
 Database
Mysql Tutorial
Detailed analysis of MySQL to quickly build a master-slave replication architecture
Database
Mysql Tutorial
Detailed analysis of MySQL to quickly build a master-slave replication architecture
Detailed analysis of MySQL to quickly build a master-slave replication architecture

This article brings you relevant knowledge about mysql, which mainly introduces the related issues of how to quickly build a master-slave replication architecture. The master-slave replication function provided by the MySQL database can be easily implemented Data is automatically backed up on multiple servers to expand the database and greatly enhance data security. I hope it will be helpful to everyone.

Recommended learning: mysql tutorial
1. Master-slave replication and separation of reading and writing
1.1 Master-slave replication (data level)
Master-slave replication is the prerequisite for read-write separation. The master-slave replication function provided by the MySQL database can easily realize automatic backup of data on multiple servers, realize the expansion of the database, and greatly enhance the security of the data. At the same time, after master-slave replication is implemented, the load performance of the database can be further enhanced by implementing read-write separation.
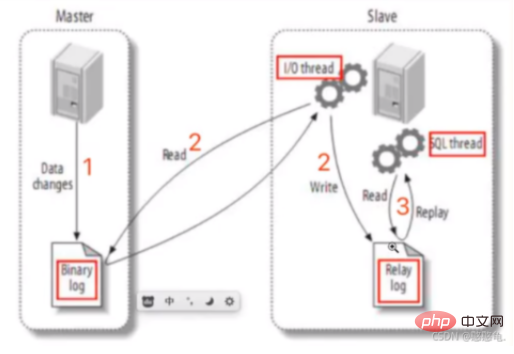
As shown in the figure is the general implementation process of master-slave replication.
1.2 Read-write separation (business level)
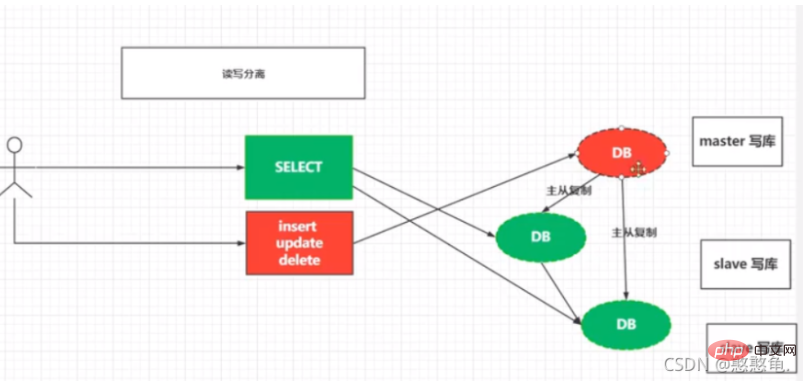
Read-write separation is based on master-slave replication. Only master-slave replication of the database is realized. , in order to further realize the separation of reading and writing. Read-write separation can be understood as all query operations are performed in the sub-database, and all write operations are performed in the main database. After the data is written to the main database, the data is backed up to the sub-database through master-slave replication to ensure data consistency.
2. Implementation
Let’s first understand the principle of master-slave replication:
- First, be the data of the master database After changes occur, the change record will be written to the binlog log.
- The slave database will detect the binlog log in the master database within a certain period of time. If changes occur, it will request the master log file information.
After understanding its principle, we need to know the prerequisites for enabling master-slave replication:
The master node needs to enable binlog logs (mysql does not enable binlog by default)
-
slave node, specify a binlog file, and synchronized offset
Specify the ip of the master node
-
Username and password for executing the master node
Now we all understand it roughly, let’s build a database model with one master and one slave and demonstrate it. Configuration process of database master-slave setup.
Prepare two CentOS servers and install mysql5.7 in advance.
2.1 Open the binlog log of the master server
Edit the my.cnf file of mysql: (The installation method is different, the file location may be different, specific analysis of the specific problem~)
vim /etc/my.cnf
The original file does not have the following content, we need to add it ourselves. My side is to perform master-slave replication of data in the myslave database
server-id = 1 #server-id 服务器唯一标识log_bin = master-bin #log_bin 启动MySQL二进制日志log_bin_index = master-bin.index binlog_do_db = myslave #binlog_do_db 指定记录二进制日志的数据库 这两个指定可以不添加binlog_ignore_db = mysql #binlog_ignore_db 指定不记录二进制日志的数据库
Use the following command to restart mysql. Different Linux versions may have different commands.
service mysql restart
After successful startup, we can see the bin-log opening status through the following statement: (Query directly in Navicat)
show variables like 'log_bin%';

2.2 Remote access
#允许远程用户访问 GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.221.131' IDENTIFIED BY '123456' WITH GRANT OPTION; #刷新 FLUSH PRIVILEGES;
2.3 Slave node configuration
- First on the master node, run the following command to understand the status of the master node and get the information as shown in the figure below.
show master status;

-
Modify related configurations
vim /etc/my.cnf
Copy after loginCopy after loginAdd relevant information:
server-id = 2 #唯一标识relay-log = slave-relay-bin relay-log-index = slave-relay-bin.index replicate-do-db=myslave #备份数据库 对应master中设置的,可以不设置replicate-ignore-db=mysql #忽略数据库
Copy after loginRemember to restart the service;
service mysql restart
Copy after loginCopy after login -
Execute the following command on the slave node.
change master to master_host='192.168.221.128',master_user='root',master_password='123456',master_log_file='binlog.000009',master_log_pos=2339;
Copy after loginmaster_log_file is the file name obtained in the first step;
master_log_pos is the synchronization position obtained in the first step;
-
Start slave synchronization
start slave;
Copy after login -
Check the synchronization status and get the status shown in the figure below, which means that the master-slave synchronization is successfully established. Table tests can be created in the main database.
show slave status\G
Copy after login

Recommended learning: mysql learning tutorial
The above is the detailed content of Detailed analysis of MySQL to quickly build a master-slave replication architecture. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
The main role of MySQL in web applications is to store and manage data. 1.MySQL efficiently processes user information, product catalogs, transaction records and other data. 2. Through SQL query, developers can extract information from the database to generate dynamic content. 3.MySQL works based on the client-server model to ensure acceptable query speed.
 How to start mysql by docker
Apr 15, 2025 pm 12:09 PM
How to start mysql by docker
Apr 15, 2025 pm 12:09 PM
The process of starting MySQL in Docker consists of the following steps: Pull the MySQL image to create and start the container, set the root user password, and map the port verification connection Create the database and the user grants all permissions to the database
 Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel is a PHP framework for easy building of web applications. It provides a range of powerful features including: Installation: Install the Laravel CLI globally with Composer and create applications in the project directory. Routing: Define the relationship between the URL and the handler in routes/web.php. View: Create a view in resources/views to render the application's interface. Database Integration: Provides out-of-the-box integration with databases such as MySQL and uses migration to create and modify tables. Model and Controller: The model represents the database entity and the controller processes HTTP requests.
 Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
I encountered a tricky problem when developing a small application: the need to quickly integrate a lightweight database operation library. After trying multiple libraries, I found that they either have too much functionality or are not very compatible. Eventually, I found minii/db, a simplified version based on Yii2 that solved my problem perfectly.
