

How to install Hadoop in linux

1: Install JDK
1. Execute the following command to download the JDK1.8 installation package.
wget --no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz
2. Execute the following command to decompress the downloaded JDK1.8 installation package.
tar -zxvf jdk-8u151-linux-x64.tar.gz
3. Move and rename the JDK package.
mv jdk1.8.0_151/ /usr/java8
4. Configure Java environment variables.
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile source /etc/profile
5. Check whether Java is successfully installed.
java -version
2: Install Hadoop
Note: To download the Hadoop installation package, you can choose Huawei source (the speed is medium, acceptable, the focus is on the full version), Tsinghua source (3.0.0 or above The version download speed is too slow and there are few versions), Beijing Foreign Studies University source (the download speed is very fast, but there are few versions) - I personally tested it
1. Execute the following command to download Hadoop installation Bag.
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
2. Execute the following command to decompress the Hadoop installation package to /opt/hadoop.
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/ mv /opt/hadoop-3.1.3 /opt/hadoop
3. Execute the following command to configure Hadoop environment variables.
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile source /etc/profile
4. Execute the following command to modify the configuration files yarn-env.sh and hadoop-env.sh.
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
5. Execute the following command to test whether Hadoop is installed successfully.
hadoop version
If version information is returned, the installation is successful.
3: Configure Hadoop
1. Modify the Hadoop configuration file core-site.xml.
a. Execute the following command to enter the editing page.
vim /opt/hadoop/etc/hadoop/core-site.xml
b. Enter i to enter edit mode. c. Insert the following content into the <configuration></configuration> node.
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>d. Press the Esc key to exit the editing mode, enter: wq to save and exit.
2. Modify the Hadoop configuration file hdfs-site.xml.
a. Execute the following command to enter the editing page.
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
b. Enter i to enter edit mode. c. Insert the following content into the <configuration></configuration> node.
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>d. Press the Esc key to exit the editing mode, enter: wq to save and exit.
Four: Configure SSH password-free login
1. Execute the following command to create the public key and private key.
ssh-keygen -t rsa
2. Execute the following command to add the public key to the authorized_keys file.
cd ~ cd .ssh cat id_rsa.pub >> authorized_keys
If an error is reported, perform the following operations and then re-execute the above two commands; if no error is reported, go directly to step five:
Enter the following command in the environment variable Add the following configuration
vi /etc/profile
Then add the following content to it
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
Enter the following command to make the changes take effect
source /etc/profile
Five: Start Hadoop
1.Execute the following command to initialize the namenode.
hadoop namenode -format
2.Execute the following commands in sequence to start Hadoop.
start-dfs.sh
If Y/N is selected, select Y; otherwise press Enter directly
start-yarn.sh
3.After successful startup, execute the following command , to view the processes that have been successfully started.
jps
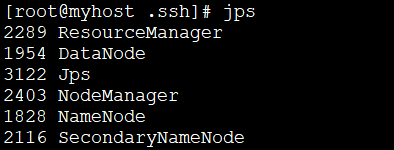
Normally there will be 6 processes;
4.Open the browser to visit http://:8088 and http://:50070. If the following interface is displayed, it means that the Hadoop pseudo-distributed environment is completed.
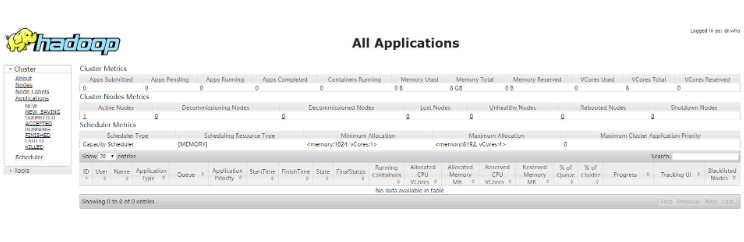
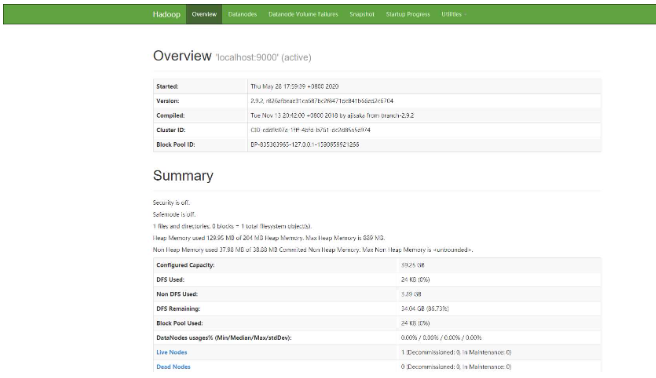
The above is the detailed content of How to install Hadoop in linux. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
What computer configuration is required for vscode
Apr 15, 2025 pm 09:48 PM
VS Code system requirements: Operating system: Windows 10 and above, macOS 10.12 and above, Linux distribution processor: minimum 1.6 GHz, recommended 2.0 GHz and above memory: minimum 512 MB, recommended 4 GB and above storage space: minimum 250 MB, recommended 1 GB and above other requirements: stable network connection, Xorg/Wayland (Linux)
 Linux Architecture: Unveiling the 5 Basic Components
Apr 20, 2025 am 12:04 AM
Linux Architecture: Unveiling the 5 Basic Components
Apr 20, 2025 am 12:04 AM
The five basic components of the Linux system are: 1. Kernel, 2. System library, 3. System utilities, 4. Graphical user interface, 5. Applications. The kernel manages hardware resources, the system library provides precompiled functions, system utilities are used for system management, the GUI provides visual interaction, and applications use these components to implement functions.
 vscode terminal usage tutorial
Apr 15, 2025 pm 10:09 PM
vscode terminal usage tutorial
Apr 15, 2025 pm 10:09 PM
vscode built-in terminal is a development tool that allows running commands and scripts within the editor to simplify the development process. How to use vscode terminal: Open the terminal with the shortcut key (Ctrl/Cmd). Enter a command or run the script. Use hotkeys (such as Ctrl L to clear the terminal). Change the working directory (such as the cd command). Advanced features include debug mode, automatic code snippet completion, and interactive command history.
 How to check the warehouse address of git
Apr 17, 2025 pm 01:54 PM
How to check the warehouse address of git
Apr 17, 2025 pm 01:54 PM
To view the Git repository address, perform the following steps: 1. Open the command line and navigate to the repository directory; 2. Run the "git remote -v" command; 3. View the repository name in the output and its corresponding address.
 How to run java code in notepad
Apr 16, 2025 pm 07:39 PM
How to run java code in notepad
Apr 16, 2025 pm 07:39 PM
Although Notepad cannot run Java code directly, it can be achieved by using other tools: using the command line compiler (javac) to generate a bytecode file (filename.class). Use the Java interpreter (java) to interpret bytecode, execute the code, and output the result.
 Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Writing code in Visual Studio Code (VSCode) is simple and easy to use. Just install VSCode, create a project, select a language, create a file, write code, save and run it. The advantages of VSCode include cross-platform, free and open source, powerful features, rich extensions, and lightweight and fast.
 What is the main purpose of Linux?
Apr 16, 2025 am 12:19 AM
What is the main purpose of Linux?
Apr 16, 2025 am 12:19 AM
The main uses of Linux include: 1. Server operating system, 2. Embedded system, 3. Desktop operating system, 4. Development and testing environment. Linux excels in these areas, providing stability, security and efficient development tools.
 vscode terminal command cannot be used
Apr 15, 2025 pm 10:03 PM
vscode terminal command cannot be used
Apr 15, 2025 pm 10:03 PM
Causes and solutions for the VS Code terminal commands not available: The necessary tools are not installed (Windows: WSL; macOS: Xcode command line tools) Path configuration is wrong (add executable files to PATH environment variables) Permission issues (run VS Code as administrator) Firewall or proxy restrictions (check settings, unrestrictions) Terminal settings are incorrect (enable use of external terminals) VS Code installation is corrupt (reinstall or update) Terminal configuration is incompatible (try different terminal types or commands) Specific environment variables are missing (set necessary environment variables)
