

Learn Python to implement an autonomous driving system


Installation environment
gym is a toolkit for developing and comparing reinforcement learning algorithms. It is relatively simple to install the gym library and its sub-scenarios in python.
Install gym:
pip install gym
Install the automatic driving module, here we use the package highway-env published by Edouard Leurent on github:
pip install --user git+https://github.com/eleurent/highway-env
It contains 6 scenes:
- Highway - "highway-v0"
- Merge - "merge-v0"
- Roundabout - "roundabout-v0"
- Parking - "parking-v0"
- Intersection - "intersection-v0"
- Racing track - "racetrack-v0"
Details The documentation can be found here:
https://www.php.cn/link/c0fda89ebd645bd7cea60fcbb5960309
Configuration environment
Installed Then you can conduct experiments in the code (taking the highway scene as an example):
import gym
import highway_env
%matplotlib inline
env = gym.make('highway-v0')
env.reset()
for _ in range(3):
action = env.action_type.actions_indexes["IDLE"]
obs, reward, done, info = env.step(action)
env.render()
After running, the following scene will be generated in the simulator:
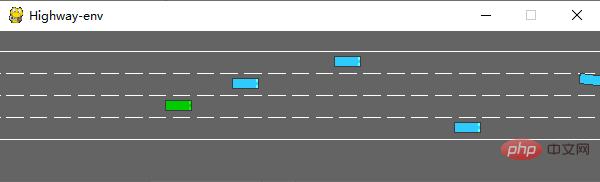
The env class has many parameters that can be configured. For details, please refer to the original document.
Training model
1. Data processing
(1)state
There are no sensors defined in the highway-env package, and all state (observations) of the vehicle are All are read from the underlying code, saving a lot of preliminary work. According to the documentation, state (ovservations) has three output methods: Kinematics, Grayscale Image and Occupancy grid.
Kinematics
Output a matrix of V*F, V represents the number of vehicles that need to be observed (including the ego vehicle itself), and F represents the number of features that need to be counted. Example:
When the data is generated, it will be normalized by default. The value range is: [100, 100, 20, 20]. You can also set the vehicle attributes other than ego vehicle to be the absolute coordinates of the map or the relative coordinates of the ego vehicle. Relative coordinates.
When defining the environment, you need to set the parameters of the feature:
config =
{
"observation":
{
"type": "Kinematics",
#选取5辆车进行观察(包括ego vehicle)
"vehicles_count": 5,
#共7个特征
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8,# [Hz]
"policy_frequency": 2,# [Hz]
}
Grayscale Image
Generate a grayscale image of W*H, where W represents the width of the image. H represents the image height
Occupancy grid
Generate a three-dimensional matrix of WHF, and use a W*H table to represent the vehicle conditions around the ego vehicle. Each grid contains F features.
(2) action
The actions in the highway-env package are divided into two types: continuous and discrete. The continuous action can directly define the values of throttle and steering angle. The discrete action contains 5 meta actions:
ACTIONS_ALL = {
0: 'LANE_LEFT',
1: 'IDLE',
2: 'LANE_RIGHT',
3: 'FASTER',
4: 'SLOWER'
}
(3) reward
Highway-env package uses all except parking scenes. The same reward function:

This function can only be changed in its source code, and the weight can only be adjusted in the outer layer.
(The reward function of the parking scene is included in the original document)
2. Build the model
DQN network. I use the first state representation method - Kinematics for demonstration. . Since the amount of state data is small (5 cars * 7 features), you can ignore the use of CNN and directly convert the size [5,7] of the two-dimensional data to [1,35]. The input of the model is 35. The output is the number of discrete actions, 5 in total.
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as T
from torch import FloatTensor, LongTensor, ByteTensor
from collections import namedtuple
import random
Tensor = FloatTensor
EPSILON = 0# epsilon used for epsilon greedy approach
GAMMA = 0.9
TARGET_NETWORK_REPLACE_FREQ = 40 # How frequently target netowrk updates
MEMORY_CAPACITY = 100
BATCH_SIZE = 80
LR = 0.01 # learning rate
class DQNNet(nn.Module):
def __init__(self):
super(DQNNet,self).__init__()
self.linear1 = nn.Linear(35,35)
self.linear2 = nn.Linear(35,5)
def forward(self,s):
s=torch.FloatTensor(s)
s = s.view(s.size(0),1,35)
s = self.linear1(s)
s = self.linear2(s)
return s
class DQN(object):
def __init__(self):
self.net,self.target_net = DQNNet(),DQNNet()
self.learn_step_counter = 0
self.memory = []
self.position = 0
self.capacity = MEMORY_CAPACITY
self.optimizer = torch.optim.Adam(self.net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
def choose_action(self,s,e):
x=np.expand_dims(s, axis=0)
if np.random.uniform() < 1-e:
actions_value = self.net.forward(x)
action = torch.max(actions_value,-1)[1].data.numpy()
action = action.max()
else:
action = np.random.randint(0, 5)
return action
def push_memory(self, s, a, r, s_):
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.position] = Transition(torch.unsqueeze(torch.FloatTensor(s), 0),torch.unsqueeze(torch.FloatTensor(s_), 0),
torch.from_numpy(np.array([a])),torch.from_numpy(np.array([r],dtype='float32')))#
self.position = (self.position + 1) % self.capacity
def get_sample(self,batch_size):
sample = random.sample(self.memory,batch_size)
return sample
def learn(self):
if self.learn_step_counter % TARGET_NETWORK_REPLACE_FREQ == 0:
self.target_net.load_state_dict(self.net.state_dict())
self.learn_step_counter += 1
transitions = self.get_sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
b_s = Variable(torch.cat(batch.state))
b_s_ = Variable(torch.cat(batch.next_state))
b_a = Variable(torch.cat(batch.action))
b_r = Variable(torch.cat(batch.reward))
q_eval = self.net.forward(b_s).squeeze(1).gather(1,b_a.unsqueeze(1).to(torch.int64))
q_next = self.target_net.forward(b_s_).detach() #
q_target = b_r + GAMMA * q_next.squeeze(1).max(1)[0].view(BATCH_SIZE, 1).t()
loss = self.loss_func(q_eval, q_target.t())
self.optimizer.zero_grad() # reset the gradient to zero
loss.backward()
self.optimizer.step() # execute back propagation for one step
return loss
Transition = namedtuple('Transition',('state', 'next_state','action', 'reward'))
3. Running results
After all parts are completed, they can be combined to train the model. The process is similar to that of CARLA, so I won’t go into details.
Initialization environment (just add the DQN class):
import gym
import highway_env
from matplotlib import pyplot as plt
import numpy as np
import time
config =
{
"observation":
{
"type": "Kinematics",
"vehicles_count": 5,
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8,# [Hz]
"policy_frequency": 2,# [Hz]
}
env = gym.make("highway-v0")
env.configure(config)
Training model:
dqn=DQN()
count=0
reward=[]
avg_reward=0
all_reward=[]
time_=[]
all_time=[]
collision_his=[]
all_collision=[]
while True:
done = False
start_time=time.time()
s = env.reset()
while not done:
e = np.exp(-count/300)#随机选择action的概率,随着训练次数增多逐渐降低
a = dqn.choose_action(s,e)
s_, r, done, info = env.step(a)
env.render()
dqn.push_memory(s, a, r, s_)
if ((dqn.position !=0)&(dqn.position % 99==0)):
loss_=dqn.learn()
count+=1
print('trained times:',count)
if (count%40==0):
avg_reward=np.mean(reward)
avg_time=np.mean(time_)
collision_rate=np.mean(collision_his)
all_reward.append(avg_reward)
all_time.append(avg_time)
all_collision.append(collision_rate)
plt.plot(all_reward)
plt.show()
plt.plot(all_time)
plt.show()
plt.plot(all_collision)
plt.show()
reward=[]
time_=[]
collision_his=[]
s = s_
reward.append(r)
end_time=time.time()
episode_time=end_time-start_time
time_.append(episode_time)
is_collision=1 if info['crashed']==True else 0
collision_his.append(is_collision)
I added some drawing functions to the code, during the running process You can master some key indicators and calculate the average value every 40 times of training.
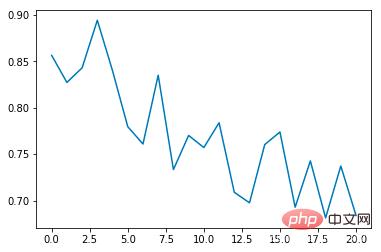
Average collision rate:
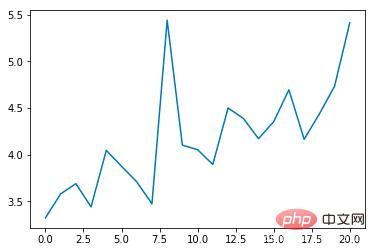
Average epoch duration (s):
Average reward :
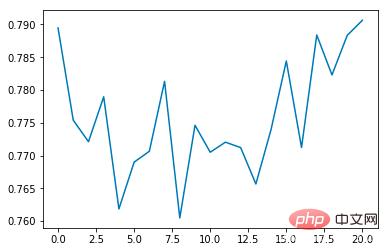
It can be seen that the average collision incidence rate will gradually decrease as the number of training times increases, and the duration of each epoch will gradually extend (if a collision occurs, the epoch will end immediately)
Summary
Compared with the simulator CARLA, the highway-env environment package is significantly more abstract, using a game-like representation so that the algorithm can be trained in an ideal virtual environment. There is no need to consider practical issues such as data acquisition methods, sensor accuracy, and calculation time. It is very friendly for end-to-end algorithm design and testing, but from the perspective of automatic control, there are fewer aspects to start with and it is not very flexible to research.
The above is the detailed content of Learn Python to implement an autonomous driving system. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What are the top ten virtual currency trading apps? Recommended on the top ten digital currency exchange platforms
Apr 22, 2025 pm 01:12 PM
What are the top ten virtual currency trading apps? Recommended on the top ten digital currency exchange platforms
Apr 22, 2025 pm 01:12 PM
The top ten secure digital currency exchanges in 2025 are: 1. Binance, 2. OKX, 3. gate.io, 4. Coinbase, 5. Kraken, 6. Huobi, 7. Bitfinex, 8. KuCoin, 9. Bybit, 10. Bitstamp. These platforms adopt multi-level security measures, including separation of hot and cold wallets, multi-signature technology, and a 24/7 monitoring system to ensure the safety of user funds.
 Python vs. JavaScript: Development Environments and Tools
Apr 26, 2025 am 12:09 AM
Python vs. JavaScript: Development Environments and Tools
Apr 26, 2025 am 12:09 AM
Both Python and JavaScript's choices in development environments are important. 1) Python's development environment includes PyCharm, JupyterNotebook and Anaconda, which are suitable for data science and rapid prototyping. 2) The development environment of JavaScript includes Node.js, VSCode and Webpack, which are suitable for front-end and back-end development. Choosing the right tools according to project needs can improve development efficiency and project success rate.
 The Future of Python and JavaScript: Trends and Predictions
Apr 27, 2025 am 12:21 AM
The Future of Python and JavaScript: Trends and Predictions
Apr 27, 2025 am 12:21 AM
The future trends of Python and JavaScript include: 1. Python will consolidate its position in the fields of scientific computing and AI, 2. JavaScript will promote the development of web technology, 3. Cross-platform development will become a hot topic, and 4. Performance optimization will be the focus. Both will continue to expand application scenarios in their respective fields and make more breakthroughs in performance.
 What is DLC currency? What is the prospect of DLC currency
Apr 24, 2025 pm 12:03 PM
What is DLC currency? What is the prospect of DLC currency
Apr 24, 2025 pm 12:03 PM
DLC coins are blockchain-based cryptocurrencies that aim to provide an efficient and secure trading platform, support smart contracts and cross-chain technologies, and are suitable for the financial and payment fields.
 Which of the top ten transactions in the currency circle? The latest currency circle app recommendations
Apr 24, 2025 am 11:57 AM
Which of the top ten transactions in the currency circle? The latest currency circle app recommendations
Apr 24, 2025 am 11:57 AM
Choosing a reliable exchange is crucial. The top ten exchanges such as Binance, OKX, and Gate.io have their own characteristics. New apps such as CoinGecko and Crypto.com are also worth paying attention to.
 What are the next thousand-fold coins in 2025?
Apr 24, 2025 pm 01:45 PM
What are the next thousand-fold coins in 2025?
Apr 24, 2025 pm 01:45 PM
As of April 2025, seven cryptocurrency projects are considered to have significant growth potential: 1. Filecoin (FIL) achieves rapid development through distributed storage networks; 2. Aptos (APT) attracts DApp developers with high-performance Layer 1 public chains; 3. Polygon (MATIC) improves Ethereum network performance; 4. Chainlink (LINK) serves as a decentralized oracle network to meet smart contract needs; 5. Avalanche (AVAX) trades quickly and
 Bitcoin price today
Apr 28, 2025 pm 07:39 PM
Bitcoin price today
Apr 28, 2025 pm 07:39 PM
Bitcoin’s price fluctuations today are affected by many factors such as macroeconomics, policies, and market sentiment. Investors need to pay attention to technical and fundamental analysis to make informed decisions.
 What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
What are the top ten virtual currency trading apps? The latest digital currency exchange rankings
Apr 28, 2025 pm 08:03 PM
The top ten digital currency exchanges such as Binance, OKX, gate.io have improved their systems, efficient diversified transactions and strict security measures.
