
 Technology peripherals
AI
Imitating Jeff Dean's divine summary, a former Google engineer shared 'LLM development secrets': numbers that every developer should know!
Technology peripherals
AI
Imitating Jeff Dean's divine summary, a former Google engineer shared 'LLM development secrets': numbers that every developer should know!
Imitating Jeff Dean's divine summary, a former Google engineer shared 'LLM development secrets': numbers that every developer should know!

Recently, a netizen compiled a list of "Numbers that every LLM developer should know" and explained why these numbers are important and how we should use them.
When he was at Google, there was a document compiled by legendary engineer Jeff Dean called "Numbers Every Engineer Should Know."

Jeff Dean: "Numbers Every Engineer Should Know"
For LLM (Large Language Model) developers, it is also very useful to have a similar set of numbers for rough estimation.

Prompt
##40-90%: Add "concise" to the prompt The subsequent cost savings
#You must know that you pay according to the token used by LLM during output.
This means that you can save a lot of money by letting your model be concise.
At the same time, this concept can be expanded to more places.
For example, you originally wanted to use GPT-4 to generate 10 alternatives, but now you may be able to ask it to provide 5 first, and then you can keep the other half of the money.
1.3: The average number of tokens per word
LLM operates in token units.
And a token is a word or a subpart of a word. For example, "eating" may be decomposed into two tokens "eat" and "ing".
Generally speaking, 750 English words will generate about 1000 tokens.
For languages other than English, the number of tokens per word will be increased, depending on their commonality in LLM’s embedding corpus.

Considering that the cost of using LLM is very high, the numbers related to the price are has become particularly important.
~50: Cost ratio of GPT-4 and GPT-3.5 Turbo
Using GPT-3.5-Turbo About 50 times cheaper than GPT-4. I say "approximately" because GPT-4 charges differently for prompts and generation.
So in actual application, it is best to confirm whether GPT-3.5-Turbo is enough to meet your needs.
For example, for tasks like summarizing, GPT-3.5-Turbo is more than sufficient.


##5: Use GPT- 3.5-Turbo vs. OpenAI Embedding Cost Ratio for Text Generation
This means that looking up something in a vector storage system is much cheaper than using generation with LLM. Specifically, searching in the neural information retrieval system costs about 5 times less than asking GPT-3.5-Turbo. Compared with GPT-4, the cost gap is as high as 250 times! 10: Cost Ratio of OpenAI Embeds vs. Self-Hosted Embeds Note: This number is very sensitive to load and embedding batch sizes are very sensitive, so consider them as approximations. With g4dn.4xlarge (on-demand price: $1.20/hour) we can leverage SentenceTransformers with HuggingFace (comparable to OpenAI’s embeddings) at ~9000 per second The speed of token embedding. Doing some basic calculations at this speed and node type shows that self-hosted embeds can be 10x cheaper. 6: Cost ratio of OpenAI basic model and fine-tuned model query On OpenAI, the cost of fine-tuned model 6 times that of the base model. This also means that it is more cost-effective to adjust the base model's prompts than to fine-tune a custom model. 1: Cost ratio of self-hosting base model vs. fine-tuned model query If you host the model yourself, then The cost of the fine-tuned model is almost the same as that of the base model: the number of parameters is the same for both models. ~$1 million: the cost of training a 13 billion parameter model on 1.4 trillion tokens Paper address: https://arxiv.org/pdf/2302.13971.pdf ##LLaMa’s The paper mentioned that it took them 21 days and used 2048 A100 80GB GPUs to train the LLaMa model. Assuming we train our model on the Red Pajama training set, assuming everything works fine, without any crashes, and it succeeds the first time, we will get the above numbers. In addition, this process also involves coordination between 2048 GPUs. Most companies do not have the conditions to do this. However, the most critical message is: it is possible to train our own LLM, but the process is not cheap. And every time it is run, it takes several days. In comparison, using a pre-trained model will be much cheaper. < 0.001: Cost rate for fine-tuning and training from scratch For example, you can fine-tune a 6B parameter model for about $7. Training and fine-tuning
This means that if you want to fine-tune Shakespeare's entire work (about 1 million words), you only need to spend forty or fifty dollars.
However, fine-tuning is one thing, training from scratch is another...
GPU memory
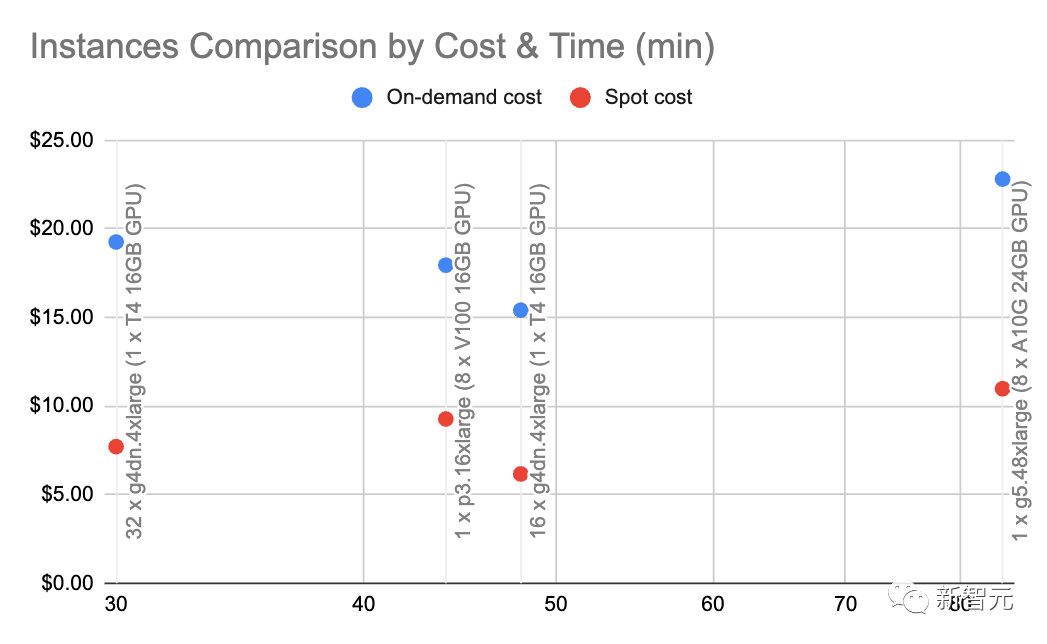
If you are self-hosting the model, it is very important to understand the GPU memory, because LLM is pushing the GPU memory to the limit.The following statistics are used specifically for inference. If you want to do training or fine-tuning, you need quite a bit of video memory. V100: 16GB, A10G: 24GB, A100: 40/80GB: GPU memory capacity Understand the different types The amount of video memory your GPU has is important as this will limit the amount of parameters your LLM can have. Generally speaking, we like to use A10G because they are priced at $1.5 to $2 per hour on AWS on demand and have 24G of GPU memory, while each A100 The price is approximately $5/hour. 2x Parameter amount: Typical GPU memory requirements of LLM For example, when you have a 7 billion Parametric model requires approximately 14GB of GPU memory. This is because in most cases each argument requires a 16-bit floating point number (or 2 bytes). Usually you don't need more than 16 bits of precision, but most of the time the resolution starts to decrease when the precision reaches 8 bits (and in some cases this is acceptable). Of course, there are some projects that have improved this situation. For example, llama.cpp ran through a 13 billion parameter model by quantizing to 4 bits on a 6GB GPU (8 bits are also acceptable), but this is not common. ~1GB: Typical GPU memory requirements for embedding models Whenever you embed statements (clustering, semantics (which is often done for search and classification tasks), you need an embedding model like a sentence converter. OpenAI also has its own commercial embedding model. 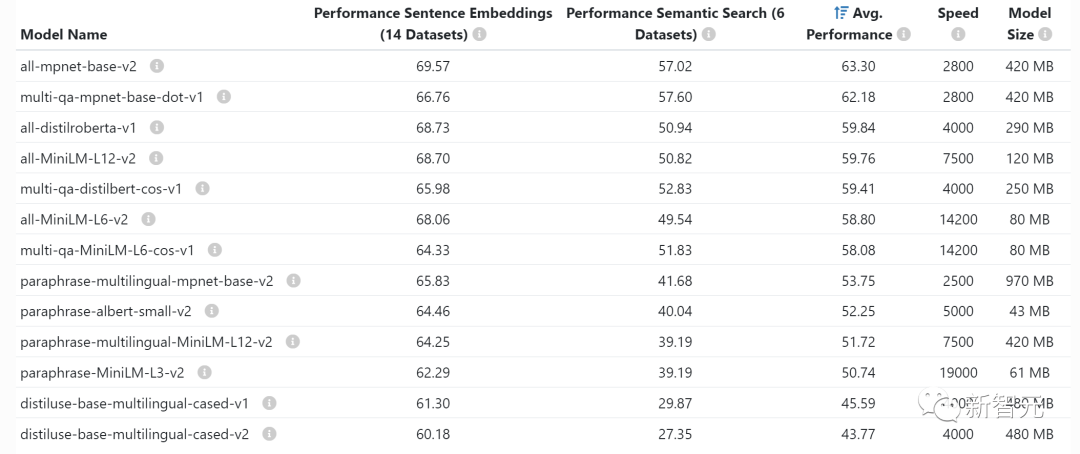
Usually you don’t have to worry about how much video memory embedding takes up on the GPU, they are quite small and you can even embed LLM on the same GPU .
>10x: Improve throughput by batching LLM requests
##Latency of running LLM queries through GPU Very high: At a throughput of 0.2 queries per second, the latency may be 5 seconds.
Interestingly, if you run two tasks, the delay may only be 5.2 seconds.
This means that if you can bundle 25 queries together, you will need about 10 seconds of latency, and the throughput has been increased to 2.5 queries per second.
However, please read on.
~1 MB: GPU memory required for the 13 billion parameter model to output 1 token
What you need The amount of video memory is directly proportional to the maximum number of tokens you want to generate.
For example, generating output of up to 512 tokens (approximately 380 words) requires 512MB of video memory.
You might say, this is no big deal - I have 24GB of video memory, what is 512MB? However, if you want to run larger batches, this number starts to add up.
For example, if you want to do 16 batches, the video memory will be directly increased to 8GB.
The above is the detailed content of Imitating Jeff Dean's divine summary, a former Google engineer shared 'LLM development secrets': numbers that every developer should know!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1666
1666
 14
1425
52
1328
25
1273
29
1253
24
14
1425
52
1328
25
1273
29
1253
24

 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
DMA in C refers to DirectMemoryAccess, a direct memory access technology, allowing hardware devices to directly transmit data to memory without CPU intervention. 1) DMA operation is highly dependent on hardware devices and drivers, and the implementation method varies from system to system. 2) Direct access to memory may bring security risks, and the correctness and security of the code must be ensured. 3) DMA can improve performance, but improper use may lead to degradation of system performance. Through practice and learning, we can master the skills of using DMA and maximize its effectiveness in scenarios such as high-speed data transmission and real-time signal processing.
 How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
Handling high DPI display in C can be achieved through the following steps: 1) Understand DPI and scaling, use the operating system API to obtain DPI information and adjust the graphics output; 2) Handle cross-platform compatibility, use cross-platform graphics libraries such as SDL or Qt; 3) Perform performance optimization, improve performance through cache, hardware acceleration, and dynamic adjustment of the details level; 4) Solve common problems, such as blurred text and interface elements are too small, and solve by correctly applying DPI scaling.
 What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
C performs well in real-time operating system (RTOS) programming, providing efficient execution efficiency and precise time management. 1) C Meet the needs of RTOS through direct operation of hardware resources and efficient memory management. 2) Using object-oriented features, C can design a flexible task scheduling system. 3) C supports efficient interrupt processing, but dynamic memory allocation and exception processing must be avoided to ensure real-time. 4) Template programming and inline functions help in performance optimization. 5) In practical applications, C can be used to implement an efficient logging system.
 Steps to add and delete fields to MySQL tables
Apr 29, 2025 pm 04:15 PM
Steps to add and delete fields to MySQL tables
Apr 29, 2025 pm 04:15 PM
In MySQL, add fields using ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column, delete fields using ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop. When adding fields, you need to specify a location to optimize query performance and data structure; before deleting fields, you need to confirm that the operation is irreversible; modifying table structure using online DDL, backup data, test environment, and low-load time periods is performance optimization and best practice.
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
 Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
The built-in quantization tools on the exchange include: 1. Binance: Provides Binance Futures quantitative module, low handling fees, and supports AI-assisted transactions. 2. OKX (Ouyi): Supports multi-account management and intelligent order routing, and provides institutional-level risk control. The independent quantitative strategy platforms include: 3. 3Commas: drag-and-drop strategy generator, suitable for multi-platform hedging arbitrage. 4. Quadency: Professional-level algorithm strategy library, supporting customized risk thresholds. 5. Pionex: Built-in 16 preset strategy, low transaction fee. Vertical domain tools include: 6. Cryptohopper: cloud-based quantitative platform, supporting 150 technical indicators. 7. Bitsgap:
 How does deepseek official website achieve the effect of penetrating mouse scroll event?
Apr 30, 2025 pm 03:21 PM
How does deepseek official website achieve the effect of penetrating mouse scroll event?
Apr 30, 2025 pm 03:21 PM
How to achieve the effect of mouse scrolling event penetration? When we browse the web, we often encounter some special interaction designs. For example, on deepseek official website, �...
