

python crawler: crawl Baidu pictures as you like


Article Directory
- 1. Preface
- 2. Libraries that need to be imported
- 3. Implementation process
- 1. Download link analysis
- 2. Code analysis
- 3 , Complete code
- 4. Blogger's speech
(Free learning recommendation: python video tutorial)
1. Preface
I crawled a lot of static before The content of web pages includes: novels, pictures, etc. Today I will try to crawl dynamic web pages. As we all know, Baidu Pictures is a dynamic web page. Then, rush! rush! ! rush! ! !
2. Libraries that need to be imported
import requestsimport jsonimport os
3. Implementation process
1. Download link analysis
First, open Baidu and search for a content. The search here is for the male god (himself)——Peng Yuyan
Then, open the packet capture tool , select the XHR option, press Ctrl R, and then you will find that as your mouse slides, one data packet after another will appear on the right. 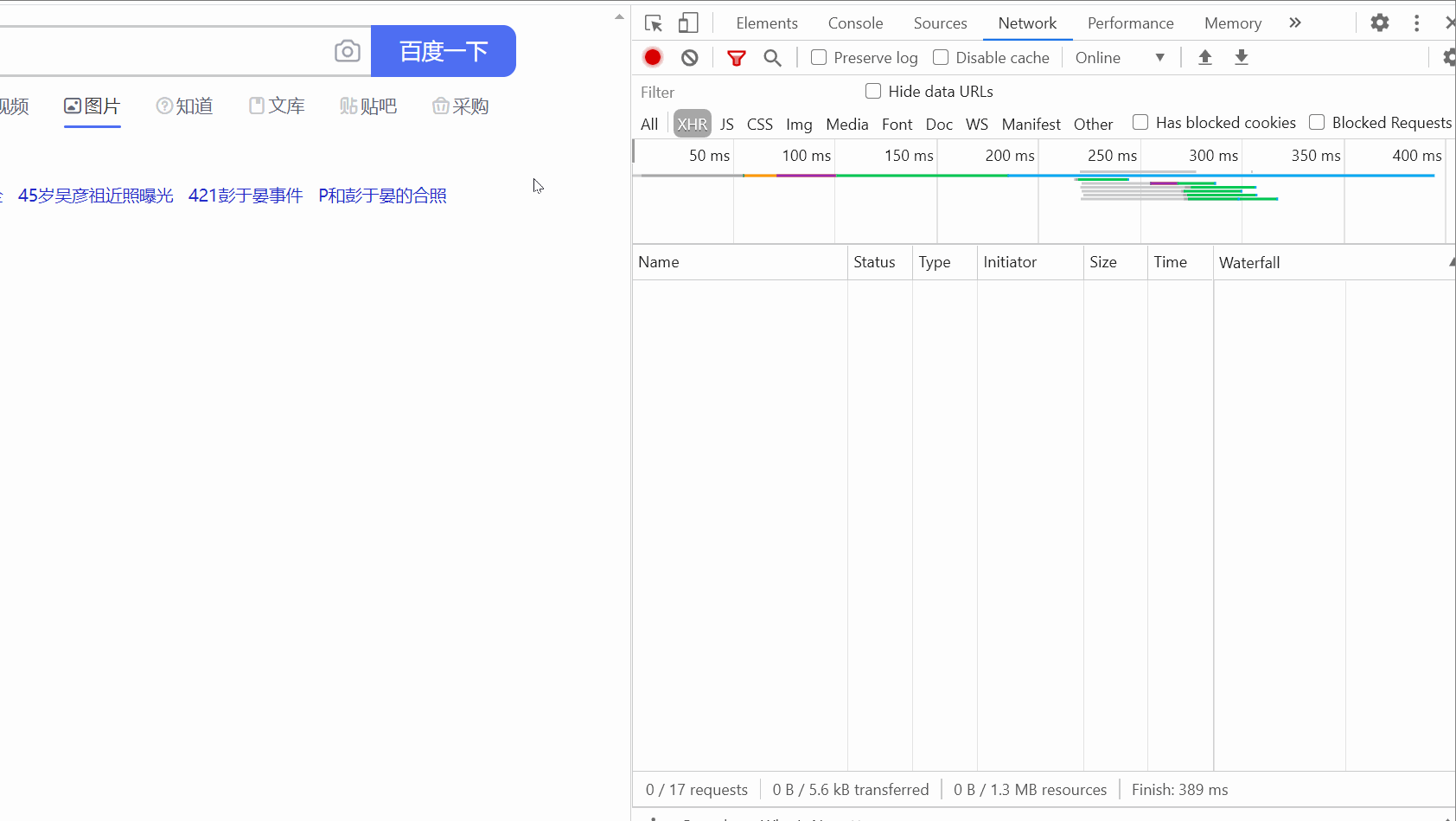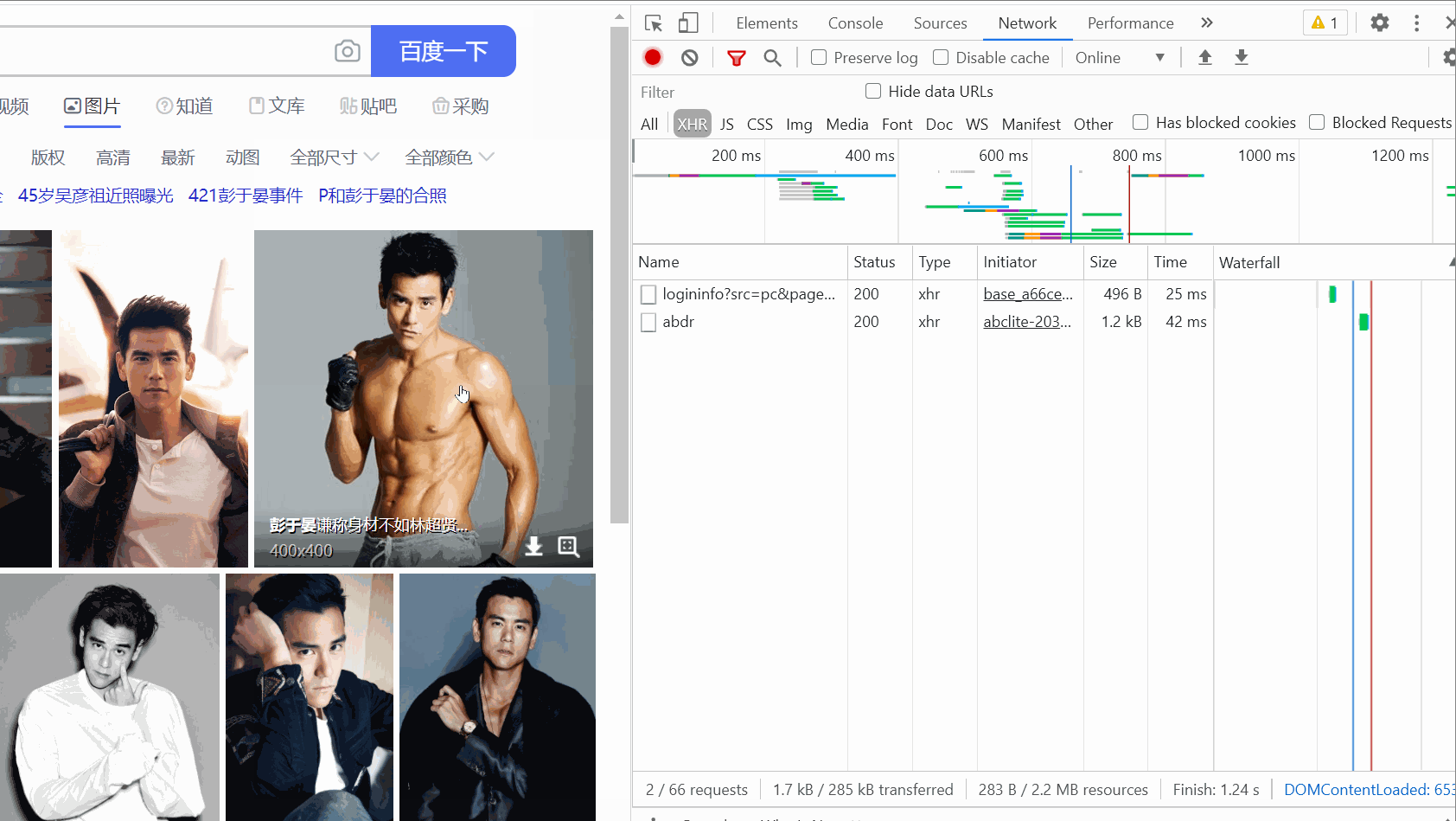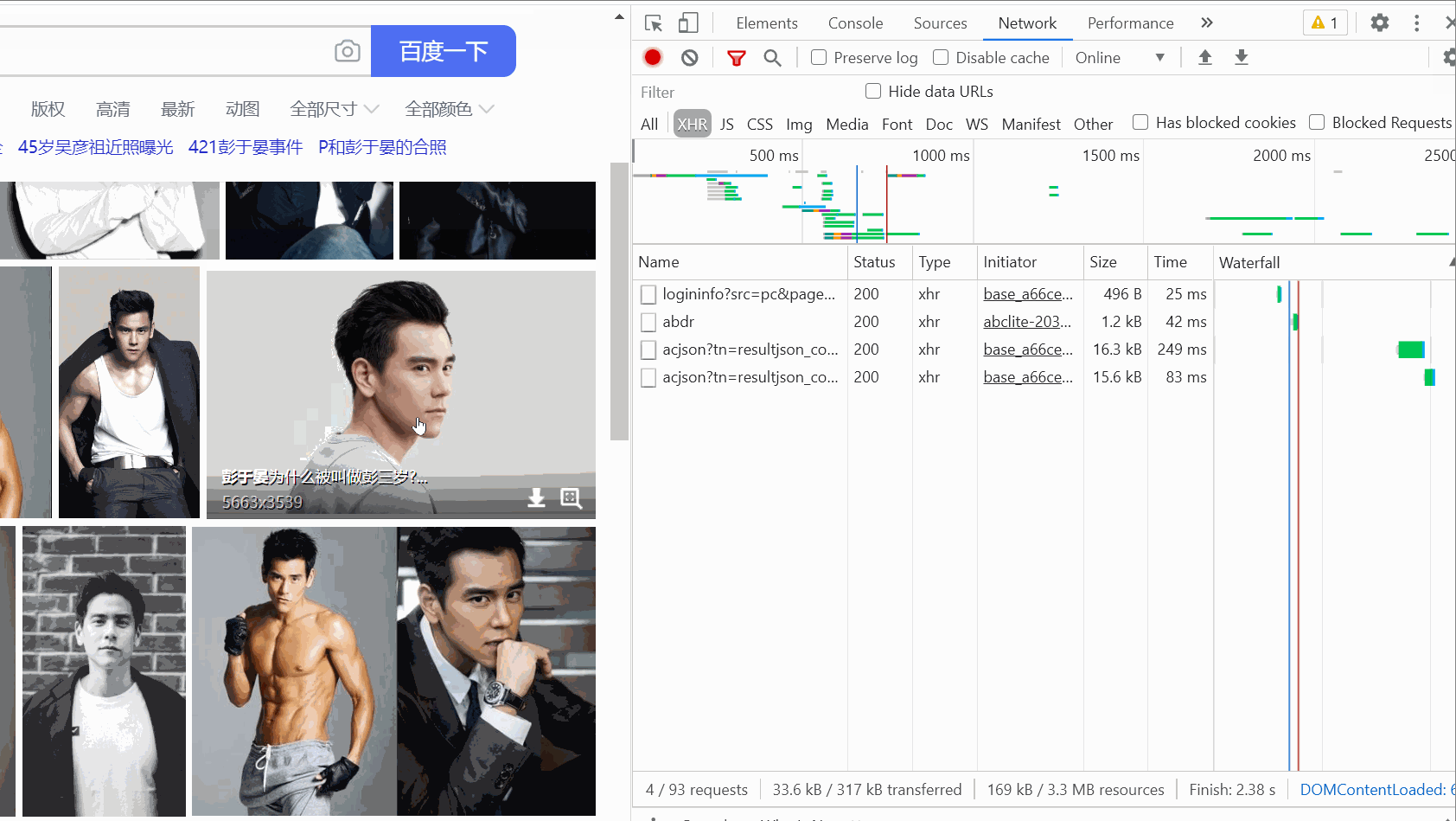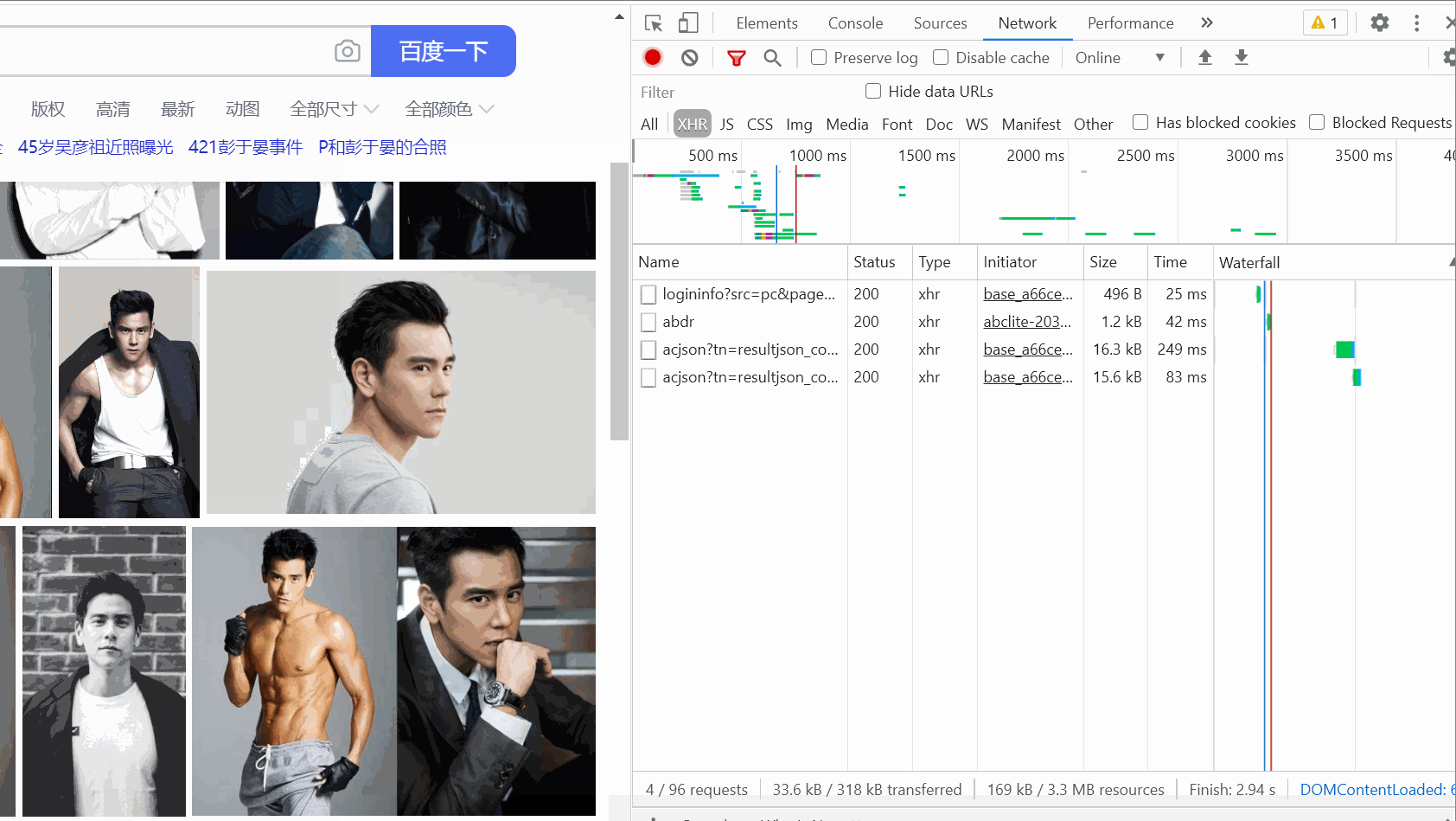
(There is not too much sliding here. At first, the GIF recorded was over 5M because of too much sliding.)
Then, select a package and view it headers, as shown in the figure: 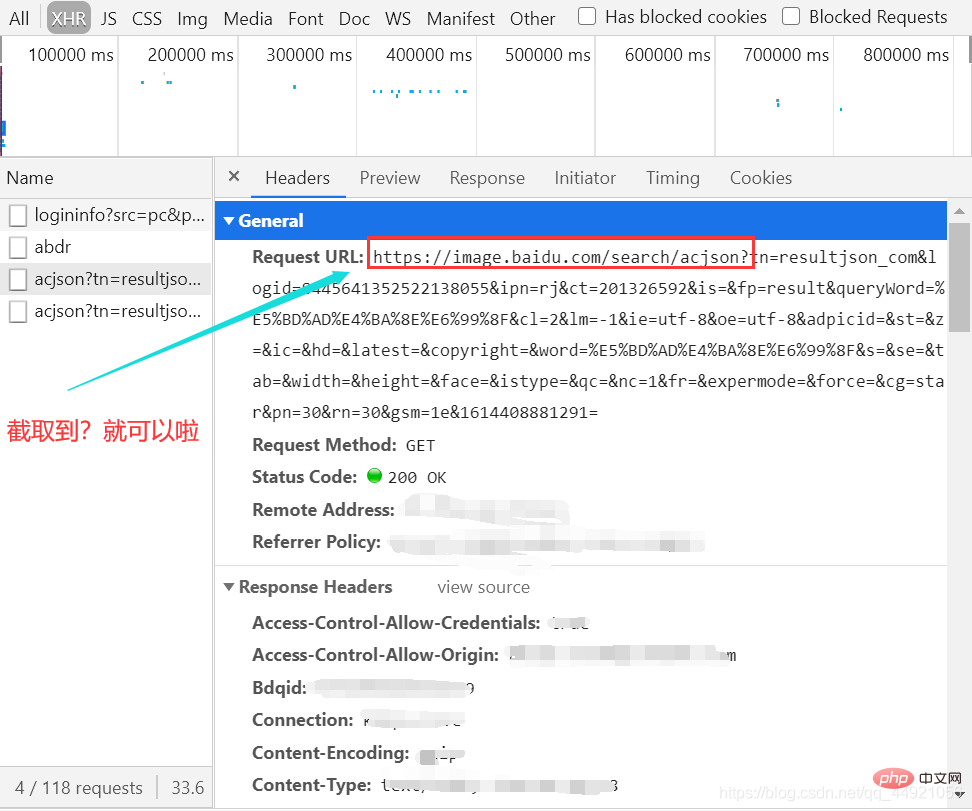
After intercepting, paste it on Notepad as a URL, which will be used later. 
There are many, many parameters here, and I don’t know which ones can be ignored. I will simply copy them all in the following article. See the following article for details.
Here, the content that can be directly observed is over. Next, with the help of code, help us open the door to another world
That’s it!
2. Code analysis
First: Group the "other parameters" mentioned above together.
If you do it yourself, it is best to copy your own "Other parameters".
After that, we can try to extract it first, and change the encoding format to 'utf-8'
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '彭于晏',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': '彭于晏',
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': '30',
'rn': '30',
'gsm': '1e',
}
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text print(response)The running results are as follows: 
It looks quite messy. It’s okay. Let’s pack it up!
Add on the basis of the above:
# 把字符串转换成json数据 data_s = json.loads(response) print(data_s)
The running results are as follows: 
Compared with the above, it is much clearer, but it is still not clear enough. Why Woolen cloth? Because its printed format is not convenient for us to view!
There are two solutions to this.
①Import the pprint library, then enter pprint.pprint(data_s), and you can print, as shown below
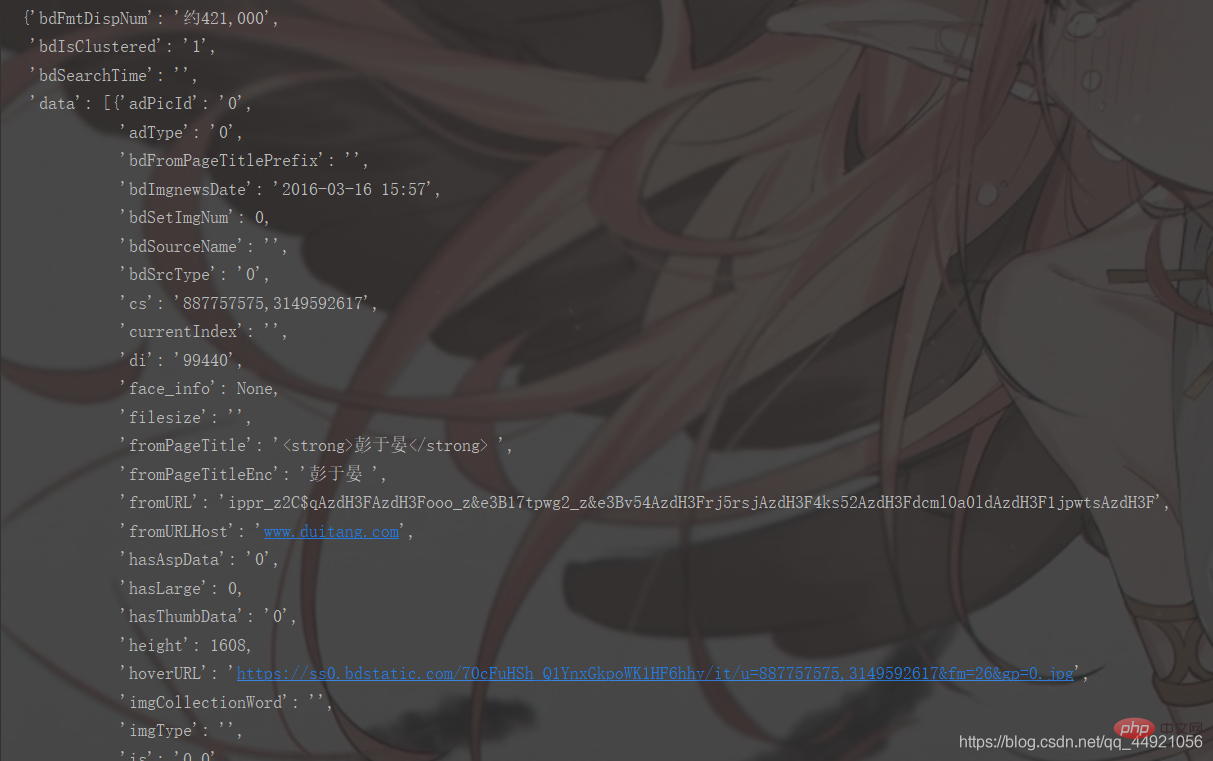
②Use the json online parser (by Baidu), the results are as follows: 
After solving the previous step, we will find that the data we want is all in dataInside!
Then extract it!
a = data_s["data"]
for i in range(len(a)-1): # -1是为了去掉上面那个空数据
data = a[i].get("thumbURL", "not exist")
print(data)The results are as follows: 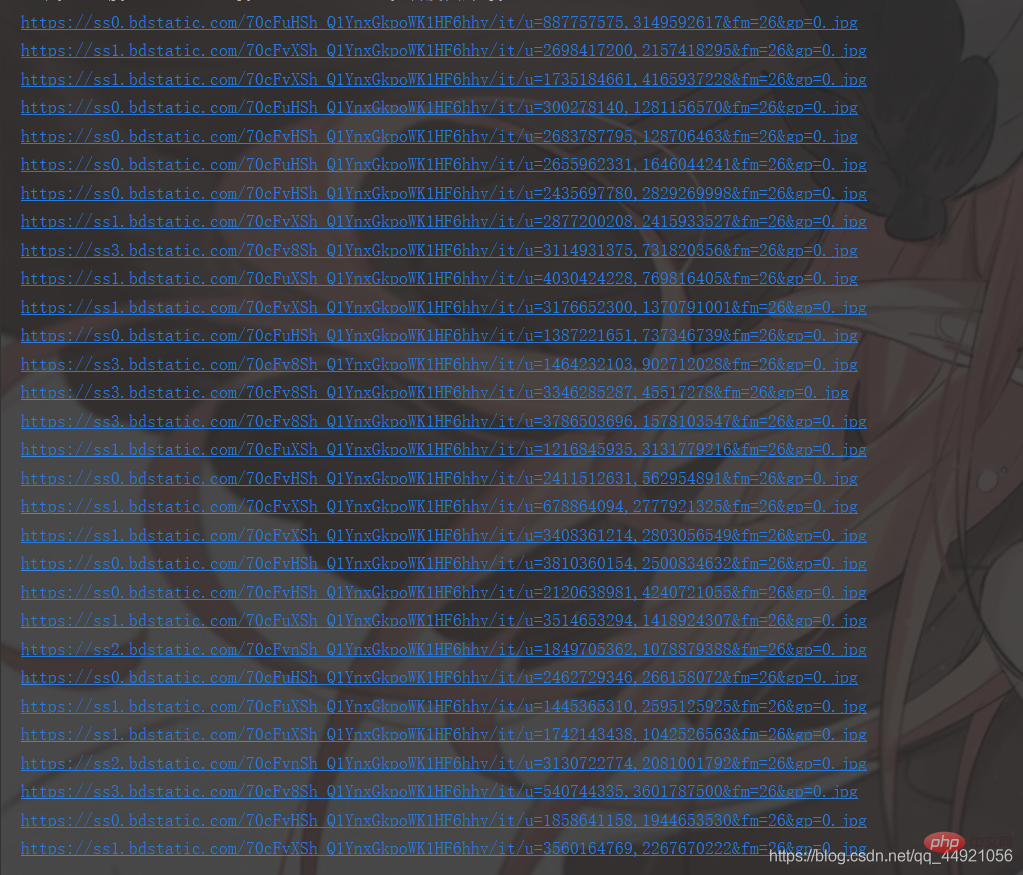
At this point, 90% of the success has been achieved. All that remains is to save and optimize the code!
3. Complete code
This part is slightly different from the above. If you look carefully, you will find it!
# -*- coding: UTF-8 -*-"""
@Author :远方的星
@Time : 2021/2/27 17:49
@CSDN :https://blog.csdn.net/qq_44921056
@腾讯云 : https://cloud.tencent.com/developer/user/8320044
"""import requestsimport jsonimport osimport pprint# 创建一个文件夹path = 'D:/百度图片'if not os.path.exists(path):
os.mkdir(path)# 导入一个请求头header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}# 用户(自己)输入信息指令keyword = input('请输入你想下载的内容:')page = input('请输入你想爬取的页数:')page = int(page) + 1n = 0pn = 1# pn代表从第几张图片开始获取,百度图片下滑时默认一次性显示30张for m in range(1, page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': ' 7517080705015306512',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'star',
'pn': pn,
'rn': '30',
'gsm': '1e',
}
# 定义一个空列表,用于存放图片的URL
image_url = list()
# 将编码形式转换为utf-8
response = requests.get(url=url, headers=header, params=param)
response.encoding = 'utf-8'
response = response.text # 把字符串转换成json数据
data_s = json.loads(response)
a = data_s["data"] # 提取data里的数据
for i in range(len(a)-1): # 去掉最后一个空数据
data = a[i].get("thumbURL", "not exist") # 防止报错key error
image_url.append(data)
for image_src in image_url:
image_data = requests.get(url=image_src, headers=header).content # 提取图片内容数据
image_name = '{}'.format(n+1) + '.jpg' # 图片名
image_path = path + '/' + image_name # 图片保存路径
with open(image_path, 'wb') as f: # 保存数据
f.write(image_data)
print(image_name, '下载成功啦!!!')
f.close()
n += 1
pn += 29The running results are as follows: 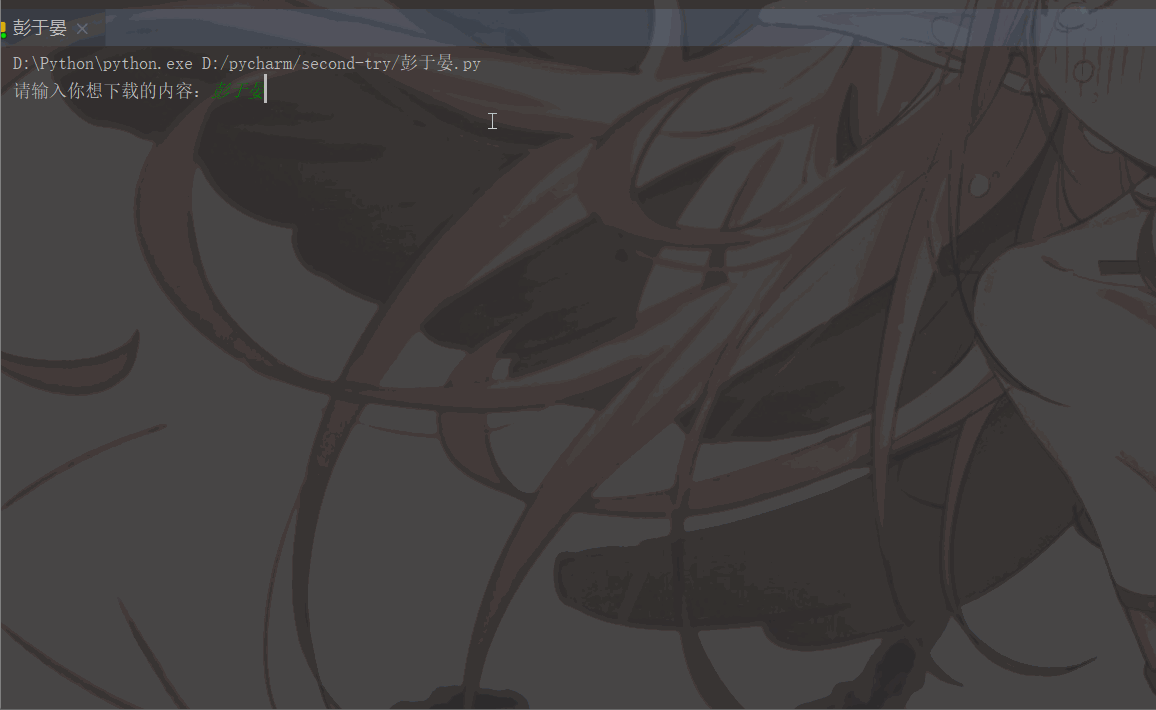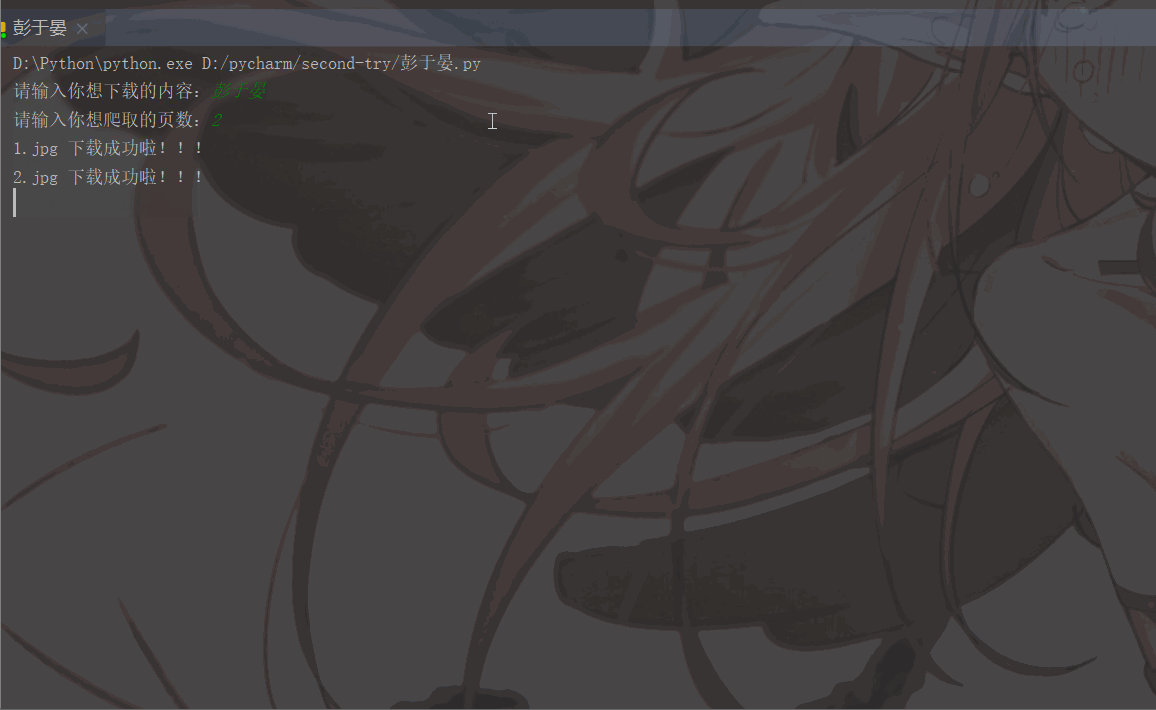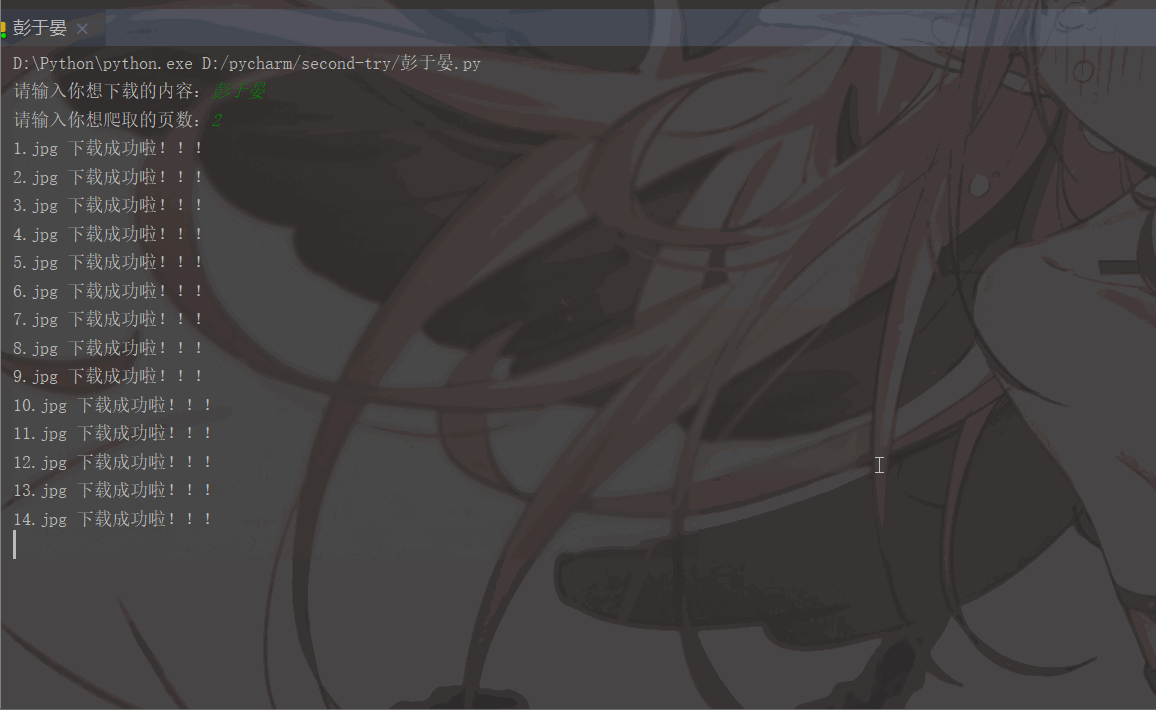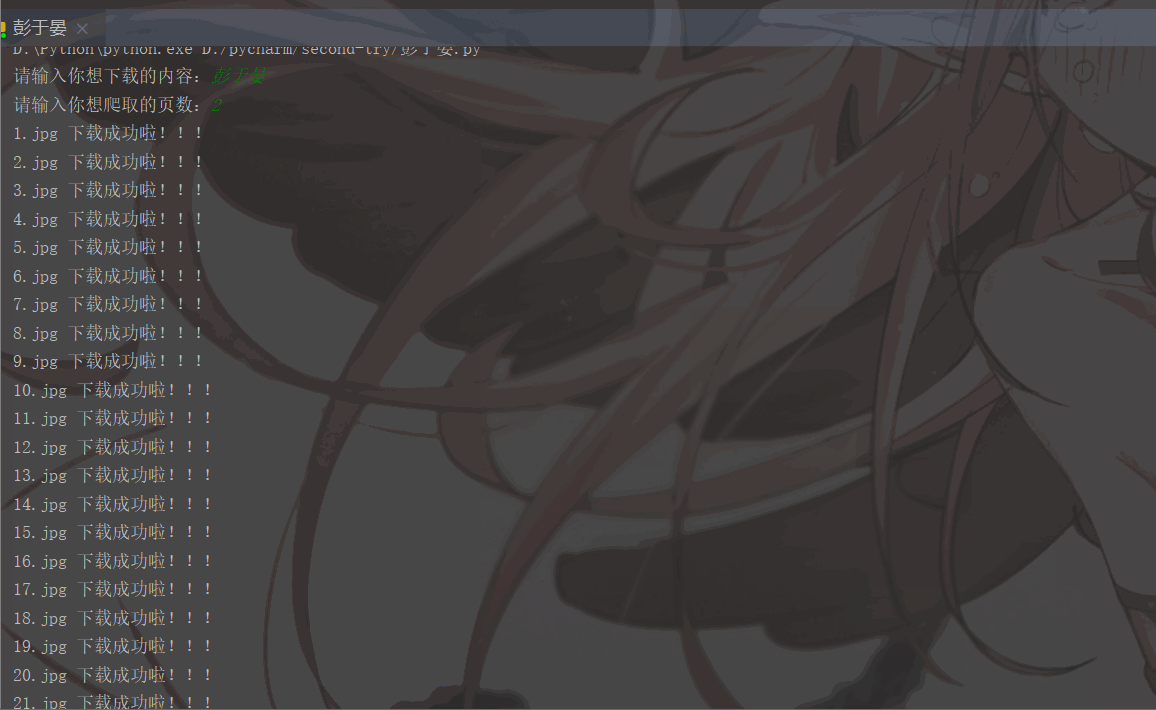

Friendly reminder:
①: One page is 30 pictures
②: The input content can be varied: such as bridge, moon, sun, Hu Ge, Zhao Liying, etc.
4. Blogger’s speech
I hope you can like, follow, collect, and support it three times in a row!
A large number of free learning recommendations, please visit python tutorial(Video)
The above is the detailed content of python crawler: crawl Baidu pictures as you like. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1245
24
14
1423
52
1317
25
1268
29
1245
24

 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 How to run sublime code python
Apr 16, 2025 am 08:48 AM
How to run sublime code python
Apr 16, 2025 am 08:48 AM
To run Python code in Sublime Text, you need to install the Python plug-in first, then create a .py file and write the code, and finally press Ctrl B to run the code, and the output will be displayed in the console.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 Golang vs. Python: Performance and Scalability
Apr 19, 2025 am 12:18 AM
Golang vs. Python: Performance and Scalability
Apr 19, 2025 am 12:18 AM
Golang is better than Python in terms of performance and scalability. 1) Golang's compilation-type characteristics and efficient concurrency model make it perform well in high concurrency scenarios. 2) Python, as an interpreted language, executes slowly, but can optimize performance through tools such as Cython.
 Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Writing code in Visual Studio Code (VSCode) is simple and easy to use. Just install VSCode, create a project, select a language, create a file, write code, save and run it. The advantages of VSCode include cross-platform, free and open source, powerful features, rich extensions, and lightweight and fast.
 How to run python with notepad
Apr 16, 2025 pm 07:33 PM
How to run python with notepad
Apr 16, 2025 pm 07:33 PM
Running Python code in Notepad requires the Python executable and NppExec plug-in to be installed. After installing Python and adding PATH to it, configure the command "python" and the parameter "{CURRENT_DIRECTORY}{FILE_NAME}" in the NppExec plug-in to run Python code in Notepad through the shortcut key "F6".
