
 Database
Mysql Tutorial
Detailed explanation of count(), union() and group by statements in MySQL
Database
Mysql Tutorial
Detailed explanation of count(), union() and group by statements in MySQL
Detailed explanation of count(), union() and group by statements in MySQL

This article will take you through count(), union() and group by statements, and supplement MySQL knowledge points (the usage of different count(), union execution process, group by statement).

1. Different usages of count() in MySQL
count() is an aggregate function, for the returned result set , judge line by line, if the parameter of the count function is not NULL, the cumulative value will be added by 1, otherwise it will not be added. Finally, the cumulative value is returned. [Related recommendations: mysql video tutorial]
1. For count (primary key id), the InnoDB engine will traverse the entire table, take out the id value of each row, and return To the server layer. After the server layer gets the id, it determines that it cannot be empty, so it accumulates it by row
2. For count(1), the InnoDB engine traverses the entire table but does not take a value. The server layer puts a number 1 into each row returned. It is judged that it cannot be empty and accumulates
3 by row. For count (field), if this field is defined as not null , read this field from the record line by line, and judge that it cannot be null, and accumulate it line by line; if the field definition allows null, then when executing, it is judged that it may be null, and the value must be taken out and judged. Now, it’s not null that accumulates
4. For count(*), not all fields are taken out, but are specially optimized. No value is taken, count(*) is definitely not null, and is accumulated by row

## 2. Union execution process
In order to facilitate quantitative analysis, take the following table t1 as an examplecreate table t1(id int primary key, a int, b int, index(a));
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
END(select 1000 as f) union (select id from t1 order by id desc limit 2);

- The key=PRIMARY in the second row indicates that the second clause uses When it comes to the Extra field in the third row of index id, it means that when doing union on the result set of the subquery, a temporary table is used
3. Execute the second subquery:
- Get the first row id=1000 and try to insert it into the temporary table. But since the value 1000 already exists in the temporary table, it violates the uniqueness constraint, so the insertion fails, and then continues to execute to get the second row id=999, and the insertion into the temporary table is successful

3. Detailed explanation of group by statement
1. Group by execution process
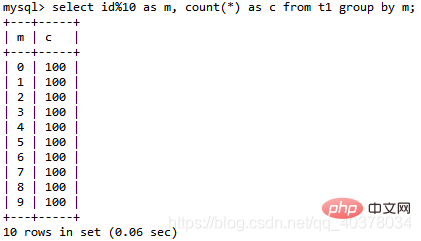
Still use the above table t1 to analyze the following SQL statement:select id%10 as m, count(*) as c from t1 group by m;
 In the Extra field, you can see three pieces of information:
In the Extra field, you can see three pieces of information:
- Using index, indicating that this statement uses a covering index, selected Index a, there is no need to return to the table Using temporary, indicating that a temporary table is used Using filesort, indicating that sorting is required
- If there is no row with primary key x in the temporary table, insert a record (x,1)If there is a row with primary key x in the table row, add 1 to the c value of the row
内存临时表排序流程图:
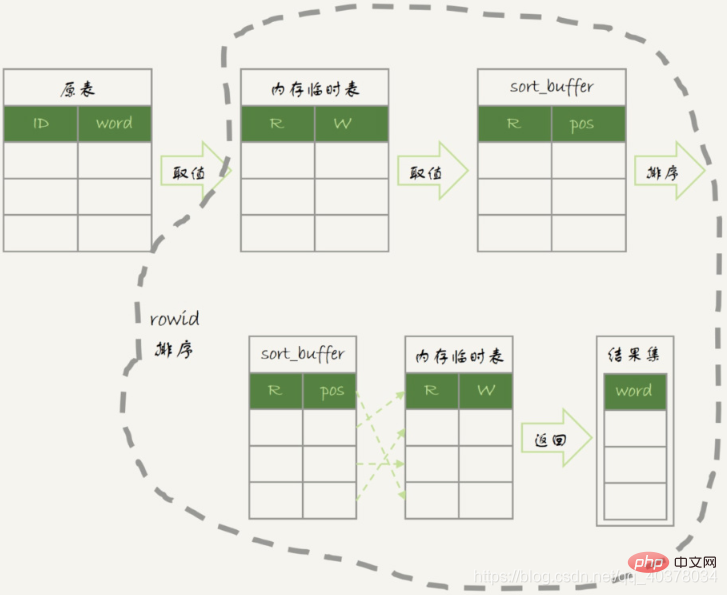
如果并不需要对结果进行排序,在SQL语句末尾增加order by null:
select id%10 as m, count(*) as c from t1 group by m order by null;
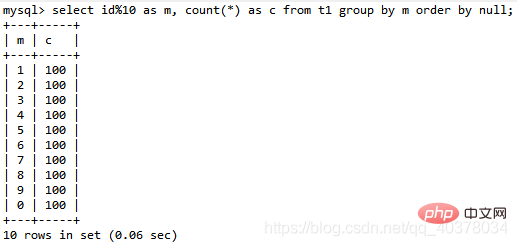
由于表t1中的id值是从1开始的,因此返回的结果集中第一行是id=1
这个例子里由于临时表只有10行,内存可以放得下,因此全程只使用了内存临时表。但是,内存临时表的大小是有限的,参数tmp_table_size就是控制整个内存大小的,默认是16M
set tmp_table_size=1024; select id%100 as m, count(*) as c from t1 group by m order by null limit 10;
把内存临时表的大小限制为最大1024字节,并把语句改成id%100,这样返回结果里有100行数据。但是,这时的内存临时表大小不够存下这100行数据,也就是说,执行过程中会发现内存临时表大小达到了上限。那么,这时候会把内存临时表转成磁盘临时表,磁盘临时表默认使用的引擎是InnoDB
2、group by优化方法——索引
group by的语义逻辑,是统计不同的值的个数。但是,由于每一行的id%100的结果是无序的,所以就需要有一个临时表来记录并统计结果。那么,如果扫描过程中可以保证出现的数据是有序的就可以了
假设,现在有一个类似下图的这么一个数据结构

如果可以确保输入的数据是有序的,那么计算group by的时候,就只需要从左到右,顺序扫描,依次累加。也就是下面这个流程:
- 当碰到第一个1的时候,已经知道累积了X个0,结果集里的第一行就是(0,X)
- 当碰到第一个2的时候,已经知道累积了Y个1,结果集里的第一行就是(1,Y)
按照这个逻辑执行的话,扫描到整个输入的数据结束,就可以拿到group by的结果,不需要临时表,也需要再额外排序
在MySQL5.7版本支持了generated column机制,用来实现列数据的关联更新。创建一个列z,在z列上创建一个索引
alter table t1 add column z int generated always as(id % 100), add index(z);
这样,索引z上的数据就是有序的了。group by语句就可以改成:
select z, count(*) as c from t1 group by z;

从这个Extra字段可以看到,这个语句的执行不再需要临时表,也不需要排序了
3、group by优化方法——直接排序
在group by语句中加入SQL_BIG_RESULT这个提示,就可以告诉优化器:这个语句涉及的数据量很大,直接用磁盘临时表。因为磁盘临时表是B+树存储,存储效率不如数组来得高。所以MySQL优化器直接用数组来存
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
1.初始化sort_buffer,确定放入一个整型字段,记为m
2.扫描表t1的索引a,依次取出里面的id值,将id%100的值存入sort_buffer中
3.扫描完成后,对sort_buffer的字段m做排序(如果sort_buffer内存不够用,就会利用磁盘临时文件辅助排序)
4.排序完成后,就得到了一个有序数组
根据有序数组,得到数组里面的不同值,以及每个值的出现次数
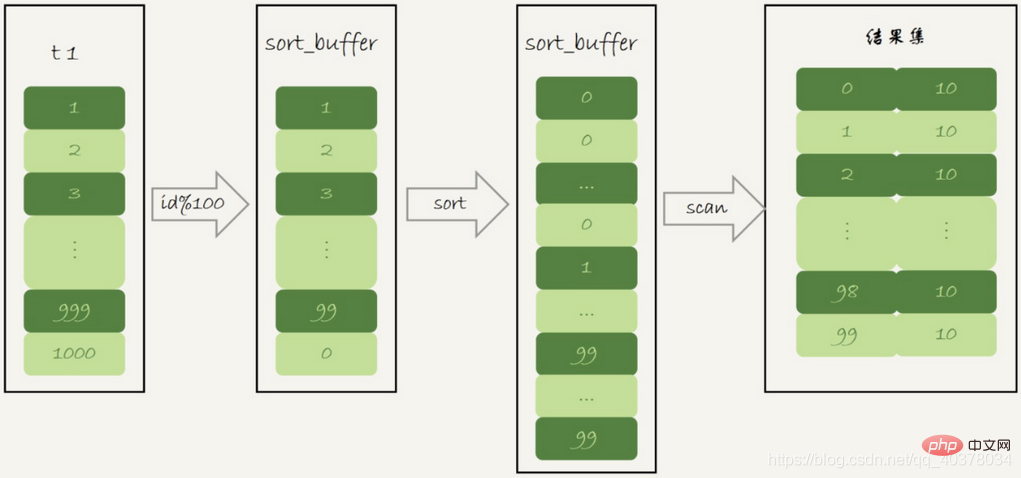
这个语句的执行没有再使用临时表,而是直接用了排序算法
,%20union()%20and%20group%20by%20statements%20in%20MySQL)
更多编程相关知识,请访问:编程入门!!
The above is the detailed content of Detailed explanation of count(), union() and group by statements in MySQL. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel is a PHP framework for easy building of web applications. It provides a range of powerful features including: Installation: Install the Laravel CLI globally with Composer and create applications in the project directory. Routing: Define the relationship between the URL and the handler in routes/web.php. View: Create a view in resources/views to render the application's interface. Database Integration: Provides out-of-the-box integration with databases such as MySQL and uses migration to create and modify tables. Model and Controller: The model represents the database entity and the controller processes HTTP requests.
 MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin are powerful database management tools. 1) MySQL is used to create databases and tables, and to execute DML and SQL queries. 2) phpMyAdmin provides an intuitive interface for database management, table structure management, data operations and user permission management.
 MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
Compared with other programming languages, MySQL is mainly used to store and manage data, while other languages such as Python, Java, and C are used for logical processing and application development. MySQL is known for its high performance, scalability and cross-platform support, suitable for data management needs, while other languages have advantages in their respective fields such as data analytics, enterprise applications, and system programming.
 Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
I encountered a tricky problem when developing a small application: the need to quickly integrate a lightweight database operation library. After trying multiple libraries, I found that they either have too much functionality or are not very compatible. Eventually, I found minii/db, a simplified version based on Yii2 that solved my problem perfectly.
 Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Article summary: This article provides detailed step-by-step instructions to guide readers on how to easily install the Laravel framework. Laravel is a powerful PHP framework that speeds up the development process of web applications. This tutorial covers the installation process from system requirements to configuring databases and setting up routing. By following these steps, readers can quickly and efficiently lay a solid foundation for their Laravel project.
 Solve MySQL mode problem: The experience of using the TheliaMySQLModesChecker module
Apr 18, 2025 am 08:42 AM
Solve MySQL mode problem: The experience of using the TheliaMySQLModesChecker module
Apr 18, 2025 am 08:42 AM
When developing an e-commerce website using Thelia, I encountered a tricky problem: MySQL mode is not set properly, causing some features to not function properly. After some exploration, I found a module called TheliaMySQLModesChecker, which is able to automatically fix the MySQL pattern required by Thelia, completely solving my troubles.
 Explain the purpose of foreign keys in MySQL.
Apr 25, 2025 am 12:17 AM
Explain the purpose of foreign keys in MySQL.
Apr 25, 2025 am 12:17 AM
In MySQL, the function of foreign keys is to establish the relationship between tables and ensure the consistency and integrity of the data. Foreign keys maintain the effectiveness of data through reference integrity checks and cascading operations. Pay attention to performance optimization and avoid common errors when using them.
 Compare and contrast MySQL and MariaDB.
Apr 26, 2025 am 12:08 AM
Compare and contrast MySQL and MariaDB.
Apr 26, 2025 am 12:08 AM
The main difference between MySQL and MariaDB is performance, functionality and license: 1. MySQL is developed by Oracle, and MariaDB is its fork. 2. MariaDB may perform better in high load environments. 3.MariaDB provides more storage engines and functions. 4.MySQL adopts a dual license, and MariaDB is completely open source. The existing infrastructure, performance requirements, functional requirements and license costs should be taken into account when choosing.
