
 Technology peripherals
AI
OpenAI programming language accelerates Bert reasoning 12 times, and the engine attracts attention
Technology peripherals
AI
OpenAI programming language accelerates Bert reasoning 12 times, and the engine attracts attention
OpenAI programming language accelerates Bert reasoning 12 times, and the engine attracts attention

How powerful is one line of code? The Kernl library we are going to introduce today allows users to run the Pytorch transformer model several times faster on the GPU with just one line of code, thus greatly speeding up the model's inference speed.
Specifically, with the blessing of Kernl, Bert’s inference speed is 12 times faster than the Hugging Face baseline. This achievement is mainly due to Kernl writing custom GPU kernels in the new OpenAI programming language Triton and TorchDynamo. The project author is from Lefebvre Sarrut.
##GitHub address: https://github.com/ELS-RD/kernl/
The following is a comparison between Kernl and other inference engines. The numbers in brackets in the abscissa represent batch size and sequence length respectively, and the ordinate is the inference acceleration.
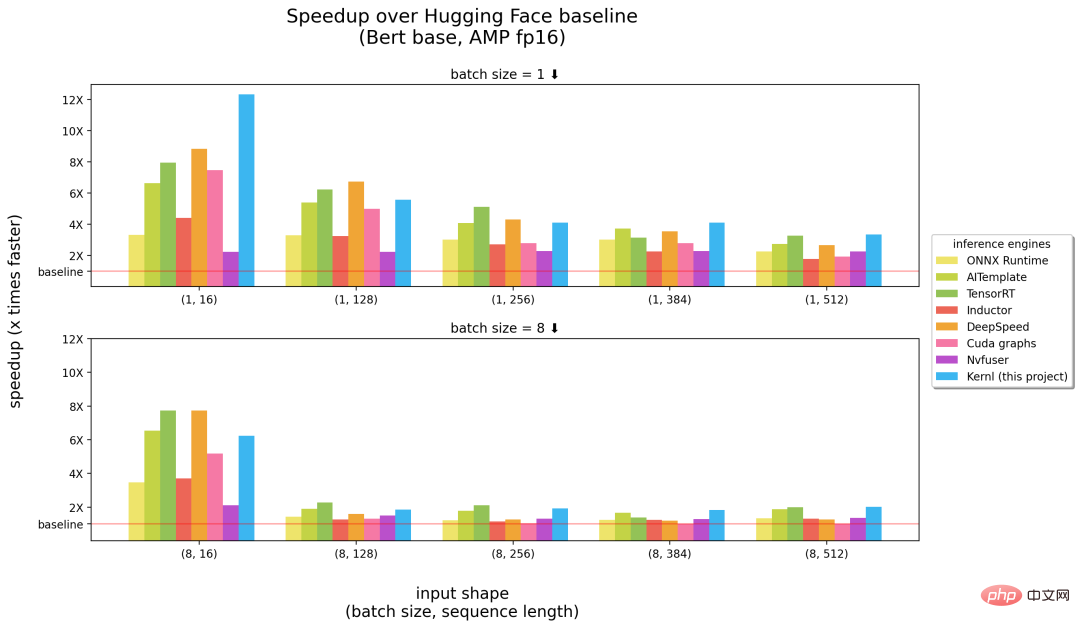
Benchmarks run on a 3090 RTX GPU, and a 12-core Intel CPU.
#From the above results, Kernl can be said to be the fastest inference engine when it comes to long sequence input (right in the figure above) half), is close to NVIDIA's TensorRT (left half in the figure above) on short input sequences. Otherwise, the Kernl kernel code is very short and easy to understand and modify. The project even adds the Triton debugger and tools (based on Fx) to simplify kernel replacement, so no modifications to the PyTorch model source code are required.
Project author Michaël Benesty summarized this research. The Kernl they released is a library for accelerating transformer reasoning. It is very fast and sometimes reaches SOTA performance. Hacked to match most transformer architectures.
They also tested it on T5, which was 6 times faster, and Benesty said this was just the beginning.
Why was Kernl created? At Lefebvre Sarrut, the project author runs several transformers models in production, some of which are latency-sensitive, mainly search and recsys. They are also using OnnxRuntime and TensorRT, and even created the transformer-deploy OSS library to share their knowledge with the community.
Recently, the author has been testing generative languages and working to speed them up. However, doing this using traditional tools has proven to be very difficult. In their view, Onnx is another interesting format. It is an open file format designed for machine learning. It is used to store trained models and has extensive hardware support.
However, the Onnx ecosystem (primarily the inference engine) has several limitations as they deal with the new LLM architecture:
- Exporting a model without control flow to Onnx is simple because tracking can be relied upon. But dynamic behavior is harder to obtain;
- Unlike PyTorch, ONNX Runtime/TensorRT does not yet have native support for multi-GPU tasks that implement tensor parallelism;
- TensorRT cannot manage 2 dynamic axes for a transformer model with the same configuration file. But since you usually want to be able to provide inputs of different lengths, you need to build 1 model per batch size;
- Very large models are common, but Onnx (as a protobuff file) in the file There are some limitations in terms of size and need to be solved by storing the weights outside the model.
A very annoying fact is that new models will never be accelerated, you need to wait for someone else to write a custom CUDA kernel for this. It’s not that existing solutions are bad, one of the great things about OnnxRuntime is its multi-hardware support, and TensorRT is known to be very fast.
So, the project authors wanted to have an optimizer as fast as TensorRT on Python/PyTorch, which is why they created Kernl.
How to do it?
Memory bandwidth is usually the bottleneck of deep learning. In order to speed up inference, reducing memory access is often a good strategy. On short input sequences, the bottleneck is usually related to CPU overhead, which must be eliminated. The project author mainly utilizes the following 3 technologies:
The first is OpenAI Triton, which is a language for writing GPU kernels such as CUDA. Do not confuse it with the Nvidia Triton inference server. It's more efficient. Improvements were achieved by the fusion of several operations such that they chain computations without retaining intermediate results in GPU memory. The author uses it to rewrite attention (replaced by Flash Attention), linear layers and activations, and Layernorm/Rmsnorm.
The second is the CUDA graph. During the warmup step, it saves each launched core and their parameters. The project authors then reconstructed the entire reasoning process.
Finally, there is TorchDynamo, a prototype proposed by Meta to help project authors deal with dynamic behavior. During the warm-up step, it tracks the model and provides an Fx graph (static calculation graph). They replaced some operations of the Fx graph with their own kernel, recompiled in Python.
In the future, the project roadmap will cover faster warm-up, ragged inference (no loss calculation in padding), training support (long sequence support), multi-GPU support (multiple parallelization mode), quantization (PTQ), Cutlass kernel testing of new batches, and improved hardware support, etc.
Please refer to the original project for more details.
The above is the detailed content of OpenAI programming language accelerates Bert reasoning 12 times, and the engine attracts attention. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.io Strategy Upgrade: How to Redefine Crypto Asset Management in MeMebox 2.0?
Apr 28, 2025 pm 03:33 PM
MeMebox 2.0 redefines crypto asset management through innovative architecture and performance breakthroughs. 1) It solves three major pain points: asset silos, income decay and paradox of security and convenience. 2) Through intelligent asset hubs, dynamic risk management and return enhancement engines, cross-chain transfer speed, average yield rate and security incident response speed are improved. 3) Provide users with asset visualization, policy automation and governance integration, realizing user value reconstruction. 4) Through ecological collaboration and compliance innovation, the overall effectiveness of the platform has been enhanced. 5) In the future, smart contract insurance pools, forecast market integration and AI-driven asset allocation will be launched to continue to lead the development of the industry.
 Recommended reliable digital currency trading platforms. Top 10 digital currency exchanges in the world. 2025
Apr 28, 2025 pm 04:30 PM
Recommended reliable digital currency trading platforms. Top 10 digital currency exchanges in the world. 2025
Apr 28, 2025 pm 04:30 PM
Recommended reliable digital currency trading platforms: 1. OKX, 2. Binance, 3. Coinbase, 4. Kraken, 5. Huobi, 6. KuCoin, 7. Bitfinex, 8. Gemini, 9. Bitstamp, 10. Poloniex, these platforms are known for their security, user experience and diverse functions, suitable for users at different levels of digital currency transactions
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
 Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
Which of the top ten currency trading platforms in the world are the latest version of the top ten currency trading platforms
Apr 28, 2025 pm 08:09 PM
The top ten cryptocurrency trading platforms in the world include Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, KuCoin and Poloniex, all of which provide a variety of trading methods and powerful security measures.
 What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
The top ten digital currency exchanges such as Binance, OKX, gate.io have improved their systems, efficient diversified transactions and strict security measures.
 What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
What are the top currency trading platforms? The top 10 latest virtual currency exchanges
Apr 28, 2025 pm 08:06 PM
Currently ranked among the top ten virtual currency exchanges: 1. Binance, 2. OKX, 3. Gate.io, 4. Coin library, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9. Bitcoin, 10. bit stamp.
 How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
How much is Bitcoin worth
Apr 28, 2025 pm 07:42 PM
Bitcoin’s price ranges from $20,000 to $30,000. 1. Bitcoin’s price has fluctuated dramatically since 2009, reaching nearly $20,000 in 2017 and nearly $60,000 in 2021. 2. Prices are affected by factors such as market demand, supply, and macroeconomic environment. 3. Get real-time prices through exchanges, mobile apps and websites. 4. Bitcoin price is highly volatile, driven by market sentiment and external factors. 5. It has a certain relationship with traditional financial markets and is affected by global stock markets, the strength of the US dollar, etc. 6. The long-term trend is bullish, but risks need to be assessed with caution.
