
 Technology peripherals
AI
Google does not open source PaLM, but netizens open source it! Miniature version of hundreds of billions of parameters: the maximum is only 1 billion, 8k context
Technology peripherals
AI
Google does not open source PaLM, but netizens open source it! Miniature version of hundreds of billions of parameters: the maximum is only 1 billion, 8k context
Google does not open source PaLM, but netizens open source it! Miniature version of hundreds of billions of parameters: the maximum is only 1 billion, 8k context

PaLM, which Google has not open sourced, has been open sourced by netizens.
Yesterday, a developer open sourced three miniature versions of the PaLM model on GitHub: parameters are 150 million (PalM-150m), 410 million (PalM-410m) and 1 billion (PalM-1b).
## Project address: https://github.com/conceptofmind/PaLM
These three models were trained on the Google C4 data set with a context length of 8k. In the future, models with 2 billion parameters are being trained.
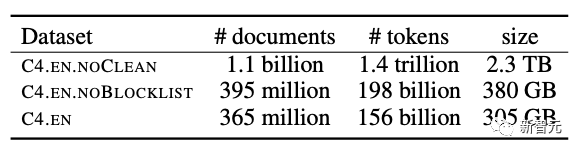
Google C4 Dataset
Open Source PaLMExample generated using 410 million parameter model:
My dog is very cute, but not very good at socializing with other dogs. The dog loves all new people and he likes to hang out with other dogs . I do need to take him to the park with other dogs. He does have some bad puppy breath, but it is only when he runs off in a direction he doesn't want to go. currently my dog is being very naughty. He would like to say hi in the park, but would rather take great care of himself for a while. He also has bad breath. I am going to have to get him some oral braces. It's been 3 months. The dog has some biting pains around his mouth. The dog is very timid and scared. The dog gets aggressive towards people. The dog is very playful and they are a little spoiled. I am not sure if it's a dog thing or if he is spoiled. He loves his toys and just wants to play. He plays with his toys all the time and even goes on walks. He is a little picky, not very good with other dogs. The dog is just a little puppy that goes to the park. He is a super friendly dog. He has not had a bad mouth or bad breathMy dog is very cute, but he is not good at socializing with other dogs. This dog loves all new people and he loves playing with other dogs. I do need to take him to the park with the other dogs. He does have a bit of puppy dog breath, but only when he runs in a direction he doesn't want to go. Now my dog is very naughty. He wanted to say hello in the park, but would rather take care of himself for a while. He also has bad breath. It's been three months since I had to buy him an oral brace. The dog has some sore bite marks around his mouth. This dog is very timid and scared. This dog is very playful and they are a bit spoiled. I'm not sure if it's the dog's fault or if he's just spoiled. He loves his toys and just wants to play with them. He is always playing with his toys and even going for walks. He is a bit picky and doesn't get along well with other dogs. The dog was just a puppy going to the park. He is a super friendly dog. He no longer has a bad breath problem.Although the parameters are indeed a bit small, the generated effect is still a bit hard to describe...
These models are compatible with many popular Lucidrain repositories, such as Toolformer-pytorch , PalM-rlhf-pytorch and PalM-pytorch.
The three latest open source models are baseline models and will be trained on larger-scale data sets.
All models will be further adjusted with instructions on FLAN to provide flan-PaLM models.
In terms of optimization algorithm, the decoupled weight attenuation Adam W is used, but you can also choose to use Mitchell Wortsman's Stable Adam W.
Currently, the model has been uploaded to Torch hub and the files are also stored in Huggingface hub.
If the model cannot be downloaded correctly from Torch hub, be sure to clear the checkpoints and model folders in .cache/torch/hub/. If the issue is still not resolved, then you can download the file from Huggingface’s repository. Currently, the integration of Huggingface is in progress.
All training data has been pre-labeled with GPTNEOX tagger, and the sequence length is cut off to 8192. This will help save significant costs in preprocessing data.
These datasets have been stored on Huggingface in parquet format, you can find the individual data chunks here: C4 Chunk 1, C4 Chunk 2, C4 Chunk 3, C4 Chunk 4, and C4 Chunk 5.
There is another option in the distributed training script to not use the provided pre-labeled C4 dataset, but to load and process another dataset like openwebtext.
Installation
There is a wave of installation required before attempting to run the model.
<code>git clone https://github.com/conceptofmind/PaLM.gitcd PaLM/pip3 install -r requirements.txt</code>
Using
You can do additional training or fine-tuning by loading a pre-trained model using Torch hub:
<code>model = torch.hub.load("conceptofmind/PaLM", "palm_410m_8k_v0").cuda()</code>In addition, you can also directly load the PyTorch model checkpoint through the following method:
<code>from palm_rlhf_pytorch import PaLMmodel = PaLM(num_tokens=50304, dim=1024, depth=24, dim_head=128, heads=8, flash_attn=True, qk_rmsnorm = False,).cuda()model.load('/palm_410m_8k_v0.pt')</code>To use the model to generate text, you can use the command line:
prompt - Prompt for generating text.
seq _ len - the sequence length of the generated text, the default value is 256.
temperature - Sampling temperature, default is 0.8
filter_thres - Filter threshold used for sampling. The default value is 0.9.
model - The model to use for generation. There are three different parameters (150m, 410m, 1b): palm_150m_8k_v0, palm_410m_8k_v0, palm_1b_8k_v0.
<code>python3 inference.py "My dog is very cute" --seq_len 256 --temperature 0.8 --filter_thres 0.9 --model "palm_410m_8k_v0"</code>
In order to improve performance, reasoning uses torch.compile(), Flash Attention and Hidet.
If you want to extend the generation by adding stream processing or other functions, the author provides a general inference script "inference.py".
Training
These "Open Source Palm" models were trained on 64 A100 (80GB) GPUs.
In order to facilitate model training, the author also provides a distributed training script train_distributed.py.
You are free to change the model layer and hyperparameter configuration to meet the hardware requirements, and you can also load the model's weights and change the training script to fine-tune the model.
Finally, the author stated that he would add a specific fine-tuning script and explore LoRA in the future.

Data
can be generated by running the build_dataset.py script similar to C4 used during training Dataset way to preprocess different datasets. This will pre-label the data, split it into chunks of specified sequence length, and upload it to the Huggingface hub.
For example:
<code>python3 build_dataset.py --seed 42 --seq_len 8192 --hf_account "your_hf_account" --tokenizer "EleutherAI/gpt-neox-20b" --dataset_name "EleutherAI/the_pile_deduplicated"</code>
PaLM 2 is coming
In April 2022, Google officially announced 540 billion for the first time Parameters of PaLM. Like other LLMs, PaLM can perform a variety of text generation and editing tasks.
PaLM is Google’s first large-scale use of the Pathways system to scale training to 6144 chips, which is the largest TPU-based system configuration used for training to date.
Its understanding ability is outstanding. Not only can it understand the jokes, but it can also explain the funny points to you who don’t understand.

Just in mid-March, Google opened its PaLM large language model API for the first time.

This means that people can use it to complete tasks such as summarizing text, writing code, and even training PaLM into a ChatGPT-like Conversational chatbot.
At the upcoming Google annual I/O conference, Pichai will announce the company’s latest developments in the field of AI.
It is said that the latest and most advanced large-scale language model PaLM 2 will be launched soon.
PaLM 2 includes more than 100 languages and has been running under the internal code name "Unified Language Model" (Unified Language Model). It also conducts extensive testing in coding and mathematics as well as creative writing.
Last month, Google said that its medical LLM "Med-PalM2" can answer medical exam questions with an accuracy of 85% at the "expert doctor level."
In addition, Google will also release Bard, a chat robot supported by large models, as well as a generative experience for search.
It remains to be seen whether the latest AI release can straighten Google’s back.
The above is the detailed content of Google does not open source PaLM, but netizens open source it! Miniature version of hundreds of billions of parameters: the maximum is only 1 billion, 8k context. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1673
1673
 14
1428
52
1333
25
1278
29
1257
24
14
1428
52
1333
25
1278
29
1257
24

 Tutorial on how to register, use and cancel Ouyi okex account
Mar 31, 2025 pm 04:21 PM
Tutorial on how to register, use and cancel Ouyi okex account
Mar 31, 2025 pm 04:21 PM
This article introduces in detail the registration, use and cancellation procedures of Ouyi OKEx account. To register, you need to download the APP, enter your mobile phone number or email address to register, and complete real-name authentication. The usage covers the operation steps such as login, recharge and withdrawal, transaction and security settings. To cancel an account, you need to contact Ouyi OKEx customer service, provide necessary information and wait for processing, and finally obtain the account cancellation confirmation. Through this article, users can easily master the complete life cycle management of Ouyi OKEx account and conduct digital asset transactions safely and conveniently.
 Tutorial on using gate.io mobile app
Mar 26, 2025 pm 05:15 PM
Tutorial on using gate.io mobile app
Mar 26, 2025 pm 05:15 PM
Tutorial on using gate.io mobile app: 1. For Android users, visit the official Gate.io website and download the Android installation package, you may need to allow the installation of applications from unknown sources in your mobile phone settings; 2. For iOS users, search "Gate.io" in the App Store to download.
 How to optimize jieba word segmentation to improve the keyword extraction effect of scenic spot comments?
Apr 01, 2025 pm 06:24 PM
How to optimize jieba word segmentation to improve the keyword extraction effect of scenic spot comments?
Apr 01, 2025 pm 06:24 PM
How to optimize jieba word segmentation to improve keyword extraction of scenic spot comments? When using jieba word segmentation to process scenic spot comment data, if the word segmentation results are ignored...
 The latest updates to the oldest virtual currency rankings
Apr 22, 2025 am 07:18 AM
The latest updates to the oldest virtual currency rankings
Apr 22, 2025 am 07:18 AM
The ranking of virtual currencies’ “oldest” is as follows: 1. Bitcoin (BTC), issued on January 3, 2009, is the first decentralized digital currency. 2. Litecoin (LTC), released on October 7, 2011, is known as the "lightweight version of Bitcoin". 3. Ripple (XRP), issued in 2011, is designed for cross-border payments. 4. Dogecoin (DOGE), issued on December 6, 2013, is a "meme coin" based on the Litecoin code. 5. Ethereum (ETH), released on July 30, 2015, is the first platform to support smart contracts. 6. Tether (USDT), issued in 2014, is the first stablecoin to be anchored to the US dollar 1:1. 7. ADA,
 How to solve the problem of navigator.mediaDevices returning undefined in HTTP page?
Apr 05, 2025 am 07:30 AM
How to solve the problem of navigator.mediaDevices returning undefined in HTTP page?
Apr 05, 2025 am 07:30 AM
After H5 deployment video media acquisition problem Handling When deploying H5 applications, you sometimes encounter problems with page video media acquisition, especially when using navigator.medi...
 Web IDE directory tree indentation: Why are the rendering results of Google Chrome and Firefox browsers different?
Apr 04, 2025 pm 10:15 PM
Web IDE directory tree indentation: Why are the rendering results of Google Chrome and Firefox browsers different?
Apr 04, 2025 pm 10:15 PM
About the rendering differences of WebIDE directory trees under different browsers This article will explore a rename of the Web in Google Chrome and Firefox...
 Do Google and Microsoft Authenticators support HOTP algorithms? How to solve the problem that is not supported?
Apr 02, 2025 pm 03:39 PM
Do Google and Microsoft Authenticators support HOTP algorithms? How to solve the problem that is not supported?
Apr 02, 2025 pm 03:39 PM
Discussion on whether Google and Microsoft Authenticators support HOTP algorithms When using two-factor authentication, we often use Google and Microsoft...
 How to withdraw cash from Ouyi web version
Mar 27, 2025 pm 05:03 PM
How to withdraw cash from Ouyi web version
Mar 27, 2025 pm 05:03 PM
Ouyi web version withdrawal process: Log in to the account, enter the asset page, and select the withdrawal currency and method (on-chain or fiat currency). On-chain withdrawals must be filled in the correct withdrawal address and matching network, and fiat currency withdrawals must be bound to a bank account. Submit the application after completing the security verification and wait for the review to arrive. Be sure to check the address, network and other information, and pay attention to the handling fee and the minimum withdrawal amount.
