

Developing AI security systems using edge biometrics

Translator | Zhu Xianzhong
Reviewer | Sun Shujuan
Workspace security can be a laborious and time-consuming channel for money loss in companies, especially for companies that handle sensitive information or have data. For companies with multiple offices and thousands of employees. Electronic keys are one of the standard options for automating security systems, but in practice, there are still many disadvantages such as lost, forgotten or counterfeit keys.
Biometrics are a reliable alternative to traditional security measures because they represent the concept of "what you are" authentication. This means that users can use their unique characteristics, such as fingerprints, irises, voice or face, to prove they have access to a space. Using biometrics as an authentication method ensures that keys cannot be lost, forgotten, or counterfeited. Therefore, in this article, we will talk about our experience in developing edge biometrics, which is a combination of edge devices, artificial intelligence and biometrics to implement a security monitoring system based on artificial intelligence technology.
What are edge biometrics?
First, let’s clarify: What is edge AI? In traditional AI architecture, it is common practice to deploy models and data in the cloud, separated from operating devices or hardware sensors. This forces us to keep the cloud servers in a proper state, maintain a stable internet connection, and pay for cloud services. If remote storage cannot be accessed in the event of an internet connection loss, the entire AI application becomes useless.
"In contrast, the idea of edge AI is to deploy artificial intelligence applications on the device, closer to the user. The edge device may have its own GPU, allowing us to process inputs locally on the device.
This provides many advantages such as latency reduction since all operations are performed locally on the device and the overall cost and power consumption also becomes lower. Additionally, since the device can be easily moved from one location to another location, so the entire system is more portable.
Given that we don’t need a large ecosystem, bandwidth requirements are also lower compared to traditional security systems that rely on stable internet connections. Edge devices can even Runs with the connection closed because the data can be stored in the device's internal memory. This makes the entire system design more reliable and robust."
- Daniel Lyadov (Python Engineer at MobiDev)
The only notable drawbacks are that all processing must be done on the device within a short period of time and the hardware components must be powerful enough and up to date to enable this functionality.
For biometric authentication tasks such as face or voice recognition, the rapid response and reliability of the security system are crucial. Because we want to ensure a seamless user experience and appropriate security, relying on edge devices delivers these benefits.
Biometric information, such as an employee's face and voice, seems secure enough because they represent unique patterns that neural networks can recognize. Additionally, this type of data is easier to collect because most businesses already have photos of their employees in their CRM or ERP. This way, you can also avoid any privacy issues by collecting fingerprint samples of your employees.
Combined with edge technology, we can create a flexible AI security camera system for workspace entrances. Below, we will discuss how to implement such a system based on our own company’s development experience and with the help of edge biometrics.
Artificial Intelligence Surveillance System Design
The main purpose of this project is to authenticate employees at the office entrance with just a glance at the camera. The computer vision model is able to recognize a person's face, compare it to previously obtained photos, and then control the automatic opening of the door. As an extra measure, voice verification support will also be added to avoid cheating the system in any way. The entire pipeline consists of 4 models, which are responsible for performing different tasks from face detection to speech recognition.
All these measures are accomplished through a single device that acts as a video/audio input sensor and a controller that sends lock/unlock commands. As an edge device, we chose to use NVIDIA’s Jetson Xavier. This choice was made primarily due to the device’s use of GPU memory (critical for accelerating inference for deep learning projects) and the highly available Jetpack–SDK from NVIDIA, which supports devices based on Python 3 environments. Encode on. Therefore, there is no strict need to convert DS models to another format, and almost all code bases can be adapted by DS engineers to the device; furthermore, there is no need to rewrite from one programming language to another.
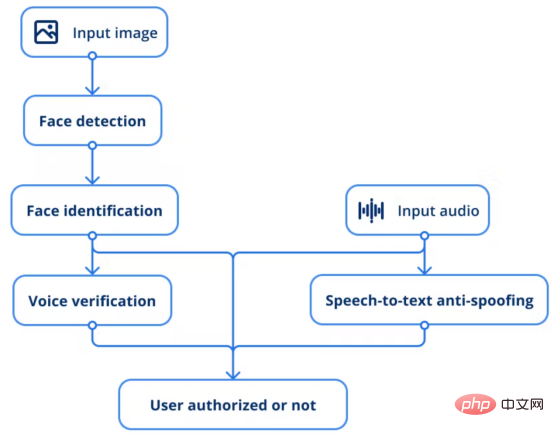 AI security system workflow
AI security system workflow
According to the above description, the entire process follows the following flow:
1. Provide the input image to Face detection model to find users.
2. The facial recognition model performs inference by extracting vectors and comparing them to existing employee photos to determine if it is the same person.
3. Another model is to verify the voice of a specific person through voice samples.
4. In addition, a speech-to-text anti-spoofing solution is adopted to prevent any type of spoofing technology.
Next, let us discuss each implementation link and explain the training and data collection process in detail.
Data collection
Before delving into the system modules, be sure to pay attention to the database used. Our system relies on providing users with so-called reference or ground truth data. The data currently includes precomputed face and speech vectors for each user, which look like an array of numbers. The system also stores successful login data for future retraining. Given this, we chose the most lightweight solution, SQLite DB. With this database, all data is stored in one file that is easy to browse and backup, and the learning curve for data science engineers is shorter.
Because facial recognition requires photos of all employees who may come into the office, we use facial photos stored in the company's database. Jetson devices placed at office doorways also collect facial data samples when people use facial verification to open doors.
Initially voice data was not available, so we organized the data collection and asked people to record 20-second clips. We then use the speech verification model to get each person's vector and store it in the database. You can capture speech samples using any audio input device. In our project we use a portable phone and a webcam with a built-in microphone to record the sound.
Face Detection
Face detection can determine whether a human face is present in a given scene. If so, the model should give you the coordinates of each face so that you know where each face is on the image, including facial landmarks. This information is important because we need to receive a face in the bounding box in order to run face recognition in the next step.
For face detection, we used the RetinaFace model and the MobileNet key components from the InsightFace project. The model outputs four coordinates for each detected face on the image along with 5 face labels. In fact, images taken at different angles or using different optics may change the proportions of the face due to distortion. This may cause the model to have difficulty identifying the person.
To meet this need, facial landmarks are used for morphing, a technique that reduces the differences that may exist between these images of the same person. Therefore, the obtained cropped and distorted surfaces look more similar, and the extracted face vectors are more accurate. Facial Recognition
The next step is face recognition. In this stage, the model has to recognize the person from the given image (i.e. the obtained image). The identification is done with the help of reference (ground truth data). So here, the model will compare two vectors by measuring the distance score of the difference between them to determine if it is the same person standing in front of the camera. The evaluation algorithm will compare it to an initial photo we have of an employee.
Face recognition is completed using the model of the SE-ResNet-50 architecture. In order to make the model results more robust, the image will be flipped and averaged before getting the face vector input. At this point, the user identification process is as follows:
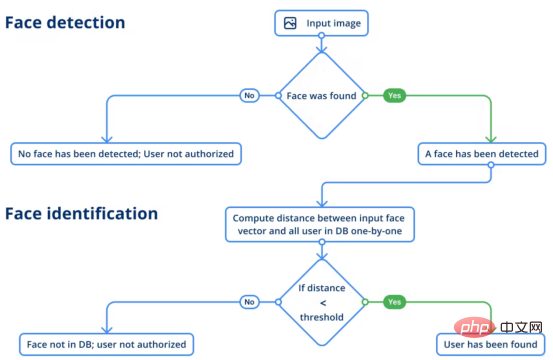 Face and voice verification process
Face and voice verification process
Voice verification
Next, we move to voice Verification link. This step should be done to verify that both audios contain the same person's voice. You may ask, why not consider speech recognition? The answer is that facial recognition is now much better than speech, and images can provide more information than speech to identify a user. In order to avoid identifying user A by face and user B by voice, the system only uses a facial recognition solution.
The basic logic is almost the same as the face recognition stage, as we compare two vectors by the distance between them, unless we find similar vectors. The only difference is that we already have a hypothesis about who is the person trying to pass from the previous face recognition module.
During the active development of the Voice Verification module, a number of issues arose.
Previous models using Jasper architecture were unable to verify recordings made by the same person from different microphones. Therefore, we solved this problem by using the ECAPA-TDNN architecture, which was trained on the VoxCeleb2 dataset of the SpeechBrain framework, which Do a better job of validating employees.
However, the audio clips still require some pre-processing. The aim is to improve audio recording quality by preserving sound and reducing current background noise. However, all testing techniques severely affect the quality of speech verification models. Most likely, even the slightest noise reduction will change the audio characteristics of the speech in the recording, so the model will not be able to correctly authenticate the person. Additionally, we investigated the length of the audio recording and how many words the user should pronounce. As a result of this investigation, we made a number of recommendations. The conclusion is: the duration of such a recording should be at least 3 seconds and approximately 8 words should be read aloud. Voice-to-text anti-spoofing
The last security measure is that the system applies voice-to-text anti-spoofing based on
QuartzNetin the Nemo framework . This model provides a good user experience and is suitable for real-time scenarios. To measure how close what a person says is to the system's expectations, the Levenshtein distance between them needs to be calculated.
Obtaining photos of employees to fool facial verification modules is an achievable task, along with recording voice samples. Speech-to-text anti-spoofing does not cover scenarios in which an intruder attempts to gain entry to an office using photos and audio of authorized personnel. The idea is simple: when each person authenticates themselves, they speak the phrase given by the system. A phrase consists of a set of randomly selected words. Although the number of words in a phrase is not that large, the actual number of possible combinations is quite huge. Applying randomly generated phrases, we eliminate the possibility of spoofing the system, which would require an authorized user to speak a large number of recorded phrases. Having a photo of a user is not enough to fool an AI security system with this protection.
Benefits of Edge Biometric SystemsAt this point, our Edge Biometric System lets users follow a simple process that requires them to speak a randomly generated phrase to unlock the door . Additionally, we provide AI surveillance services for office entrances through face detection.
Voice verification and speech-to-text anti-spoofing module“The system can be easily modified to extend to different scenarios by adding multiple edge devices Medium. Compared to a normal computer, we can configure Jetson directly over the network, establish connections with low-level devices through GPIO interfaces, and easily upgrade with new hardware. We can also integrate with any digital security system that has a web API.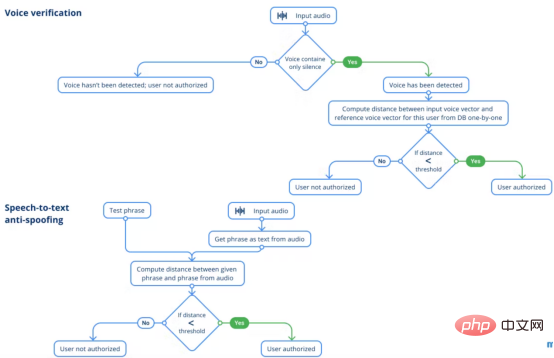 But the main benefit of this solution is that we can improve the system by collecting data directly from the device, because collecting data at the entrance seems to be very convenient without any specific interruption.”
But the main benefit of this solution is that we can improve the system by collecting data directly from the device, because collecting data at the entrance seems to be very convenient without any specific interruption.”
——Daniel Lyadov (Python engineer at MobiDev)
Translator introduction
Zhu Xianzhong, 51CTO community editor, 51CTO expert blogger, lecturer, computer teacher at a university in Weifang , a veteran in the freelance programming world.
Original title: Developing AI Security Systems With Edge Biometrics , Author: Dmitriy Kisil
The above is the detailed content of Developing AI security systems using edge biometrics. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1666
1666
 14
1426
52
1328
25
1273
29
1254
24
14
1426
52
1328
25
1273
29
1254
24

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
