

How to use Redis to lock resources

1. Overview
As this technology continues to be updated and iterated, the concept of distribution is gaining more and more weight in enterprises! When talking about distributed, distributed locks will inevitably be mentioned. At this stage, there are three mainstream implementation methods of distributed locks, Zookeeper, DB, Redis, we use Redis as an example in this article!
From our perspective, these three properties are the minimum guarantees required to effectively use distributed locks.
Safety features: mutually exclusive. At any given moment, only one client can hold the lock.
Vitality attribute: No deadlock. Ultimately, the lock can always be obtained even if the client locking the resource crashes or partitions.
Activity: fault tolerance. As long as a majority of Redis nodes are running, clients can acquire and release locks.
2. Challenges brought by redis multi-node implementation of distributed locks
The simplest way for us to use Redis to lock resources is:
Create a lock in the instance.
Locks usually exist for a limited time using the Redis expiration function, so they will eventually be released, and will eventually be deleted after a given period.
When the client needs to release the resource, it will remove the lock.
At first glance, there seems to be no problem. But let’s take a closer look. This implementation scheme does not seem to have any problems in a redis stand-alone environment! But what if the node goes down? Okay, so let's add a slave node! If the main server is down, use this node! But let’s take a look and see if she’s really guaranteed to be available?
When talking about the fatal flaw of this, we need to understand one knowledge point, Redis replication is asynchronous.
Client A acquires the lock in the main server.
The master crashed before transferring the lock copy to the slave.
slavePromoted to master.Client B acquires the lock because the slave does not have an object for the lock, and the acquisition is successful!
Obviously, this is wrong. The master node went down before it had time to synchronize the data, so the slave node does not have the data, causing the distributed lock to fail. Then the authorantirez’s point of view is how to solve this?
3. Redlock Algorithm
The author believes that we should use multiple Redis. These nodes are completely independent and do not require the use of replication or any system for coordinating data. The process of multiple redis systems acquiring locks becomes the following steps:
Get the current server time in milliseconds
Try to use Use the same key and random value to acquire the lock. There should be a timeout for each machine when acquiring the lock. For example, if the lock expiration time is 10s, then the timeout for acquiring a single node lock should be about 5 to 50 milliseconds. He is like this The purpose is to ensure that the client is connected to the failed machine, which wastes extra time! If the data is not obtained within the timeout period, the node will be abandoned and the next node will be obtained until all nodes are obtained!
After the acquisition is completed, obtain the current time minus the time obtained in step 1. If and only if more than half of the clients obtain successfully and the time to obtain the lock is less than the lock amount timeout, it is proved that The lock takes effect!
After acquiring the lock, the lock timeout is equal to
The set valid time - the time it takes to acquire the lock#If more than half of the machines that acquire the lock are not satisfied, or the lock timeout is negative after calculation, etc. operation, the system will try to unlock all instances. Even if some instances fail to acquire the lock successfully, they will still be tried to unlock!
Release the lock, simply release the lock in all instances, regardless of whether the client thinks it can successfully lock the given instance.
4. But can Redlock really solve the problem?
Martin Kleppmann published an article task, Redlock cannot guarantee the security of the lock!
He believes that there are only two uses of locks
#Improve efficiency and use locks to ensure that a task does not need to be executed twice. For example (very expensive calculation)
To ensure accuracy, a lock mechanism is used to ensure that tasks are performed in the normal process order to avoid two nodes operating on the same data at the same time, resulting in File conflicts and data loss.
For the first reason, we have a certain tolerance for locks. Even if two nodes work at the same time, the impact on the system will only be extra effort. Some computational cost, no additional impact. At this time, using a single point of Redis can solve the problem very well. There is no need to use RedLock to maintain so many Redis instances and increase the maintenance cost of the system.
1. Disadvantages caused by the timeout of distributed locks
But for the second scenario, you should be more cautious, because it is likely to involve some monetary transactions. If the lock fails, And if two nodes process the same data at the same time, the result will be file corruption, data loss, permanent inconsistency, or monetary loss!
Let's assume a scenario where we have two clients. Each client must get the lock before it can save data to the database. What problems will occur if we use the RedLock algorithm to implement it? In RedLock, in order to prevent deadlock, the lock has an expiration time, but Martin thinks this is unsafe! The flowchart looks like this!
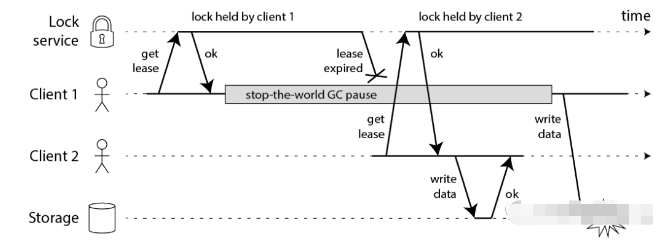
After client 1 successfully obtained the lock, it started execution. Halfway through the execution, a Full GC occurred in the system, the system service was suspended, and the lock timed out after a while.
After client 2 waited for client 1's lock to time out, it successfully obtained the lock and began to perform the warehousing operation. After completion, client 1 completed the Full GC and performed another warehousing operation! This is unsafe! How to solve it?
Martin proposed an implementation mechanism similar to optimistic locking. The example diagram is as follows:
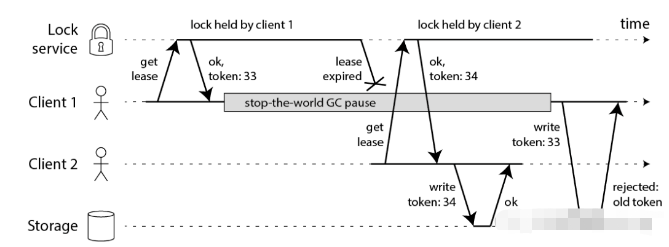
After client 1 was suspended for a long time, client 2 obtained the lock and started writing the library, carrying the token 34. After writing the library, client 1 woke up. The warehousing operation started, but because the token carried was 33 which was smaller than the latest token, the submission was rejected!
Even if there is a problem with the system that causes a hang, this idea seems complete to ensure that the data is still processed correctly. But think about it:
A datastore is a linearizable store if it can always accept writes only if your token is larger than all past tokens , which is equivalent to using a database to implement a distributed lock system, then the role of RedLock becomes minimal! You don’t even need to use redis to guarantee distributed locks!
2.RedLock is strongly dependent on the system clock
Recall the steps of Redlock algorithm to obtain the lock, you will find the effectiveness of the lock It is strongly dependent on the current system clock. We assume:
We have, A B C D E five redis nodes:
Client 1 gets the nodes A, B, C locking. D and E cannot be accessed due to network problems.
The clock on node C jumps forward, causing the lock to expire.
Client 2 acquires the lock of nodes C, D, and E. A and B cannot be accessed due to network problems.
Now, both clients 1 and 2 think they hold the lock.
A similar problem may occur if C crashes and restarts immediately before persisting the lock to disk.
Martin believes that the system time step mainly comes from two aspects (and the solution given by the author):
Human modification.
What can you say about human modification? There is no way to prevent people from causing destruction.
A jump-time clock update was received from the NTP service.
Operation and maintenance personnel need to deal with the problem of NTP accepting step clock updates. When you need to update the step time to the server, you should take small steps and run quickly. Modify multiple times, and the time for each update should be as small as possible.
3. Based on programming language to make up for the shortcomings caused by the timeout of distributed locks
We review 1 point of view and delve into the root cause of this defect in abstraction The reason is to solve a series of problems caused by lock failure caused by system downtime and imposing an expiration time on the lock. Under abnormal circumstances, the execution time of the program (business) is greater than the lock expiration time. Can we start from this? Should we consider this aspect and use programs to solve such a dead situation?
We can ensure that the execution time of the business program is absolutely less than the lock timeout, so as to avoid the problem that the lock expiration time is less than the business time.
In the java language, redisson implements a A mechanism that ensures that the lock expiration time is absolutely greater than the execution time of the business program. Officially called the watchdog mechanism (Watchdog), its main principle is that after the program successfully acquires the lock, it will fork a child thread to continuously renew the lock until the lock is released! His schematic diagram roughly looks like this:
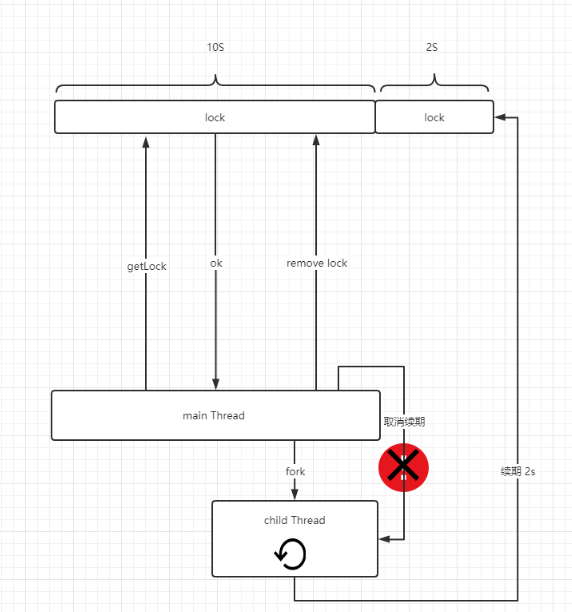
redisson uses daemon threads to renew locks. (The role of daemon threads: when main thread is destroyed, it will be destroyed together with main thread.) Prevent the program After the downtime, the thread continues to live, causing a deadlock!
In addition, Redisson also implements and optimizes RedLock algorithm, fair lock, reentrant lock, chain and other operations, making the implementation of Redis distributed lock easier and more efficient!
The above is the detailed content of How to use Redis to lock resources. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1659
1659
 14
1415
52
1310
25
1258
29
1232
24
14
1415
52
1310
25
1258
29
1232
24

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
On CentOS systems, you can limit the execution time of Lua scripts by modifying Redis configuration files or using Redis commands to prevent malicious scripts from consuming too much resources. Method 1: Modify the Redis configuration file and locate the Redis configuration file: The Redis configuration file is usually located in /etc/redis/redis.conf. Edit configuration file: Open the configuration file using a text editor (such as vi or nano): sudovi/etc/redis/redis.conf Set the Lua script execution time limit: Add or modify the following lines in the configuration file to set the maximum execution time of the Lua script (unit: milliseconds)
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to implement redis counter
Apr 10, 2025 pm 10:21 PM
How to implement redis counter
Apr 10, 2025 pm 10:21 PM
Redis counter is a mechanism that uses Redis key-value pair storage to implement counting operations, including the following steps: creating counter keys, increasing counts, decreasing counts, resetting counts, and obtaining counts. The advantages of Redis counters include fast speed, high concurrency, durability and simplicity and ease of use. It can be used in scenarios such as user access counting, real-time metric tracking, game scores and rankings, and order processing counting.
 How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
There are two types of Redis data expiration strategies: periodic deletion: periodic scan to delete the expired key, which can be set through expired-time-cap-remove-count and expired-time-cap-remove-delay parameters. Lazy Deletion: Check for deletion expired keys only when keys are read or written. They can be set through lazyfree-lazy-eviction, lazyfree-lazy-expire, lazyfree-lazy-user-del parameters.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
