
 Database
Mysql Tutorial
Let's analyze MySQL's high-availability architecture technology together
Database
Mysql Tutorial
Let's analyze MySQL's high-availability architecture technology together
Let's analyze MySQL's high-availability architecture technology together

This article brings you relevant knowledge about the technical analysis of mysql medium and high availability architecture. It mainly introduces the technical analysis of MMM, MySQL master-slave architecture and Cluster-related issues. I hope it will be helpful to you. Everyone is helpful.

Background Description
With the development of information technology, enterprises increasingly rely on information management. The data information of each business application is mainly stored in In databases, enterprises have increasingly higher requirements for the continuity of access to these data. In order to avoid various losses caused by data interruption, the high availability of databases has become a top priority in enterprise information construction. At the same time, key businesses in industries or fields related to the national economy and people's livelihood, such as telecommunications, finance, energy, and military industry, require high availability for key data storage. The data system must be guaranteed to run 24/7 to prevent data loss and damage. Click to get programming learning materials
Introduction to high-availability architecture
High-availability architectureIt is basically standard for Internet services. Both application services and database services need to be high-availability. Available. For a system, may contain many modules, such as front-end applications, caches, databases, searches, message queues, etc. Each module needs to be highly available to ensure the high availability of the entire system . For database services, high availability may be more complex. The availability of services to users requires not only access, but also correctness guarantees. Therefore, high availability of databases requires more authentication.
MySQL High Availability Architecture Classification
- MySQL implements MMM for high availability
- MySQL implements high availability for MHA
- MySQL implements high availability Cluster mode to achieve high availability from the architecture
- MySQL
Technical analysis of MMM
MMM (Master-Master replication manager for MySQL) is a set of A script program that supports dual-master failover and daily management of dual-master.
MMM is developed using the Perl language. It is mainly used to monitor and manage MySQL Master-Master (dual-master) replication. Although it is called dual-master replication, it is only allowed at the same time in business. Write to one master, and provide partial read services on the other alternate master to speed up the warm-up of the alternate master at the time of master-to-master switching.
The monitoring end of MMM will Provide multiple virtual IPs (VIPs), including a writable VIP and multiple readable VIPs. Through supervisory management, these IPs will be bound to the available mysql. When a certain mysql goes down, it will be vip migrated to other mysql.
#On the one hand, the MMM script program implements the failover function. On the other hand, its additional internal tool scripts can also achieve read load balancing of multiple slaves.
This package can also read load balance across any number of slave servers based on a standard master-slave configuration, so you can use it to start up on a group of replicated servers. Virtual IP, in addition, it also has scripts to implement data backup and resynchronization functions between nodes.
MMM basic component analysis
- mmm_mond: Monitoring process, responsible for all monitoring work, deciding and processing all node role activities . Therefore, the script needs to be run on a supervisor.
- mmm_agentd: The agent process running on each msql server completes monitoring probe work and performs simple remote service settings. This script needs to be run on the monitored machine.
- mmm_control: A simple script that provides commands to manage mmm_mond.
Basic implementation principle of MMM implementation
MMM provides automatic and manual methods to remove the virtual IP of a server with high replication delay in a group of servers. , and it can also back up data and achieve data synchronization between two nodes.
MySQL itself does not provide a replication failover solution. Server failover can be achieved through the MMM solution, thereby achieving high availability of mysql.
Usage scenarios of MMM
Since MMM cannot completely guarantee data consistency, MMM is suitable for applications where data consistency requirements are not very high, but Scenarios where you want to ensure business availability to the greatest extent.
For those businesses that have high requirements for data consistency, it is highly not recommended to use a high-availability architecture like MMM.
- The MMM project comes from Google: code.google.com/p/mysql-mas…
- The official website is: mysql-mmm.org
Introduction to MHA
MHA (Master High Availability) is currently a relatively mature solution for MySQL high availability. It was developed by Youshimaton of Japan's DeNA Company (now working at Facebook) and is an excellent set of solutions. High-availability software for failover and master-slave promotion in MySQL high-availability environment. During the MySQL failover process, MHA can automatically complete the database failover operation within 0 to 30 seconds, and during the failover process, MHA can ensure data consistency to the greatest extent to achieve true High availability in the sense.
MHA is an open source MySQL high-availability program. When MHA monitors a master node failure, it will automatically promote the slave node with the latest data to become the new master node.
MHA will obtain additional information from other nodes to avoid consistency problems, that is, MHA will obtain data information from other slave nodes and send the information to the closest master node A slave node, so that when the master node fails, this slave node will be promoted to the master node, and this slave node has all the data information of other slave nodes.
MHA also provides the online switching function of the master node, that is, switching the master/slave node on demand.
Basic components of MHA
MHA consists of two parts: MHA Manager (management node) and MHA Node (data node).
MHA Manager can be deployed separately on an independent machine to manage multiple master-slave clusters, or it can be deployed on a slave node.
MHA implementation principle
- MHA Node runs on each MySQL server. MHA Manager will regularly detect the master node in the cluster. When the master fails, it can automatically The slave with the latest data is promoted to the new master, and then all other slaves are redirected to the new master. The entire failover process is completely transparent to the application.
- During the MHA automatic failover process, MHA tries to save the binary log from the downed main server to ensure that data is not lost to the greatest extent, but this is not always feasible.
- For example, if the main server hardware fails or cannot be accessed through ssh, MHA cannot save the binary log and only fails over and loses the latest data. Using MySQL 5.5's semi-synchronous replication, you can reduce the risk of data loss.
- MHA can be combined with semi-synchronous replication. If only one slave has received the latest binary log, MHA can apply the latest binary log to all other slave servers, thus ensuring the data of all nodes. consistency.
Usage scenarios of MHA
Currently, MHA mainly supports a one-master, multiple-slave architecture.
To build MHA, a replication cluster must have at least three database servers, one master and two slaves, that is, one acts as the master, one acts as the backup master, and the other acts as the slave. Library.
Because at least three servers are required, Taobao has also made modifications on this basis due to machine cost considerations. Currently, Taobao TMHA supports one master and one slave.
From a code perspective, MHA is just a set of Perl scripts. So I believe that with Alibaba’s technical strength, it is not difficult to change MHA to support one master and one slave.
MySQL master-slave architecture
This kind of architecture is commonly used by start-ups, and it also facilitates subsequent expansion step by step
Features of this architecture
- Low cost, fast and convenient deployment
- Separation of reading and writing
- It can also reduce the pressure of reading the library by adding slave libraries in time
- Master library Single point of failure
- Data consistency problem (caused by synchronization delay)
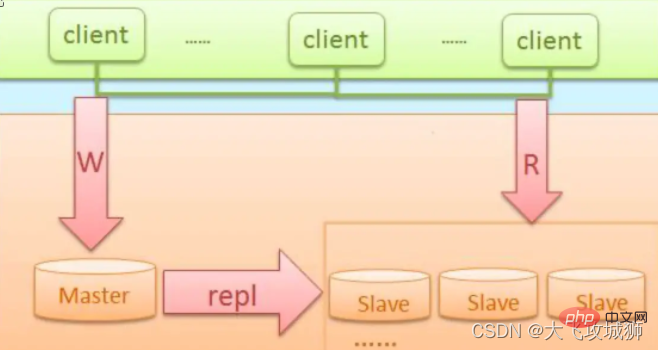
- ##High availability software can use Heartbeat, which is fully responsible for VIP, Management of data and DRBD services
- It can automatically and quickly switch after the master failure, and the slave library can still synchronize data with the new master library through VIP
- The slave library also supports read-write separation and can be used Middleware or program implementation
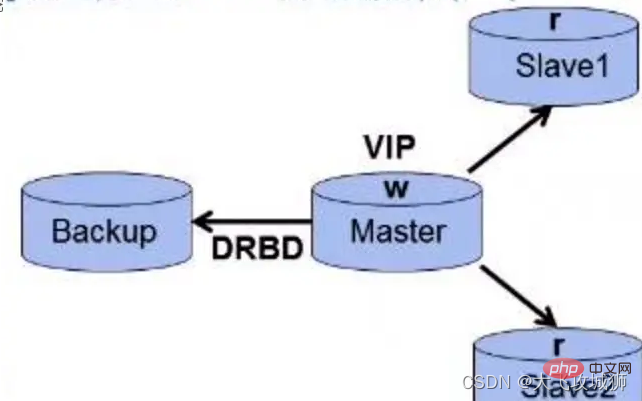
The access process of MySQL Cluster is roughly like this. Applications usually use a certain load balancing algorithm to distribute data access to different SQL nodes. The SQL nodes perform data access to the data nodes and return data results from the data nodes. The management nodes It only configures and manages SQL nodes and data nodes;
Understanding MySQL Cluster nodes
MySQL Cluster can be divided into three types of nodes according to node types, namely management nodes, SQL nodes, Data nodes, all these nodes constitute a complete MySQL cluster system. In fact, the data is stored in the storage engine of the NDB storage server, and the table structure is stored in the MySQL server. The application accesses the data through the MySQL server, and the cluster management The server manages the NDB storage server through the management tool ndb_mgmd;
[1. Management node]
The management node is mainly used to manage other nodes. The config.ini file is usually configured to configure how many copies need to be maintained in the cluster, how much memory to allocate for data and indexes on each data node, IP address, and the disk path to save data on each data node;
Management nodes usually manage Cluster configuration files and Cluster logs. Each node in the cluster retrieves configuration information from the management server and requests a way to determine where the management server is located. If a new event occurs in the node, the node transmits the information of this type of event to the management server and writes this information to the Cluster log;
Generally, at least one management node is required in the MySQL Cluster system. , It is also worth noting that because the data node and SQL node need to read the Cluster configuration information before starting, the management node is usually the first to start;
[2.SQL node]
The SQL node is simply the mysqld server. The application cannot directly access the data node and can only access the data node through the SQL node to return data. Any SQL node is connected to all storage nodes, so when any storage node fails, the SQL node can transfer the request to another storage node for execution. Generally speaking, the more SQL nodes, the better. The more SQL nodes, the smaller the load assigned to each SQL node, and the better the overall performance of the system;
[3. Data nodes]
Data nodes are used to store data in the Cluster. MySQL Cluster replicates data between data nodes. If any node fails, there will always be another data node to store the data;
Usually this Three different logical nodes can be distributed on different computers. The cluster has at least three computers. In order to ensure the normal maintenance of the cluster service, the management node is usually placed on a separate host;
Recommended learning: mysql video tutorial
The above is the detailed content of Let's analyze MySQL's high-availability architecture technology together. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1677
1677
 14
1431
52
1334
25
1279
29
1257
24
14
1431
52
1334
25
1279
29
1257
24

 Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel is a PHP framework for easy building of web applications. It provides a range of powerful features including: Installation: Install the Laravel CLI globally with Composer and create applications in the project directory. Routing: Define the relationship between the URL and the handler in routes/web.php. View: Create a view in resources/views to render the application's interface. Database Integration: Provides out-of-the-box integration with databases such as MySQL and uses migration to create and modify tables. Model and Controller: The model represents the database entity and the controller processes HTTP requests.
 MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin are powerful database management tools. 1) MySQL is used to create databases and tables, and to execute DML and SQL queries. 2) phpMyAdmin provides an intuitive interface for database management, table structure management, data operations and user permission management.
 MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
Compared with other programming languages, MySQL is mainly used to store and manage data, while other languages such as Python, Java, and C are used for logical processing and application development. MySQL is known for its high performance, scalability and cross-platform support, suitable for data management needs, while other languages have advantages in their respective fields such as data analytics, enterprise applications, and system programming.
 Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Article summary: This article provides detailed step-by-step instructions to guide readers on how to easily install the Laravel framework. Laravel is a powerful PHP framework that speeds up the development process of web applications. This tutorial covers the installation process from system requirements to configuring databases and setting up routing. By following these steps, readers can quickly and efficiently lay a solid foundation for their Laravel project.
 Explain the purpose of foreign keys in MySQL.
Apr 25, 2025 am 12:17 AM
Explain the purpose of foreign keys in MySQL.
Apr 25, 2025 am 12:17 AM
In MySQL, the function of foreign keys is to establish the relationship between tables and ensure the consistency and integrity of the data. Foreign keys maintain the effectiveness of data through reference integrity checks and cascading operations. Pay attention to performance optimization and avoid common errors when using them.
 Compare and contrast MySQL and MariaDB.
Apr 26, 2025 am 12:08 AM
Compare and contrast MySQL and MariaDB.
Apr 26, 2025 am 12:08 AM
The main difference between MySQL and MariaDB is performance, functionality and license: 1. MySQL is developed by Oracle, and MariaDB is its fork. 2. MariaDB may perform better in high load environments. 3.MariaDB provides more storage engines and functions. 4.MySQL adopts a dual license, and MariaDB is completely open source. The existing infrastructure, performance requirements, functional requirements and license costs should be taken into account when choosing.
 SQL vs. MySQL: Clarifying the Relationship Between the Two
Apr 24, 2025 am 12:02 AM
SQL vs. MySQL: Clarifying the Relationship Between the Two
Apr 24, 2025 am 12:02 AM
SQL is a standard language for managing relational databases, while MySQL is a database management system that uses SQL. SQL defines ways to interact with a database, including CRUD operations, while MySQL implements the SQL standard and provides additional features such as stored procedures and triggers.
 MySQL: The Database, phpMyAdmin: The Management Interface
Apr 29, 2025 am 12:44 AM
MySQL: The Database, phpMyAdmin: The Management Interface
Apr 29, 2025 am 12:44 AM
MySQL and phpMyAdmin can be effectively managed through the following steps: 1. Create and delete database: Just click in phpMyAdmin to complete. 2. Manage tables: You can create tables, modify structures, and add indexes. 3. Data operation: Supports inserting, updating, deleting data and executing SQL queries. 4. Import and export data: Supports SQL, CSV, XML and other formats. 5. Optimization and monitoring: Use the OPTIMIZETABLE command to optimize tables and use query analyzers and monitoring tools to solve performance problems.
