
 Technology peripherals
AI
Want to move half of 'A Dream of Red Mansions' into the ChatGPT input box? Let's solve this problem first
Technology peripherals
AI
Want to move half of 'A Dream of Red Mansions' into the ChatGPT input box? Let's solve this problem first
Want to move half of 'A Dream of Red Mansions' into the ChatGPT input box? Let's solve this problem first


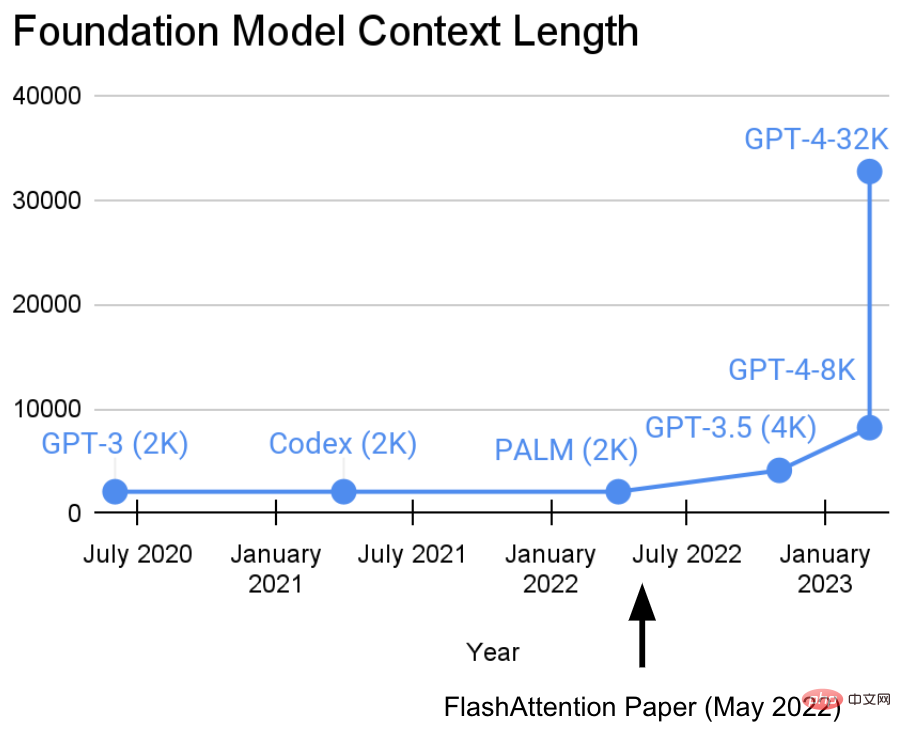
In the past two years, the Hazy Research Laboratory at Stanford University has been engaged in an important task: Increasing sequence length .
They have a view: longer sequences will usher in a new era of basic machine learning models - models that can learn from longer contexts and multiple media sources , complex demonstrations, etc. to learn.Currently, this research has made new progress. Tri Dao and Dan Fu from the Hazy Research laboratory led the research and promotion of the FlashAttention algorithm. They proved that a sequence length of 32k is possible and will be widely used in the current basic model era (OpenAI, Microsoft, NVIDIA and other companies models are using the FlashAttention algorithm).
- ##Paper address: https://arxiv.org/abs/2205.14135
- Code address: https://github.com/HazyResearch/flash-attention
- As the relevant information of GPT4 points out, it Allows nearly 50 pages of text as context, and implements tokenization/patching like Deepmind Gato uses images as context.
In this article, the author introduces new methods for increasing sequence length at a high level and provides a "bridge" to a new set of primitives.
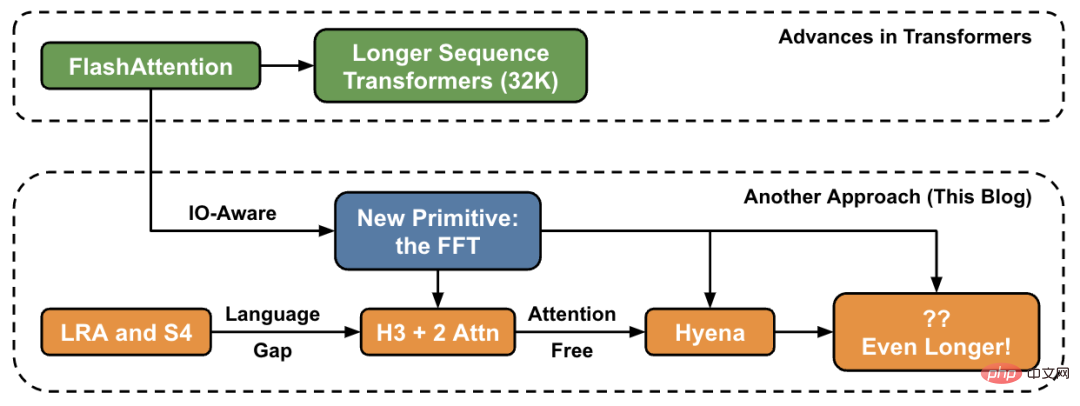
In the Hazy Research lab, this work started with Hippo, then S4, H3, and now Hyena. These models have the potential to handle context lengths in the millions or even billions. FlashAttention speeds up attention and reduces its memory footprint — without any approximation. “Since we released FlashAttention 6 months ago, we’re excited to see many organizations and research labs adopting FlashAttention to accelerate their training and inference,” the blog post reads.
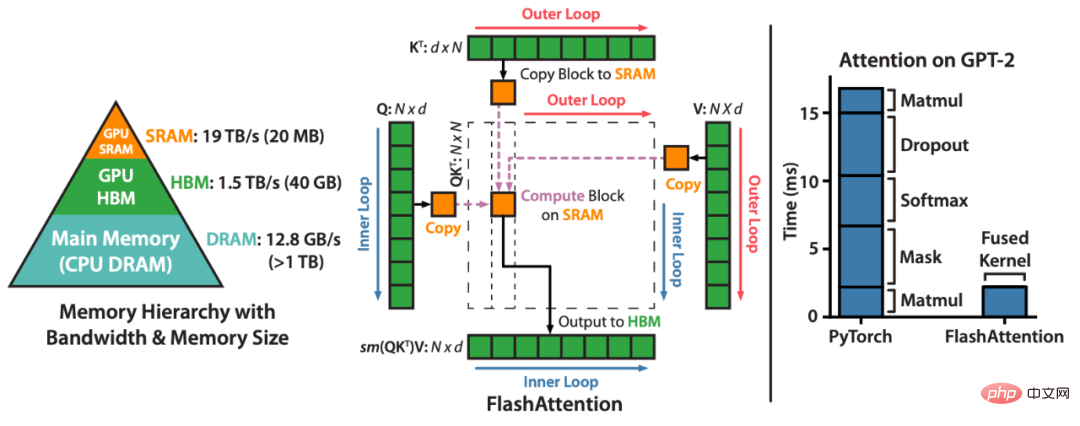
FlashAttention is a method that reorders attention calculations and leverages classic techniques (tiling, recalculation) to speed up and reduce memory usage from quadratic to linear in sequence length algorithm. For each attention head, to reduce memory reads/writes, FlashAttention uses classic tiling techniques to load query, key and value blocks from the GPU HBM (its main memory) to SRAM (its fast cache), computing attention and write the output back to HBM. This reduction in memory reads/writes results in significant speedups (2-4x) in most cases.
Long Range Arena Benchmark and S4
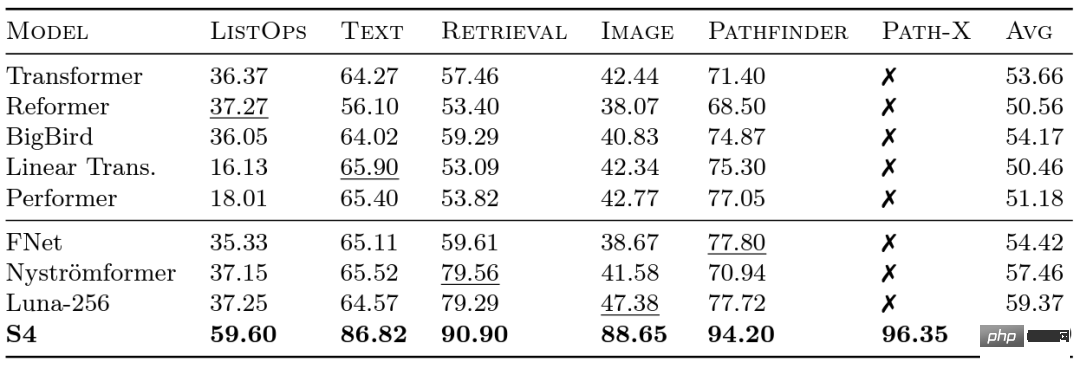
Researchers at Google launched the Long Range Arena (LRA) benchmark in 2020 to evaluate how well different models handle long-range dependencies. LRA is capable of testing a range of tasks covering many different data types and modalities, such as text, images and mathematical expressions, with sequence lengths up to 16K (Path-X: Classification of images unfolded into pixels without any spatial generalization bias). There has been a lot of great work on scaling Transformers to longer sequences, but a lot of it seems to sacrifice accuracy (as shown in the image below). Note the Path-X column: all Transformer methods and their variants perform even worse than random guessing.
#Now let us get to know the S4, which was developed by Albert Gu. Inspired by the LRA benchmark results, Albert Gu wanted to find out how to better model long-range dependencies. Based on long-term research on the relationship between orthogonal polynomials and recursive models and convolutional models, he launched S4—— A new sequence model based on structured state space models (SSMs).
The key point is that the time complexity of SSM when extending a sequence of length N to 2N is  , unlike attention The mechanism also grows at a square level! S4 successfully models long-range dependencies in LRA and becomes the first model to achieve above-average performance on Path-X (now achieving 96.4% accuracy!). Since the release of S4, many researchers have developed and innovated on this basis, with new models such as the S5 model of Scott Linderman's team, Ankit Gupta's DSS (and the subsequent S4D of Hazy Research laboratory), Hasani and Lechner's Liquid-S4, etc. Model.
, unlike attention The mechanism also grows at a square level! S4 successfully models long-range dependencies in LRA and becomes the first model to achieve above-average performance on Path-X (now achieving 96.4% accuracy!). Since the release of S4, many researchers have developed and innovated on this basis, with new models such as the S5 model of Scott Linderman's team, Ankit Gupta's DSS (and the subsequent S4D of Hazy Research laboratory), Hasani and Lechner's Liquid-S4, etc. Model.
In addition, when Hazy Research released FlashAttention, it was already possible to increase the sequence length of Transformer. They also found that Transformer also achieved superior performance on Path-X (63%) simply by increasing the sequence length to 16K.
Shortcomings in modeling
But there is a gap in the quality of S4 in language modeling as high as 5% perplexity (for context, this is 125M models and 6.7B gap between models). To close this gap, researchers have studied synthetic languages such as associative recall to determine what properties a language should possess. The final design was H3 (Hungry Hungry Hippos): a new layer that stacks two SSMs and multiplies their outputs with a multiplication gate.
Using H3, researchers at Hazy Research replaced almost all attention layers in the GPT-style Transformer and were able to achieve high performance in perplexity and Comparable to transformer in terms of downstream evaluation.
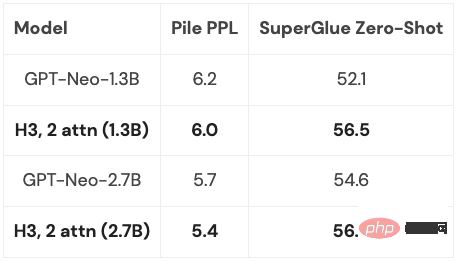
##Since the H3 layer is built on SSM, its computational complexity is also high in terms of sequence length. Growing at the rate of  . The two attention layers make the complexity of the entire model still
. The two attention layers make the complexity of the entire model still
##. This issue will be discussed in detail later. 
Of course, Hazy Research is not the only one considering this direction: GSS also found that SSM with gating can work well with attention in language modeling (which inspired H3), Meta released The Mega model, which also combines SSM and attention, the BiGS model replaces the attention in the BERT-style model, and RWKV has been working on a fully looped approach.
New progress: Hyena
Based on a series of previous work, researchers at Hazy Research were inspired to develop a new architecture: Hyena. They tried to get rid of the last two attention layers in H3 and obtain a model that grows almost linearly for longer sequence lengths. It turns out that two simple ideas are the key to finding the answer:
- #Each SSM can be viewed as a convolutional filter with the same length as the input sequence. Therefore, the SSM can be replaced with a convolution of size equal to the input sequence to obtain a more powerful model with the same computational effort. Specifically, the convolutional filter is implicitly parameterized via another small neural network, drawing on powerful methods from the neural field literature and work on CKConv/FlexConv. In addition, the convolution can be calculated in O (NlogN) time, where N is the sequence length, achieving nearly linear scaling; the gating behavior in
- #H3 can be summarized as: H3 takes three projections of the input and iteratively convolves and applies gating. In Hyena, simply adding more projections and more gates helps generalize to more expressive architectures and close the gap with attention.
Hyena proposed a completely near-linear temporal convolution model for the first time, which can match Transformer in perplexity and downstream tasks, and has achieved good results in experiments. result. And small and medium-sized models were trained on a subset of PILE, and their performance was comparable to Transformer:
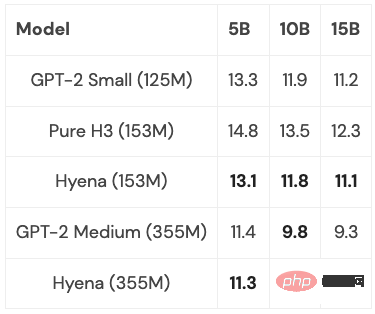
With some optimizations (more on that below), the Hyena model is slightly slower than a Transformer of the same size at a sequence length of 2K, but is faster at longer sequence lengths.
The next thing that still needs to be considered is to what extent can these models be generalized? Is it possible to scale them to the full size of PILE (400B tokens)? What would happen if you combined the best of H3 and Hyena’s ideas, and how far could it go?
FFT or a more basic approach?
A common basic operation in all these models is FFT, which is an efficient way to calculate convolution and only takes O (NlogN) time. However, FFT is poorly supported on modern hardware where the dominant architecture is dedicated matrix multiplication units and GEMMs (e.g. tensor cores on NVIDIA GPUs).
The efficiency gap can be closed by rewriting the FFT as a series of matrix multiplication operations. Members of the research team achieved this goal by using butterfly matrices to explore sparse training. Recently, Hazy Research researchers have leveraged this connection to build fast convolution algorithms such as FlashConv and FlashButterfly, by using butterfly decomposition to transform FFT calculations into a series of matrix multiplication operations.
Additionally, deeper connections can be made by drawing on previous work: including letting these matrices be learned, which also takes the same time but adds additional parameters. Researchers have begun to explore this connection on some small data sets and have achieved initial results. We can clearly see what this connection can lead to (e.g. how to make it suitable for language models):

This extension deserves a deeper exploration: what kind of transformation does this extension learn, and what does it allow you to do? What happens when you apply it to language modeling?
These are exciting directions, and what will follow will be longer and longer sequences and new architectures that will allow us to further explore this new area. We need to pay special attention to applications that can benefit from long sequence models, such as high-resolution imaging, new data formats, language models that can read entire books, etc. Imagine giving an entire book to a language model to read and having it summarize the storyline, or having a code generation model generate new code based on the code you wrote. There are so many possible scenarios, and they are all very exciting.
The above is the detailed content of Want to move half of 'A Dream of Red Mansions' into the ChatGPT input box? Let's solve this problem first. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1663
1663
 14
1420
52
1313
25
1266
29
1239
24
14
1420
52
1313
25
1266
29
1239
24

 Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
Which of the top ten currency trading platforms in the world are among the top ten currency trading platforms in 2025
Apr 28, 2025 pm 08:12 PM
The top ten cryptocurrency exchanges in the world in 2025 include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, KuCoin, Bittrex and Poloniex, all of which are known for their high trading volume and security.
 How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
Bitcoin’s price ranges from $20,000 to $30,000. 1. Bitcoin’s price has fluctuated dramatically since 2009, reaching nearly $20,000 in 2017 and nearly $60,000 in 2021. 2. Prices are affected by factors such as market demand, supply, and macroeconomic environment. 3. Get real-time prices through exchanges, mobile apps and websites. 4. Bitcoin price is highly volatile, driven by market sentiment and external factors. 5. It has a certain relationship with traditional financial markets and is affected by global stock markets, the strength of the US dollar, etc. 6. The long-term trend is bullish, but risks need to be assessed with caution.
 What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
Currently ranked among the top ten virtual currency exchanges: 1. Binance, 2. OKX, 3. Gate.io, 4. Coin library, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9. Bitcoin, 10. bit stamp.
 Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
The top ten cryptocurrency trading platforms in the world include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, KuCoin and Poloniex, all of which provide a variety of trading methods and powerful security measures.
 Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0 redefines crypto asset management through innovative architecture and performance breakthroughs. 1) It solves three major pain points: asset silos, income decay and paradox of security and convenience. 2) Through intelligent asset hubs, dynamic risk management and return enhancement engines, cross-chain transfer speed, average yield rate and security incident response speed are improved. 3) Provide users with asset visualization, policy automation and governance integration, realizing user value reconstruction. 4) Through ecological collaboration and compliance innovation, the overall effectiveness of the platform has been enhanced. 5) In the future, smart contract insurance pools, forecast market integration and AI-driven asset allocation will be launched to continue to lead the development of the industry.
 What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
The top ten digital currency exchanges such as Binance, OKX, gate.io have improved their systems, efficient diversified transactions and strict security measures.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
Handling high DPI display in C can be achieved through the following steps: 1) Understand DPI and scaling, use the operating system API to obtain DPI information and adjust the graphics output; 2) Handle cross-platform compatibility, use cross-platform graphics libraries such as SDL or Qt; 3) Perform performance optimization, improve performance through cache, hardware acceleration, and dynamic adjustment of the details level; 4) Solve common problems, such as blurred text and interface elements are too small, and solve by correctly applying DPI scaling.
