

Several tips for avoiding pitfalls when using ChatGLM

I said yesterday that I deployed a set of ChatGLM after returning from the Data Technology Carnival, and planned to study the use of large language models to train database operation and maintenance knowledge base. Many friends did not believe it, saying that you are already this old, Lao Bai, and you can still do it. Are you going to fiddle with these things yourself? In order to dispel the doubts of these friends, I will share with you the process of tossing ChatGLM in the past two days today, and also share some tips on avoiding pitfalls for friends who are interested in tossing ChatGLM.
ChatGLM-6B is developed based on the language model GLM jointly trained by Tsinghua University’s KEG Laboratory and Zhipu AI in 2023. It is a large-scale language model that provides appropriate solutions to user problems and requirements. Replies and support. The above answer is answered by ChatGLM itself. GLM-6B is an open source pre-trained model with 6.2 billion parameters. Its characteristic is that it can be run locally in a relatively small hardware environment. This feature allows applications based on large language models to enter thousands of households. The purpose of the KEG laboratory is to enable the larger GLM-130B model (130 billion parameters, equivalent to GPT-3.5) to be trained in a low-end environment with an 8-way RTX 3090.
#If this goal can really be achieved, it will definitely be good news for people who want to make some applications based on large language models. The current FP16 model of ChatGLP-6B is about a little more than 13G, and the INT-4 quantized model is less than 4GB. It can run on an RTX 3060TI with 6GB of video memory.
I didn’t know much about these situations before deployment, so I bought a 12GB RTX 3060 that was neither high nor low, so after completing the installation and deployment, I still couldn’t run the FP16 model. If I had known better to do testing and verification at home, I would have just bought a cheaper 3060TI. If you want to run a lossless FP16 model, you must get a 3090 with 24GB of video memory.
If you just want to test the capabilities of ChatGLP-6B on your own machine, then you may not need to download THUDM/ChatGLM directly -6B model, there are some packaged quantitative models available for download on huggingface. The model download speed is very slow, you can download the int4 quantitative model directly.
I completed this installation on an I7 8-core PC with an RTX 3060 graphics card of 12G video memory. Because this computer is my work computer, I installed ChatGLM on the WSL subnet. on the system. Installing ChatGLM on the WINDOWS WSL subsystem is more complicated than installing it directly in a LINUX environment. The biggest pitfall is the installation of the graphics card driver. When deploying ChatGLM directly on Linux, you need to install the NVIDIA driver directly and activate the network card driver through modprobe. Installing on WSL is quite different.
ChatGLM can be downloaded from github. There are also some simple documents on the website, even including a document for deploying ChatGLM on WINDOWS WSL. However, if you are a novice in this area and deploy completely according to this document, you will encounter countless pitfalls.
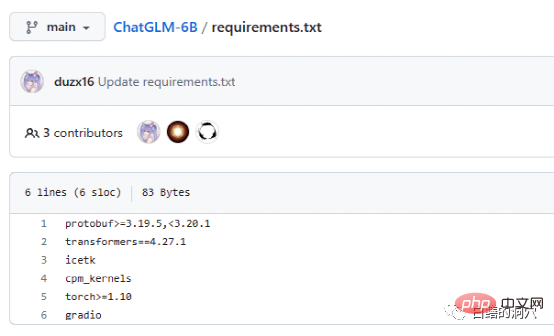
The Requriements.txt document lists the list and version numbers of the main open source components used by ChatGLM. The core is transformers, which requires version 4.27. 1. In fact, the requirements are not so strict. There is no big problem if it is slightly lower, but it is better to use the same version for safety reasons. Icetk is for token processing, cpm_kernels is the core call of the Chinese processing model and cuda, and protobuf is for structured data storage. Gradio is a framework for quickly generating AI applications using Python. I don’t need any introduction to Torch.
ChatGLM can be used in an environment without a GPU, using the CPU and 32GB of physical memory to run, but the running speed is very slow and can only be used for demonstration verification. If you want to play ChatGLM, it is best to equip yourself with a GPU.
The biggest pitfall in installing ChatGLM on WSL is the graphics card driver. The documentation for ChatGLM on Git is very unfriendly. For people who don’t know much about this project or have never done such deployment, the documentation is really confusing. . In fact, software deployment is not troublesome, but the graphics card driver is very tricky.
Because it is deployed on the WSL subsystem, LINUX is only an emulation system, not a complete LINUX. Therefore, NVIDIA's graphics driver only needs to be installed on WINDOWS and does not need to be activated in WSL. However, CUDA TOOLS still needs to be installed in the LINUX virtual environment of WSL. The NVIDIA driver on WINDOWS must install the latest driver from the official website, and cannot use the compatibility driver that comes with WIN10/11. Therefore, do not omit downloading the latest driver from the official website and installing it.
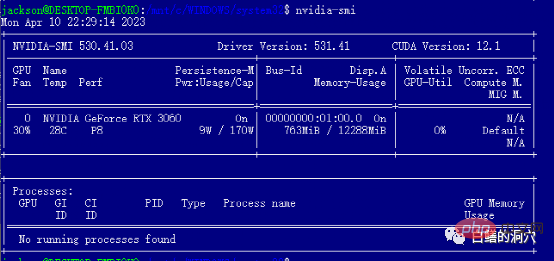
After installing the WIN driver, you can install cuda tools directly in WSL. After the installation is complete, run nvidia-smi and if you can see the above interface , then congratulations, you have successfully avoided the first pit. In fact, you will encounter several pitfalls when installing cuda tools. That is, your system must have appropriate versions of gcc, gcc-dev, make and other compilation-related tools installed. If these components are missing, the installation of cuda tools will fail.
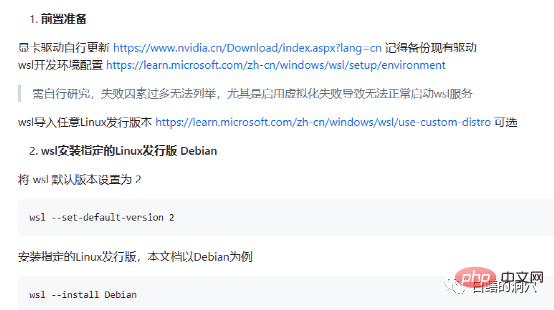
The above is a pitfall of early preparation. In fact, it avoids the pitfall of NVIDIA driver, and the subsequent installation is still very smooth. of. In terms of system selection, I still recommend choosing Debian-compatible Ubuntu. The new version of Ubuntu's aptitude is very smart and can help you solve version compatibility issues with a large number of software and realize automatic version downgrade of some software.
The following installation process can be completed smoothly according to the installation guide. It should be noted that the work of replacing the installation source in /etc/apt/sources.list is best completed according to the guide. On the one hand, the installation speed will be It is much faster, and on the other hand, it also avoids software version compatibility problems. Of course, not replacing it will not necessarily affect the subsequent installation process.
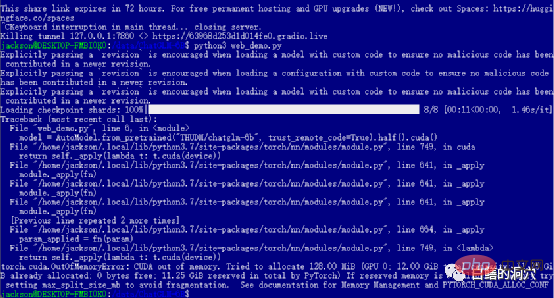
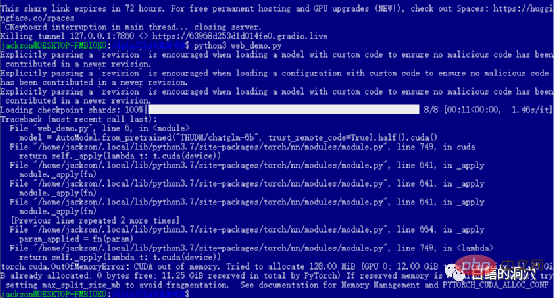
If you successfully passed the previous levels, then you have entered the last step and started web_demo . Executing python3 web_demo.py can start an example of a WEB conversation. At this time, if you are a poor person and only have a 3060 with 12GB of video memory, then you will definitely see the error above. Even if you set PYTORCH_CUDA_ALLOC_CONF to the minimum 21, you cannot avoid this error. At this time you can't be lazy, you must simply rewrite the python script.
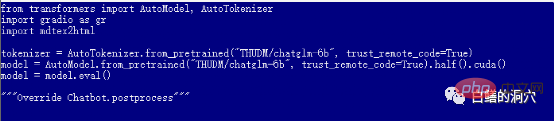
The default web_demo.py uses the FP16 pre-trained model. Models with more than 13GB will definitely not be loaded into the 12GB existing memory. , so you need to make a small adjustment to this code.

You can change to quantize(4) to load the INT4 quantization model, or change to quantize(8) to load the INT8 quantization model. In this way, your graphics card memory will be enough, and it can support you to do various conversations.
It should be noted that the downloading of the model does not really start until web_demo.py is started, so it will take a long time to download the 13GB model. You can do this work in the middle of the night, or You can directly use download tools such as Thunder to download the model from hugging face in advance. If you know nothing about the model and are not very good at installing the downloaded model, you can also modify the model name in the code, THUDM/chatglm-6b-int4, and directly download the INT4 quantized model with less than 4GB from the Internet. This will It’s much faster, but your broken graphics card can’t run the FP16 model anyway.
At this point, you can talk to ChatGLM through the web page, but this is just the beginning of the trouble. Only when you are able to train your fine-tuned model can your journey into ChatGLM truly begin. Playing this kind of thing still requires a lot of energy and money, so be careful when entering the trap.
Finally, I am very grateful to my friends from Tsinghua University’s KEG Laboratory. Their work allows more people to use large language models at low cost.
The above is the detailed content of Several tips for avoiding pitfalls when using ChatGLM. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1655
1655
 14
1413
52
1306
25
1252
29
1226
24
14
1413
52
1306
25
1252
29
1226
24

 Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: A Leap Forward in Multimodal and Mobile AI Meta recently unveiled Llama 3.2, a significant advancement in AI featuring powerful vision capabilities and lightweight text models optimized for mobile devices. Building on the success o
 10 Generative AI Coding Extensions in VS Code You Must Explore
Apr 13, 2025 am 01:14 AM
10 Generative AI Coding Extensions in VS Code You Must Explore
Apr 13, 2025 am 01:14 AM
Hey there, Coding ninja! What coding-related tasks do you have planned for the day? Before you dive further into this blog, I want you to think about all your coding-related woes—better list those down. Done? – Let’
 AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
This week's AI landscape: A whirlwind of advancements, ethical considerations, and regulatory debates. Major players like OpenAI, Google, Meta, and Microsoft have unleashed a torrent of updates, from groundbreaking new models to crucial shifts in le
 Selling AI Strategy To Employees: Shopify CEO's Manifesto
Apr 10, 2025 am 11:19 AM
Selling AI Strategy To Employees: Shopify CEO's Manifesto
Apr 10, 2025 am 11:19 AM
Shopify CEO Tobi Lütke's recent memo boldly declares AI proficiency a fundamental expectation for every employee, marking a significant cultural shift within the company. This isn't a fleeting trend; it's a new operational paradigm integrated into p
 A Comprehensive Guide to Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
A Comprehensive Guide to Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Introduction Imagine walking through an art gallery, surrounded by vivid paintings and sculptures. Now, what if you could ask each piece a question and get a meaningful answer? You might ask, “What story are you telling?
 GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?
Apr 13, 2025 am 10:18 AM
GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?
Apr 13, 2025 am 10:18 AM
Introduction OpenAI has released its new model based on the much-anticipated “strawberry” architecture. This innovative model, known as o1, enhances reasoning capabilities, allowing it to think through problems mor
 How to Add a Column in SQL? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
How to Add a Column in SQL? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
SQL's ALTER TABLE Statement: Dynamically Adding Columns to Your Database In data management, SQL's adaptability is crucial. Need to adjust your database structure on the fly? The ALTER TABLE statement is your solution. This guide details adding colu
 Newest Annual Compilation Of The Best Prompt Engineering Techniques
Apr 10, 2025 am 11:22 AM
Newest Annual Compilation Of The Best Prompt Engineering Techniques
Apr 10, 2025 am 11:22 AM
For those of you who might be new to my column, I broadly explore the latest advances in AI across the board, including topics such as embodied AI, AI reasoning, high-tech breakthroughs in AI, prompt engineering, training of AI, fielding of AI, AI re
