
 Technology peripherals
AI
Multivariate time series forecasting: independent forecasting or joint forecasting?
Technology peripherals
AI
Multivariate time series forecasting: independent forecasting or joint forecasting?
Multivariate time series forecasting: independent forecasting or joint forecasting?

Today I introduce an article published by NTU in April this year. It mainly discusses the differences between the effects of independent prediction (channel independent) and joint prediction (channel dependent) in multivariate time series forecasting problems, the reasons behind them, and the optimization methods. .

Paper title: The Capacity and Robustness Trade-off: Revisiting the Channel Independent Strategy for Multivariate Time Series Forecasting
Download address : https://arxiv.org/pdf/2304.05206v1.pdf
1. Independent forecasting and joint forecasting
In the multivariate time series forecasting problem, the dimensions of multivariable modeling methods are: There are two types, one is independent prediction (channel independent, CI), which refers to treating multivariate sequences as multiple univariate predictions, and each variable is modeled separately; the other is joint prediction (channel dependent, CD), which refers to It is to model multiple variables together and consider the relationship between each variable. The difference between the two is as shown below.
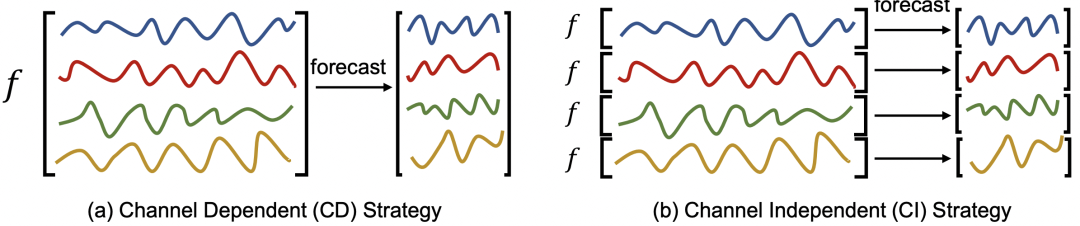
The two methods have their own characteristics: the CI method only considers a single variable, the model is simpler, but the ceiling is also lower because it does not consider the relationship between each sequence. relationship, losing part of the key information; while the CD method considers more comprehensive information, but the model is also more complex.
2. Which method is better
First conduct a detailed comparative experiment and use linear models to observe the effects of the CI method and the CD method on multiple data sets to determine which method A better way. In the experiments in this article, a main conclusion is that the CI method shows better performance on most tasks and has stronger effect stability. As can be seen in the picture below, CI's MAE, MSE and other indicators are basically smaller than CD in each data set, and the fluctuation of the effect is also smaller.
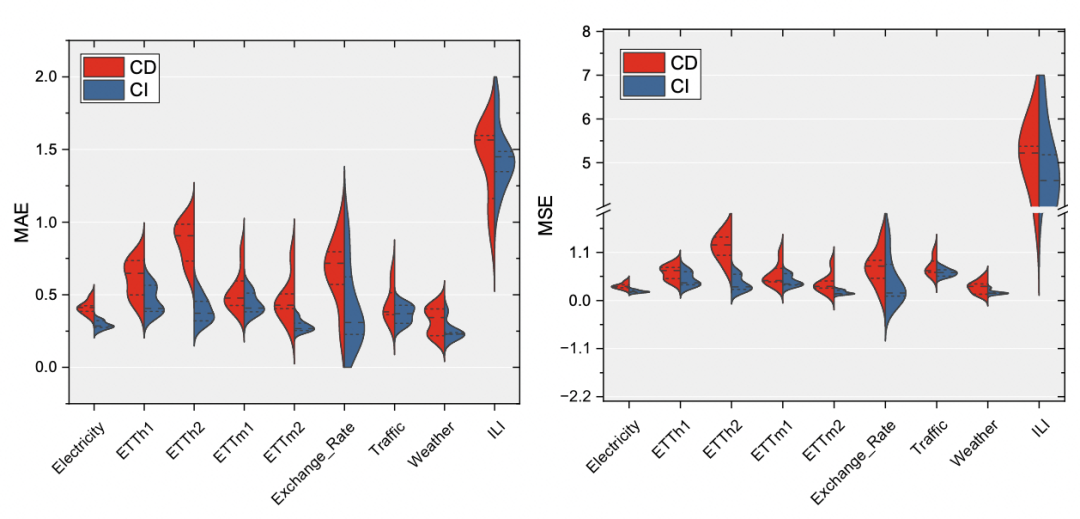
As can be seen from the experimental results below, compared with CD, CI has the same effect on most prediction window lengths and data sets. elevated.
Why is the CI method better and more stable than CD in practical applications? The article conducted some theoretical proofs, and the core conclusion is that real data often has Distribution Drift, and using CI methods can help alleviate this problem and improve model generalization. The picture below shows the distribution of ACF (autocorrelation coefficient, reflecting the relationship between future sequences and historical sequences) of each data set trainset and testset over time. You can see that Distribution Drift is widespread in various data sets. (That is, the ACF of the trainset is different from the ACF of the testset, that is, the relationship between the history and the future sequence of the two is different).
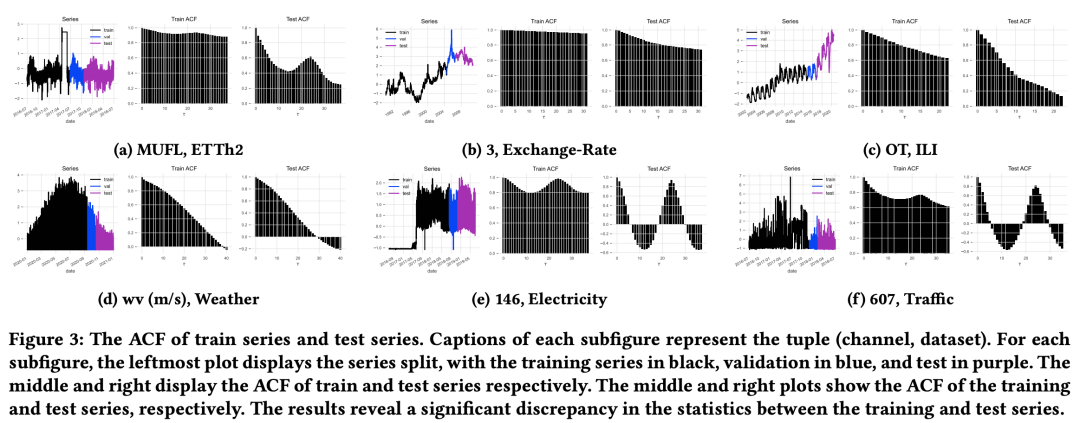
The article proves through theory that CI is effective in mitigating Distribution Drift. The choice between CI and CD is a kind of model capacity and model robustness. A trade-off between stickiness. Although the CD model is more complex, it is also more sensitive to distribution shifts. This is actually similar to the relationship between model capacity and model generalization. The more complex the model, the more accurate the training set samples that the model fits, but the generalization is poor. Once the distribution difference between the training set and the test set is large, the effect will be will get worse.
3. How to optimize
Aiming at the problem of CD modeling, this article proposes some optimization methods that can help the CD model to be more robust.
Regularization: Introduce a regularization loss, use the sequence minus the nearest sample point as the historical sequence input model for prediction, and use smoothing to constrain the prediction result so that the prediction result does not deviate too much from the nearest neighbor observation value. Large, making the estimated results flatter;
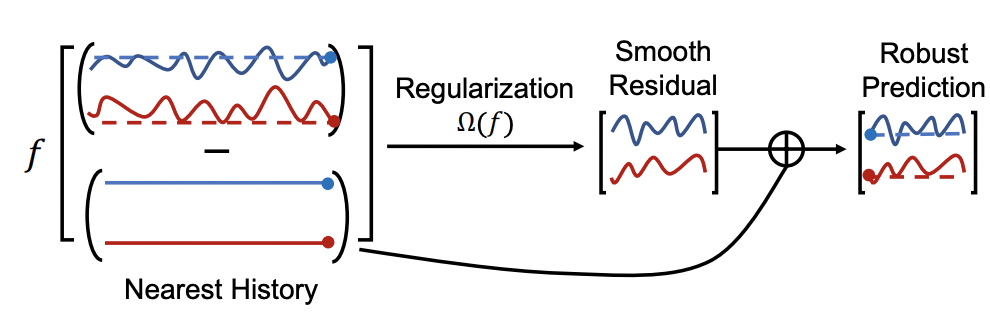
Low-rank decomposition: decompose the fully connected parameter matrix into two low-order matrices, which is equivalent to reducing Increases model capacity, alleviates over-fitting problems, and improves model robustness;
Loss function: MAE is used instead of MSE to reduce the model's sensitivity to outliers;
Historical input sequence length: For the CD model, the longer the input historical sequence, the effect may be reduced. This is also because the longer the historical sequence, the more susceptible the model is to the influence of Distribution Shift. For the CI model, the growth of the historical sequence length can be relatively stable. Improve prediction performance.
4. Experimental results
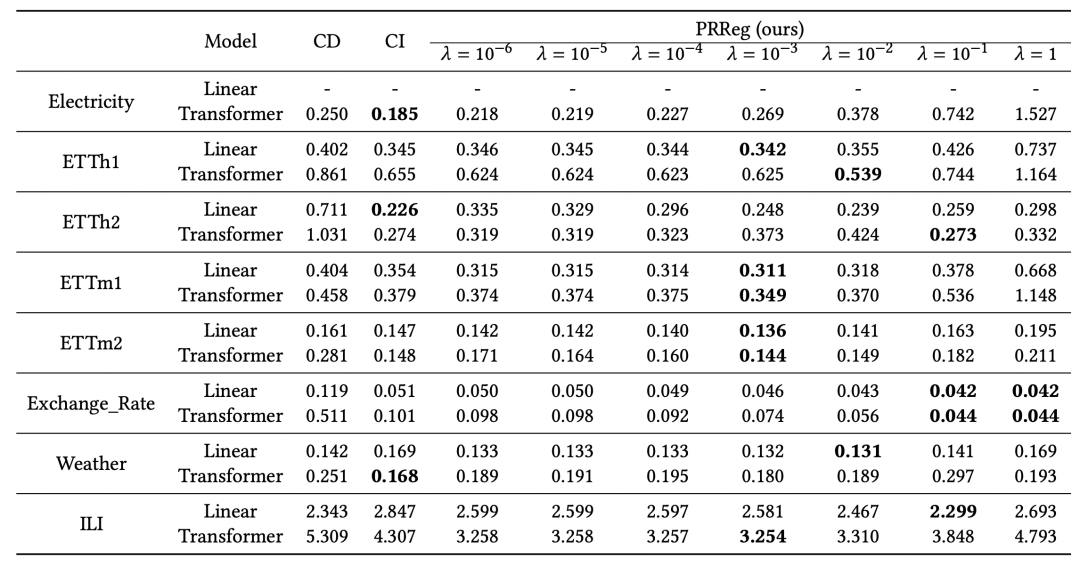
In this article, the above-mentioned method of improving the CD model was tested on multiple data sets. Compared with CD, a relatively stable effect improvement was achieved, indicating that the above method is useful for improving multivariate sequences. Prediction robustness has a relatively obvious effect. Experimental results show that factors such as low-rank decomposition, historical window length and loss function type are also listed in the article in terms of influencing the effect.
The above is the detailed content of Multivariate time series forecasting: independent forecasting or joint forecasting?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: A Leap Forward in Multimodal and Mobile AI Meta recently unveiled Llama 3.2, a significant advancement in AI featuring powerful vision capabilities and lightweight text models optimized for mobile devices. Building on the success o
 10 Generative AI Coding Extensions in VS Code You Must Explore
Apr 13, 2025 am 01:14 AM
10 Generative AI Coding Extensions in VS Code You Must Explore
Apr 13, 2025 am 01:14 AM
Hey there, Coding ninja! What coding-related tasks do you have planned for the day? Before you dive further into this blog, I want you to think about all your coding-related woes—better list those down. Done? – Let’
 AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
This week's AI landscape: A whirlwind of advancements, ethical considerations, and regulatory debates. Major players like OpenAI, Google, Meta, and Microsoft have unleashed a torrent of updates, from groundbreaking new models to crucial shifts in le
 Selling AI Strategy To Employees: Shopify CEO's Manifesto
Apr 10, 2025 am 11:19 AM
Selling AI Strategy To Employees: Shopify CEO's Manifesto
Apr 10, 2025 am 11:19 AM
Shopify CEO Tobi Lütke's recent memo boldly declares AI proficiency a fundamental expectation for every employee, marking a significant cultural shift within the company. This isn't a fleeting trend; it's a new operational paradigm integrated into p
 GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?
Apr 13, 2025 am 10:18 AM
GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?
Apr 13, 2025 am 10:18 AM
Introduction OpenAI has released its new model based on the much-anticipated “strawberry” architecture. This innovative model, known as o1, enhances reasoning capabilities, allowing it to think through problems mor
 A Comprehensive Guide to Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
A Comprehensive Guide to Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Introduction Imagine walking through an art gallery, surrounded by vivid paintings and sculptures. Now, what if you could ask each piece a question and get a meaningful answer? You might ask, “What story are you telling?
 3 Methods to Run Llama 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3 Methods to Run Llama 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
Meta's Llama 3.2: A Multimodal AI Powerhouse Meta's latest multimodal model, Llama 3.2, represents a significant advancement in AI, boasting enhanced language comprehension, improved accuracy, and superior text generation capabilities. Its ability t
 Newest Annual Compilation Of The Best Prompt Engineering Techniques
Apr 10, 2025 am 11:22 AM
Newest Annual Compilation Of The Best Prompt Engineering Techniques
Apr 10, 2025 am 11:22 AM
For those of you who might be new to my column, I broadly explore the latest advances in AI across the board, including topics such as embodied AI, AI reasoning, high-tech breakthroughs in AI, prompt engineering, training of AI, fielding of AI, AI re
