

Example analysis of master-slave replication, sentry, and clustering in Redis

1. Redis master-slave replication
1. Overview of master-slave replication
Master-slave replication copies data from one Redis server to other Redis servers process. The former is called the master node (Master), and the latter is called the slave node (Slave); data replication is one-way, and can only be from the master node to the slave node.
By default, each Redis server is a master node; and a master node can have multiple slave nodes, but a slave node can only have one master node. [Related recommendation: Redis video tutorial]
2. The role of master-slave replication
● Data redundancy: Master-slave replication realizes data Hot backup is a data redundancy method other than persistence.
● Failure recovery: When a problem occurs on the master node, the slave node can provide services to achieve rapid failure recovery; it is actually a kind of service redundancy.
● Load balancing: Based on master-slave replication, combined with read-write separation, the master node can provide write services and the slave nodes can provide read services (that is, when writing Redis data, the application connects to the master node , when reading Redis data, apply the connection slave node) to share the server load; especially in the scenario of less writing and more reading, sharing the read load through multiple slave nodes can greatly increase the concurrency of the Redis server.
● Cornerstone of High Availability: In addition to the above functions, master-slave replication is also the basis for the implementation of sentinels and clusters. Therefore, master-slave replication is the basis of Redis high availability.
3. Master-slave replication process
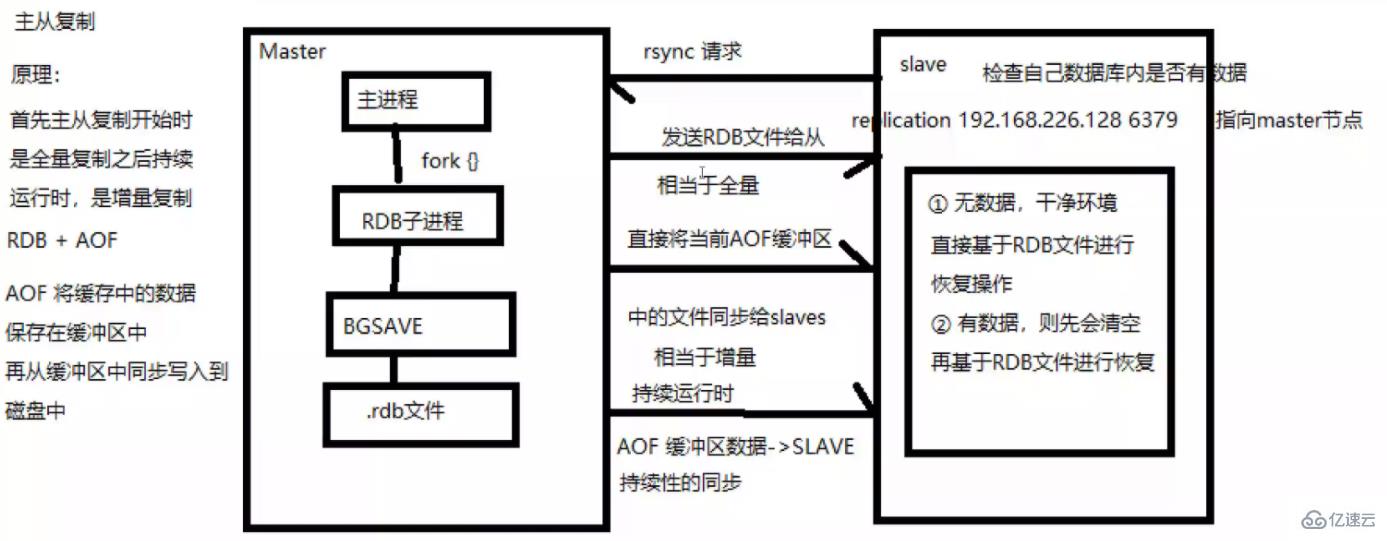
(1) If a Slave machine process is started, it will send data to the Master machine Send a "sync command" command to request a synchronous connection.
(2) Whether it is the first connection or reconnection, the Master machine will start a background process to save the data snapshot to the data file (perform RDB operation). At the same time, the Master will also record and cache all commands to modify the data. in the data file.
(3) After the background process completes the caching operation, the Master machine will send the data file to the Slave machine. The Slave machine will save the data file to the hard disk and then load it into the memory. Then the Master machine will modify the data file. All operations on the data are sent to the Slave machine at the same time. If the Slave fails and causes downtime, it will automatically reconnect when it returns to normal.
(4) After the Master machine receives the connection from the Slave machine, it sends its complete data file to the Slave machine. If the Master receives multiple synchronization requests from the Slave at the same time, the Master will start a synchronization request in the background. process to save the data file and then send it to all slave machines to ensure that all slave machines are normal.
4. Set up Redis master-slave replication
4.1 Server IP configuration
| Server | Host Name | IP | ||
|---|---|---|---|---|
| Master Node | master | 192.168 .122.10 | ||
| Slave1 node | slave1 | 192.168.122.11 | ||
| Slave2 node | slave2 | 192.168.122.12 |

| Server | Host Name | IP | ||
|---|---|---|---|---|
| master | 192.168.122.10 | |||
| slave1 | 192.168.122.11 | |||
| slave2 | 192.168.122.12 |
| 服务器 | 主机名 | IP | 主端口 | 从端口 |
|---|---|---|---|---|
| Node1节点 | node | 192.168.122.10 | 6001 | 6004 |
| Node2节点 | node | 192.168.122.10 | 6002 | 6005 |
| Node3节点 | node | 192.168.122.10 | 6003 | 6006 |
7.2 服务器防火墙环境
systemctl stop firewalld && systemctl disable firewalld setenforce 0
7.3 创建集群配置目录及文件
[root@node ~]# cd /etc/redis
[root@node redis]# mkdir -p redis-cluster/redis600{1..6}
[root@node redis]# for i in {1..6}
> do
> cp /opt/redis-5.0.7/redis.conf /etc/redis/redis-cluster/redis600$i
> cp /opt/redis-5.0.7/src/redis-cli /opt/redis-5.0.7/src/redis-server /etc/redis/redis-cluster/redis600$i
> done
[root@node redis]# ls -R redis-cluster/
redis-cluster/:
redis6001 redis6002 redis6003 redis6004 redis6005 redis6006
redis-cluster/redis6001:
redis-cli redis.conf redis-server
redis-cluster/redis6002:
redis-cli redis.conf redis-server
redis-cluster/redis6003:
redis-cli redis.conf redis-server
redis-cluster/redis6004:
redis-cli redis.conf redis-server
redis-cluster/redis6005:
redis-cli redis.conf redis-server
redis-cluster/redis6006:
redis-cli redis.conf redis-server7.4 开启群集功能
仅以redis6001为例,其他5个文件夹的配置文件以此类推修改,特别注意端口号的修改。
[root@node redis]# cd redis-cluster/redis6001 [root@node redis6001]# vim redis.conf ##69行,注释掉bind项,默认监听所有网卡 #bind 127.0.0.1 ##88行,修改,关闭保护模式 protected-mode no ##92行,修改,redis监听端口 port 6001 ##136行,开启守护进程,以独立进程启动 daemonize yes ##832行,取消注释,开启群集功能 cluster-enabled yes ##840行,注销注释,群集名称文件设置 cluster-config-file nodes-6001.conf ##846行,注销注释,群集超时时间设置 cluster-node-timeout 15000 ##700行,修改,开启AOF持久化 appendonly yes
7.5 启动redis节点
分别进入那六个文件夹,执行命令:“redis-server redis.conf”,来启动redis节点
[root@node redis6001]# for d in {1..6}
> do
> cd /etc/redis/redis-cluster/redis600$i
> ^C
[root@node redis6001]# for d in {1..6}
> do
> cd /etc/redis/redis-cluster/redis600$d
> redis-server redis.conf
> done
[root@node1 redis6006]# ps -ef | grep redis
root 992 1 0 13:45 ? 00:00:07 /usr/local/redis/bin/redis-server 0.0.0.0:6379
root 2289 1 0 14:41 ? 00:00:00 redis-server *:6001 [cluster]
root 2294 1 0 14:41 ? 00:00:00 redis-server *:6002 [cluster]
root 2299 1 0 14:41 ? 00:00:00 redis-server *:6003 [cluster]
root 2304 1 0 14:41 ? 00:00:00 redis-server *:6004 [cluster]
root 2309 1 0 14:41 ? 00:00:00 redis-server *:6005 [cluster]
root 2314 1 0 14:41 ? 00:00:00 redis-server *:6006 [cluster]
root 2450 2337 0 14:50 pts/0 00:00:00 grep --color=auto redis7.6 启动集群
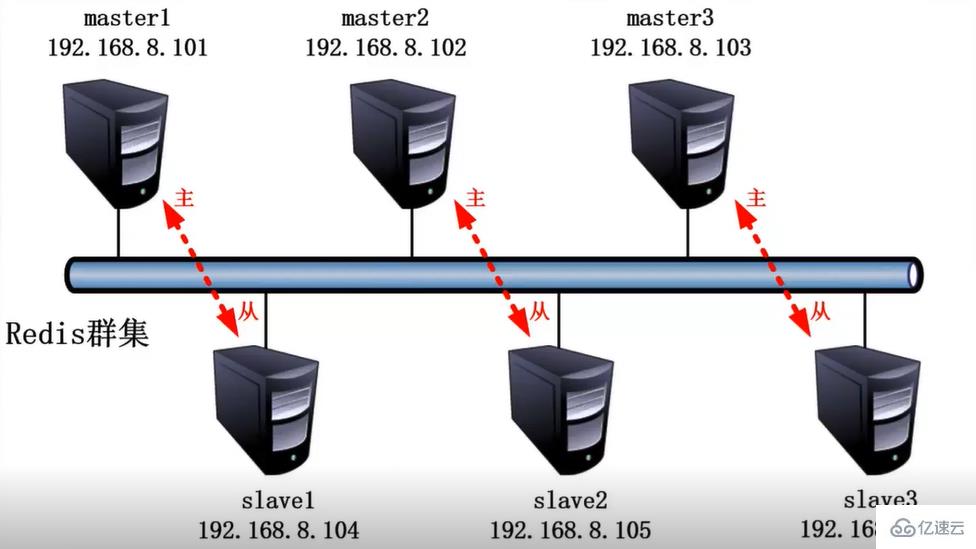
[root@node redis6006]# redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1
六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。下面交互的时候需要输入yes才可以成功创建。
–replicas 1表示每个主节点有1个从节点。
7.7 测试集群
[root@node1 redis6006]# redis-cli -p 6001 -c
#加-c参数,节点之前就可以互相跳转
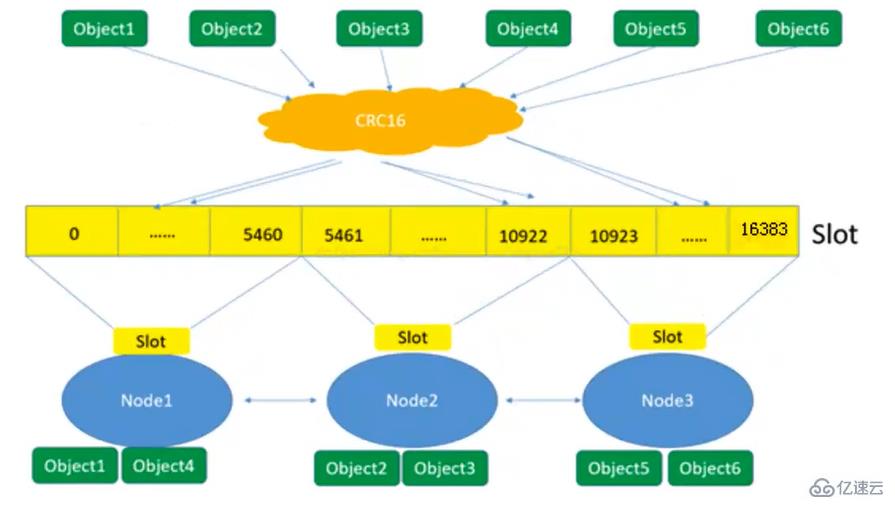
127.0.0.1:6001> cluster slots
#查看节点的哈希槽编号范围
1) 1) (integer) 0
#哈希槽起始编号
2) (integer) 5460
#哈希槽终止编号
3) 1) "127.0.0.1"
2) (integer) 6001
#node节点主
3) "18e59f493579facea29abf90ca4050f566d66339"
4) 1) "127.0.0.1"
2) (integer) 6004
#node节点从
3) "2635bf6a0c286ef910ec5da03dbdc7cde308c588"
2) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 6003
3) "51460d417eb56537e5bd7e8c9581c66fdd817b3c"
4) 1) "127.0.0.1"
2) (integer) 6006
3) "51a75667dcf21b530e69a3242a3e9f81f577168d"
3) 1) (integer) 5461
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 6002
3) "6381d68c06ddb7ac43c8f7d7b8da0644845dcd59"
4) 1) "127.0.0.1"
2) (integer) 6005
3) "375ad927116d3aa845e95ad5f0586306e7ff3a96"
127.0.0.1:6001> set num 1
OK
127.0.0.1:6001> get num
"1"
127.0.0.1:6001> keys *
1) "num"
127.0.0.1:6001> quit
[root@node1 redis6006]# redis-cli -p 6002 -c
127.0.0.1:6002> keys *
#6002端口无键值对
(empty list or set)
127.0.0.1:6002> get num
-> Redirected to slot [2765] located at 127.0.0.1:6001
"1"
#6002端口获取到num键位于6001端口,切换到6001端口并显示键值
127.0.0.1:6001> set key1 11111
-> Redirected to slot [9189] located at 127.0.0.1:6002
OK
#6001端口创建键值对,将其存至6002端口,并切换至6002端口
127.0.0.1:6002>The above is the detailed content of Example analysis of master-slave replication, sentry, and clustering in Redis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
On CentOS systems, you can limit the execution time of Lua scripts by modifying Redis configuration files or using Redis commands to prevent malicious scripts from consuming too much resources. Method 1: Modify the Redis configuration file and locate the Redis configuration file: The Redis configuration file is usually located in /etc/redis/redis.conf. Edit configuration file: Open the configuration file using a text editor (such as vi or nano): sudovi/etc/redis/redis.conf Set the Lua script execution time limit: Add or modify the following lines in the configuration file to set the maximum execution time of the Lua script (unit: milliseconds)
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
There are two types of Redis data expiration strategies: periodic deletion: periodic scan to delete the expired key, which can be set through expired-time-cap-remove-count and expired-time-cap-remove-delay parameters. Lazy Deletion: Check for deletion expired keys only when keys are read or written. They can be set through lazyfree-lazy-eviction, lazyfree-lazy-expire, lazyfree-lazy-user-del parameters.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How to implement redis counter
Apr 10, 2025 pm 10:21 PM
How to implement redis counter
Apr 10, 2025 pm 10:21 PM
Redis counter is a mechanism that uses Redis key-value pair storage to implement counting operations, including the following steps: creating counter keys, increasing counts, decreasing counts, resetting counts, and obtaining counts. The advantages of Redis counters include fast speed, high concurrency, durability and simplicity and ease of use. It can be used in scenarios such as user access counting, real-time metric tracking, game scores and rankings, and order processing counting.
