return false
}
}
return true
}
func main() {
filter := NewBloomFilter()
filter.add("asd")
fmt.Println(filter.contains("asd"))
fmt.Println(filter.contains("2222"))
fmt.Println(filter.contains("155343"))
}Copy after login
The output results are as follows:
package main
import (
"fmt"
"github.com/bits-and-blooms/bitset"
)
//设置哈希数组默认大小为16
const DefaultSize = 16
//设置种子,保证不同哈希函数有不同的计算方式
var seeds = []uint{7, 11, 13, 31, 37, 61}
//布隆过滤器结构,包括二进制数组和多个哈希函数
type BloomFilter struct {
//使用第三方库
set *bitset.BitSet
//指定长度为6
hashFuncs [6]func(seed uint, value string) uint
}
//构造一个布隆过滤器,包括数组和哈希函数的初始化
func NewBloomFilter() *BloomFilter {
bf := new(BloomFilter)
bf.set = bitset.New(DefaultSize)
for i := 0; i < len(bf.hashFuncs); i++ {
bf.hashFuncs[i] = createHash()
}
return bf
}
//构造6个哈希函数,每个哈希函数有参数seed保证计算方式的不同
func createHash() func(seed uint, value string) uint {
return func(seed uint, value string) uint {
var result uint = 0
for i := 0; i < len(value); i++ {
result = result*seed + uint(value[i])
}
//length = 2^n 时,X % length = X & (length - 1)
return result & (DefaultSize - 1)
}
}
//添加元素
func (b *BloomFilter) add(value string) {
for i, f := range b.hashFuncs {
//将哈希函数计算结果对应的数组位置1
b.set.Set(f(seeds[i], value))
}
}
//判断元素是否存在
func (b *BloomFilter) contains(value string) bool {
//调用每个哈希函数,并且判断数组对应位是否为1
//如果不为1,直接返回false,表明一定不存在
for i, f := range b.hashFuncs {
//result = result && b.set.Test(f(seeds[i], value))
if !b.set.Test(f(seeds[i], value)) {
return false
}
}
return true
}
func main() {
filter := NewBloomFilter()
filter.add("asd")
fmt.Println(filter.contains("asd"))
fmt.Println(filter.contains("2222"))
fmt.Println(filter.contains("155343"))
}truefalse
false
The above is the detailed content of How to implement Redis BloomFilter Bloom filter. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
On CentOS systems, you can limit the execution time of Lua scripts by modifying Redis configuration files or using Redis commands to prevent malicious scripts from consuming too much resources. Method 1: Modify the Redis configuration file and locate the Redis configuration file: The Redis configuration file is usually located in /etc/redis/redis.conf. Edit configuration file: Open the configuration file using a text editor (such as vi or nano): sudovi/etc/redis/redis.conf Set the Lua script execution time limit: Add or modify the following lines in the configuration file to set the maximum execution time of the Lua script (unit: milliseconds)
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to implement redis counter
Apr 10, 2025 pm 10:21 PM
How to implement redis counter
Apr 10, 2025 pm 10:21 PM
Redis counter is a mechanism that uses Redis key-value pair storage to implement counting operations, including the following steps: creating counter keys, increasing counts, decreasing counts, resetting counts, and obtaining counts. The advantages of Redis counters include fast speed, high concurrency, durability and simplicity and ease of use. It can be used in scenarios such as user access counting, real-time metric tracking, game scores and rankings, and order processing counting.
 How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
There are two types of Redis data expiration strategies: periodic deletion: periodic scan to delete the expired key, which can be set through expired-time-cap-remove-count and expired-time-cap-remove-delay parameters. Lazy Deletion: Check for deletion expired keys only when keys are read or written. They can be set through lazyfree-lazy-eviction, lazyfree-lazy-expire, lazyfree-lazy-user-del parameters.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
