
 Backend Development
Python Tutorial
Python example detailed explanation of pdfplumber reading PDF and writing to Excel
Backend Development
Python Tutorial
Python example detailed explanation of pdfplumber reading PDF and writing to Excel
Python example detailed explanation of pdfplumber reading PDF and writing to Excel

This article brings you relevant knowledge about python, which mainly introduces the related issues about pdfplumber reading PDF and writing to Excel, including the installation of pdfplumber module, loading PDF, and Let’s take a look at some practical operations and so on. I hope it will be helpful to everyone.

Recommended learning: python video tutorial
1. Python operation PDF 13 large library comparison
PDF ( Portable Document Format) is a portable document format that facilitates the dissemination of documents across operating systems. PDF documents follow a standard format, so there are many tools that can operate on PDF documents, and Python is no exception.
Comparison chart of Python operating PDF modules is as follows:
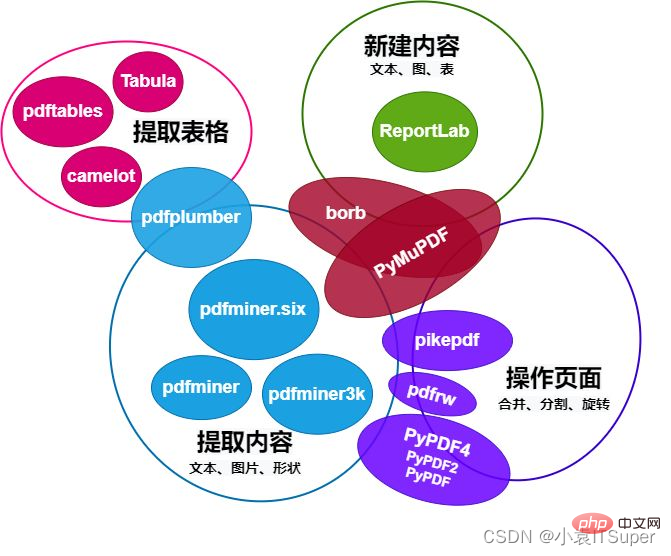
This article mainly introduces pdfplumberFocus on PDF content extraction, such as text (position, font and colors, etc.) and shapes (rectangles, straight lines, curves), as well as the function of parsing tables.
2. pdfplumber module
Several other Python libraries help users extract information from PDFs. As a broad overview, pdfplumber differentiates itself from other PDF processing libraries by combining the following features:
- Easy access to detailed information about each PDF object
- Used for Higher-level, customizable methods for extracting text and tables
- Tightly integrated visual debugging
- Other useful utility features such as filtering objects by crop boxes
1. Installation
cmd console input:
pip install pdfplumber
Guide package:
import pdfplumber
Case PDF screenshot (two pages are not cut off):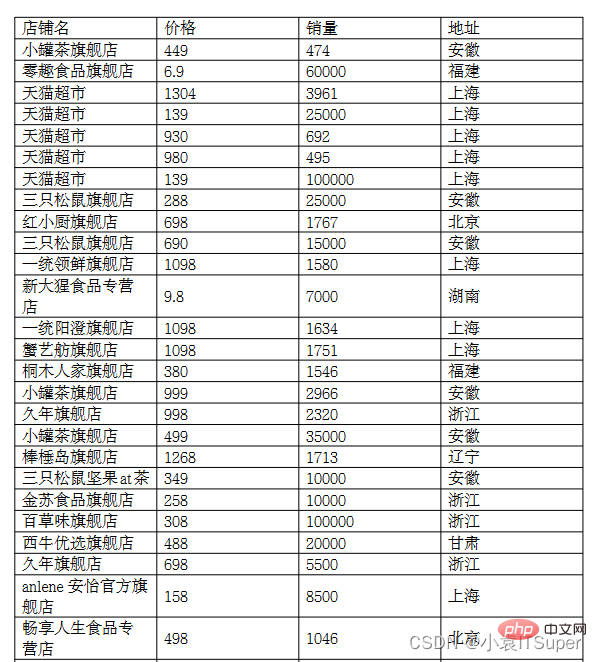
2. Load PDF
Read PDF code: pdfplumber.open("path/filename.pdf", password = "test", laparams = { "line_overlap": 0.7 })
Parameter interpretation:
-
password: To load a password-protected PDF, please pass the password keyword parameter -
laparams: To set the layout analysis parameters to the layout engine of pdfminer.six, pass the laparams keyword argument
Case code:
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf)
print(type(pdf))Output Result:
<pdfplumber.pdf.pdf><class></class></pdfplumber.pdf.pdf>
3. pdfplumber.PDF class
pdfplumber.PDF class represents a single PDF and has two main properties:
| Properties | Description |
|---|---|
##.metadata | From PDF Get the metadata key/value pair dictionary from Info. Usually includes "CreationDate", "ModDate", "Producer", etc.
|
.pages | Returns a list containing pdfplumber.Page instances, each instance represents the information of each page of the PDF
1. Read PDF document information (.metadata) :
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(pdf.metadata){'Author': 'wangwangyuqing', 'Comments': '', 'Company': '', 'CreationDate': "D:20220330113508+03'35'", 'Creator': 'WPS 文字', 'Keywords': '', 'ModDate': "D:20220330113508+03'35'", 'Producer': '', 'SourceModified': "D:20220330113508+03'35'", 'Subject': '', 'Title': '', 'Trapped': 'False'}2. Output the total number of pages
import pdfplumberwith pdfplumber.open("./1.pdf") as pdf:
print(len(pdf.pages))2
pdfplumber.PageThe class is the core of pdfplumber. Most operations revolve around this class. It has the following attributes:
| Description | |
|---|---|
.page_number | Sequential page numbers, starting from 1 on the first page, starting from the second page 2, and so on analogy. |
.width | The width of the page. |
.height | The height of the page. |
.objects/.chars/.lines/.rects/.curves/.figures/.images | Each of these properties is a list, each containing a dictionary for each such object embedded on the page. See "Objects" below for details.
Commonly used methods are as follows:
| Description | |
|---|---|
.extract_text() | is used to extract the text in the page and organize all the character objects on the page into That string |
.extract_words() | returns all the words and their related information|
.extract_tables() | Extract the tables of the page|
.to_image() | When used for visual debugging, return an instance of the PageImage class|
.close() | By default, the Page object caches its layout and object information to avoid reprocessing it. However, these cached properties can require a lot of memory when parsing large PDFs. You can use this method to flush the cache and free up memory.
The above is the detailed content of Python example detailed explanation of pdfplumber reading PDF and writing to Excel. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1658
1658
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 How to run sublime code python
Apr 16, 2025 am 08:48 AM
How to run sublime code python
Apr 16, 2025 am 08:48 AM
To run Python code in Sublime Text, you need to install the Python plug-in first, then create a .py file and write the code, and finally press Ctrl B to run the code, and the output will be displayed in the console.
 Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Writing code in Visual Studio Code (VSCode) is simple and easy to use. Just install VSCode, create a project, select a language, create a file, write code, save and run it. The advantages of VSCode include cross-platform, free and open source, powerful features, rich extensions, and lightweight and fast.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 How to run python with notepad
Apr 16, 2025 pm 07:33 PM
How to run python with notepad
Apr 16, 2025 pm 07:33 PM
Running Python code in Notepad requires the Python executable and NppExec plug-in to be installed. After installing Python and adding PATH to it, configure the command "python" and the parameter "{CURRENT_DIRECTORY}{FILE_NAME}" in the NppExec plug-in to run Python code in Notepad through the shortcut key "F6".
