

Python built-in type str source code analysis

1 Unicode
The basic unit of computer storage is the byte, which is composed of 8 bits. Since English only consists of 26 letters plus a number of symbols, English characters can be stored directly in bytes. But other languages (such as Chinese, Japanese, Korean, etc.) have to use multiple bytes for encoding due to the large number of characters.
With the spread of computer technology, non-Latin character encoding technology continues to develop, but there are still two major limitations:
Does not support multiple languages: The encoding scheme of one language cannot be used for another language
There is no unified standard: for example, Chinese has multiple encoding standards such as GBK, GB2312, GB18030
Because the encoding methods are not uniform, developers need to convert back and forth between different encodings, and many errors will inevitably occur. In order to solve this kind of inconsistency problem, the Unicode standard was proposed. Unicode organizes and encodes most of the writing systems in the world, allowing computers to process text in a unified way. Unicode currently contains more than 140,000 characters and naturally supports multiple languages. (Unicode’s uni is the root of “unification”)
2 Unicode in Python
2.1 Benefits of Unicode objects
After Python 3, Unicode is used internally in the str object Represents, and therefore becomes a Unicode object in the source code. The advantage of using Unicode representation is that the core logic of the program uses Unicode uniformly, and only needs to be decoded and encoded at the input and output layers, which can avoid various encoding problems to the greatest extent.
The diagram is as follows:

1 2 3 4 5 6 |
|
- PyUnicode_1BYTE_KIND: All character code points are between U 0000 and U 00FF
- PyUnicode_2BYTE_KIND: All character code points are between U 0000 and U FFFF, and at least one character has a code point greater than U 00FF
- PyUnicode_1BYTE_KIND: All character code points are between U 0000 and U 10FFFF, and at least one character has a code point greater than U FFFF ##The corresponding enumeration is as follows:
1 2 3 4 5 6 7 8 9 10 |
|
According to different Classification, select different storage units:
1 2 3 4 5 |
|
The corresponding relationship is as follows:
Text typePyUnicode_1BYTE_KINDPyUnicode_2BYTE_KIND PyUnicode_4BYTE_KINDSince the Unicode internal storage structure varies depending on the text type, the type kind must be saved as a Unicode object public field. Python internally defines some flag bits as Unicode public fields: (Due to the author's limited level, all the fields here will not be introduced in the subsequent content. You can learn about it yourself later. Hold your fist~)| Character storage unit | Character storage unit size (bytes) | |
|---|---|---|
| Py_UCS1 | 1 | |
| Py_UCS2 | 2 | |
| Py_UCS4 | 4 |
- interned: Whether to maintain the interned mechanism
- kind: type, used to distinguish the size of the underlying storage unit of characters
- compact: memory allocation method, whether the object and the text buffer are separated
- asscii: Whether the text is all pure ASCII
- Through the PyUnicode_New function, according to the number of text characters size and the maximum character maxchar initializes the Unicode object. This function mainly selects the most compact character storage unit and underlying structure for Unicode objects based on maxchar: (The source code is relatively long, so it will not be listed here. You can understand it by yourself. It is shown in table form below)
##kindPyUnicode_1BYTE_KINDPyUnicode_1BYTE_KIND PyUnicode_2BYTE_KINDPyUnicode_4BYTE_KINDascii1000Character storage unit size (bytes) 1124Underlying structurePyASCIIObjectPyCompactUnicodeObjectPyCompactUnicodeObjectPyCompactUnicodeObject
3 Unicode对象的底层结构体
3.1 PyASCIIObject
C源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
源码分析:
length:文本长度
hash:文本哈希值
state:Unicode对象标志位
wstr:缓存C字符串的一个wchar_t指针,以“\0”结束(这里和我看的另一篇文章讲得不太一样,另一个描述是:ASCII文本紧接着位于PyASCIIObject结构体后面,我个人觉得现在的这种说法比较准确,毕竟源码结构体后面没有别的字段了)
图示如下:
(注意这里state字段后面有一个4字节大小的空洞,这是结构体字段内存对齐造成的现象,主要是为了优化内存访问效率)
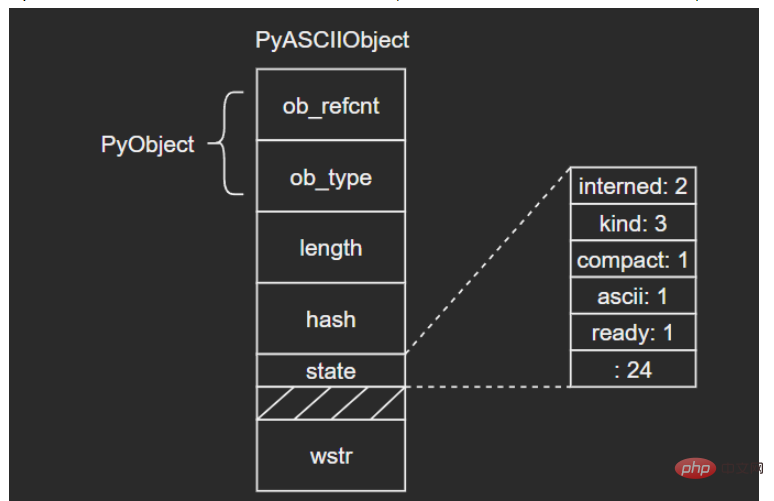
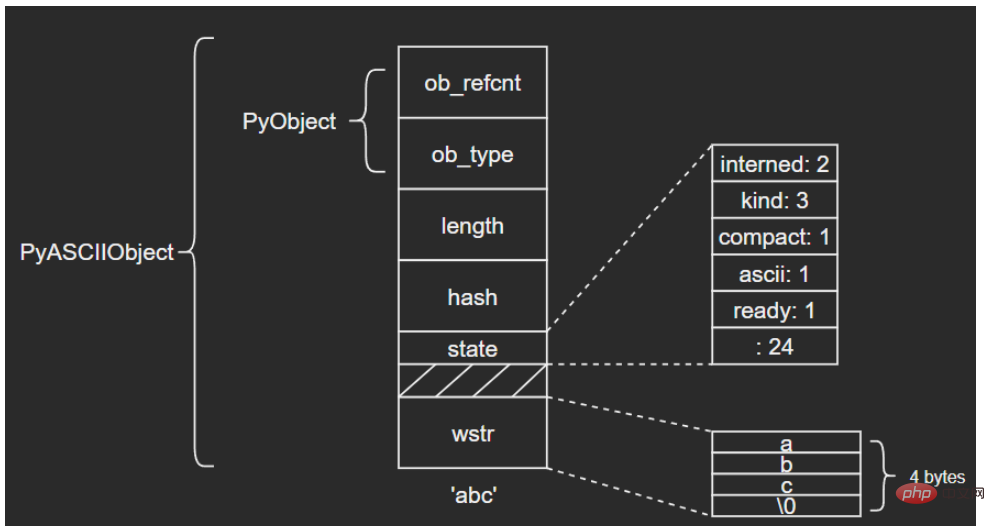
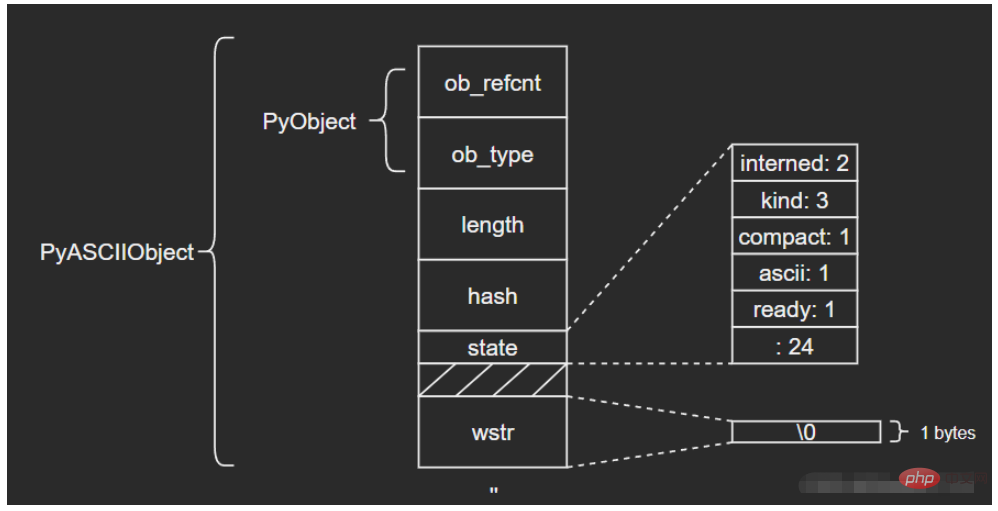
ASCII文本由wstr指向,以’abc’和空字符串对象’'为例:
3.2 PyCompactUnicodeObject
如果文本不全是ASCII,Unicode对象底层便由PyCompactUnicodeObject结构体保存。C源码如下:
1 2 3 4 5 6 7 8 9 10 11 |
|
PyCompactUnicodeObject在PyASCIIObject的基础上增加了3个字段:
utf8_length:文本UTF8编码长度
utf8:文本UTF8编码形式,缓存以避免重复编码运算
wstr_length:wstr的“长度”(这里所谓的长度没有找到很准确的说法,笔者也不太清楚怎么能打印出来,大家可以自行研究下)
注意到,PyASCIIObject中并没有保存UTF8编码形式,这是因为ASCII本身就是合法的UTF8,这也是ASCII文本底层由PyASCIIObject保存的原因。
结构图示:
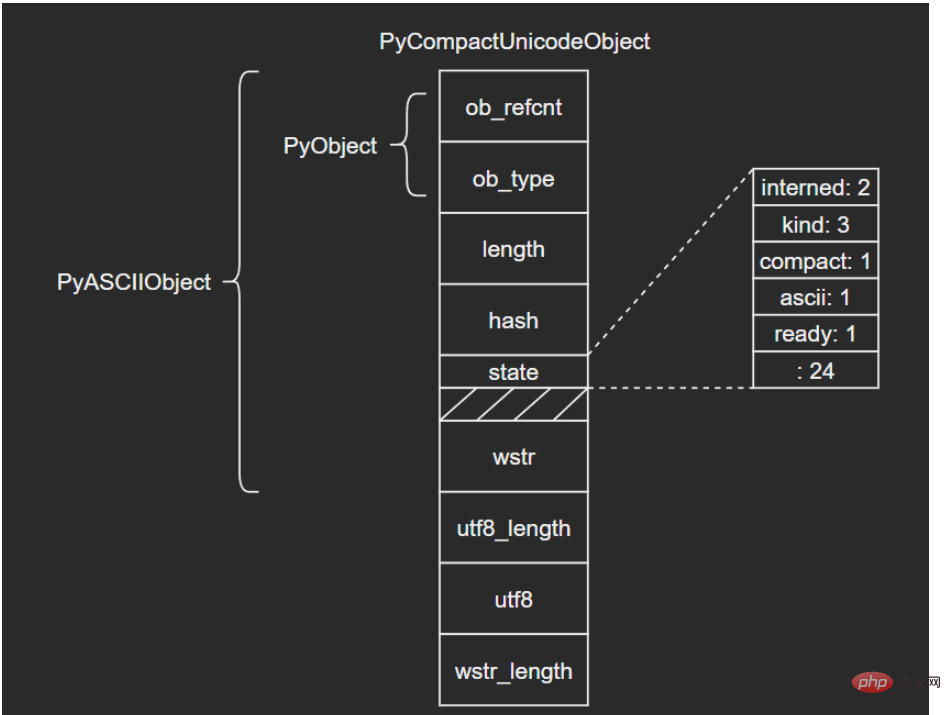
3.3 PyUnicodeObject
PyUnicodeObject则是Python中str对象的具体实现。C源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 |
|
3.4 示例
在日常开发时,要结合实际情况注意字符串拼接前后的内存大小差别:
1 2 3 4 5 6 7 |
|
4 interned机制
如果str对象的interned标志位为1,Python虚拟机将为其开启interned机制,
源码如下:(相关信息在网上可以看到很多说法和解释,这里笔者能力有限,暂时没有找到最确切的答案,之后补充。抱拳~但是我们通过分析源码应该是能看出一些门道的)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
|
可以看到,源码前面还是做一些基本的检查。我们可以看一下37行和50行:将s添加到interned字典中时,其实s同时是key和value(这里我不太清楚为什么会这样做),所以s对应的引用计数是+2了的(具体可以看PyDict_SetDefault()的源码),所以在50行时会将计数-2,保证引用计数的正确。
考虑下面的场景:
1 2 3 4 5 6 7 |
|
由于对象的属性由dict保存,这意味着每个User对象都要保存一个str对象‘name’,这会浪费大量的内存。而str是不可变对象,因此Python内部将有潜在重复可能的字符串都做成单例模式,这就是interned机制。Python具体做法就是在内部维护一个全局dict对象,所有开启interned机制的str对象均保存在这里,后续需要使用的时候,先创建,如果判断已经维护了相同的字符串,就会将新创建的这个对象回收掉。
示例:
由不同运算生成’abc’,最后都是同一个对象:
1 2 3 4 |
|
The above is the detailed content of Python built-in type str source code analysis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1666
1666
 14
1425
52
1325
25
1273
29
1252
24
14
1425
52
1325
25
1273
29
1252
24

 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 How to run sublime code python
Apr 16, 2025 am 08:48 AM
How to run sublime code python
Apr 16, 2025 am 08:48 AM
To run Python code in Sublime Text, you need to install the Python plug-in first, then create a .py file and write the code, and finally press Ctrl B to run the code, and the output will be displayed in the console.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 Golang vs. Python: Performance and Scalability
Apr 19, 2025 am 12:18 AM
Golang vs. Python: Performance and Scalability
Apr 19, 2025 am 12:18 AM
Golang is better than Python in terms of performance and scalability. 1) Golang's compilation-type characteristics and efficient concurrency model make it perform well in high concurrency scenarios. 2) Python, as an interpreted language, executes slowly, but can optimize performance through tools such as Cython.
 Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Writing code in Visual Studio Code (VSCode) is simple and easy to use. Just install VSCode, create a project, select a language, create a file, write code, save and run it. The advantages of VSCode include cross-platform, free and open source, powerful features, rich extensions, and lightweight and fast.
 How to run python with notepad
Apr 16, 2025 pm 07:33 PM
How to run python with notepad
Apr 16, 2025 pm 07:33 PM
Running Python code in Notepad requires the Python executable and NppExec plug-in to be installed. After installing Python and adding PATH to it, configure the command "python" and the parameter "{CURRENT_DIRECTORY}{FILE_NAME}" in the NppExec plug-in to run Python code in Notepad through the shortcut key "F6".

| maxchar < 128 | 128 <= maxchar < 256 | 256 <= maxchar < 65536 | 65536 <= maxchar < MAX_UNICODE | |
|---|---|---|---|---|