

How to Use Apache Iceberg Tables?

Apache Iceberg: A Modern Table Format for Enhanced Data Lake Management
Apache Iceberg is a cutting-edge table format designed to address the shortcomings of traditional Hive tables, delivering superior performance, data consistency, and scalability. This article explores Iceberg's evolution, key features (ACID transactions, schema evolution, time travel), architecture, and comparisons with other table formats like Delta Lake and Parquet. We'll also examine its integration with modern data lakes and its impact on large-scale data management and analytics.
Key Learning Points
- Grasp the core features and architecture of Apache Iceberg.
- Understand how Iceberg facilitates schema and partition evolution without data rewriting.
- Explore how ACID transactions and time travel bolster data consistency.
- Compare Iceberg's capabilities against Delta Lake and Hudi.
- Identify scenarios where Iceberg optimizes data lake performance.
Table of Contents
- Introduction to Apache Iceberg
- The Evolution of Iceberg
- Understanding the Iceberg Format
- Core Features of Apache Iceberg
- Deep Dive into Iceberg's Architecture
- Iceberg vs. Other Table Formats: A Comparison
- Conclusion
- Frequently Asked Questions
Introduction to Apache Iceberg
Originating at Netflix in 2017 (the brainchild of Ryan Blue and Daniel Weeks), Apache Iceberg was created to resolve performance bottlenecks, consistency problems, and limitations inherent in the Hive table format. Open-sourced and donated to the Apache Software Foundation in 2018, it quickly gained traction, attracting contributions from industry giants like Apple, AWS, and LinkedIn.
The Evolution of Apache Iceberg
Netflix's experience highlighted a critical weakness in Hive: its reliance on directories for table tracking. This approach lacked the granularity needed for robust consistency, efficient concurrency, and the advanced features expected in modern data warehouses. Iceberg's development aimed to overcome these limitations with a focus on:
Key Design Goals
- Data Consistency: Updates across multiple partitions must be atomic and seamless, preventing users from seeing inconsistent data.
- Performance Optimization: Efficient metadata management was paramount to eliminate query planning bottlenecks and speed up query execution.
- User-Friendliness: Partitioning should be transparent to users, allowing for automatic query optimization without manual intervention.
- Schema Adaptability: Schema modifications should be handled safely, without requiring complete dataset rewrites.
- Scalability: The solution had to handle petabytes of data efficiently, mirroring Netflix's scale.
Understanding the Iceberg Format
Iceberg addresses these challenges by tracking tables as a structured list of files, not directories. It provides a standardized format defining metadata structure across multiple files and offers libraries for seamless integration with popular engines like Spark and Flink.
A Data Lake Standard
Iceberg's design prioritizes compatibility with existing storage and compute engines, promoting broad adoption without significant changes. The aim is to establish Iceberg as an industry standard, allowing users to interact with tables irrespective of the underlying format. Many data tools now offer native Iceberg support.
Core Features of Apache Iceberg
Iceberg transcends simply addressing Hive's limitations; it introduces powerful capabilities enhancing data lake and data lakehouse workloads. Key features include:
ACID Transactional Guarantees
Iceberg uses optimistic concurrency control to ensure ACID properties, guaranteeing that transactions are either fully committed or completely rolled back. This minimizes conflicts while maintaining data integrity.
Partition Evolution
Unlike traditional data lakes, Iceberg allows modifying partitioning schemes without rewriting the entire table. This ensures efficient query optimization without disrupting existing data.
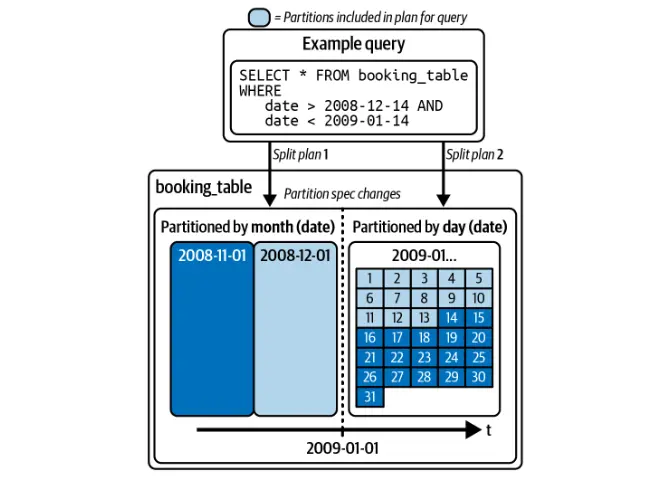
Hidden Partitioning
Iceberg automatically optimizes queries based on partitioning, eliminating the need for users to manually filter by partition columns.
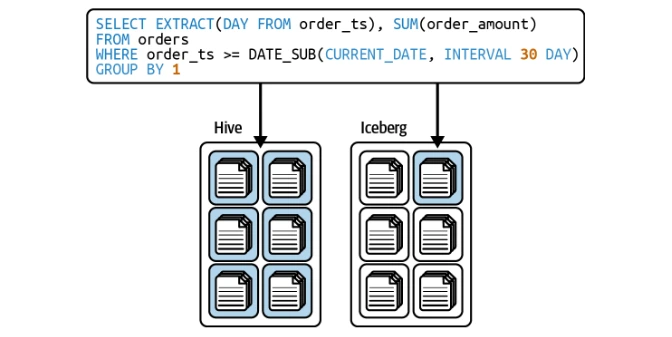
Row-Level Operations (Copy-on-Write & Merge-on-Read)
Iceberg supports both Copy-on-Write (COW) and Merge-on-Read (MOR) strategies for efficient row-level updates.
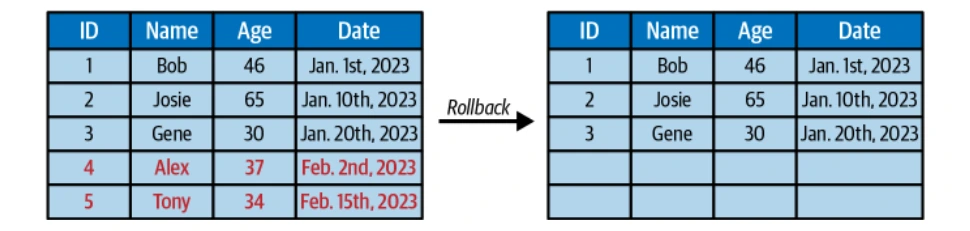
Time Travel and Version Rollback
Iceberg's immutable snapshots enable time travel queries and the ability to roll back to previous table states.

Schema Evolution
Iceberg supports schema modifications (adding, removing, or altering columns) without data rewriting, ensuring flexibility and compatibility.
Deep Dive into Iceberg's Architecture
This section explores Iceberg's architecture and how it overcomes Hive's limitations.
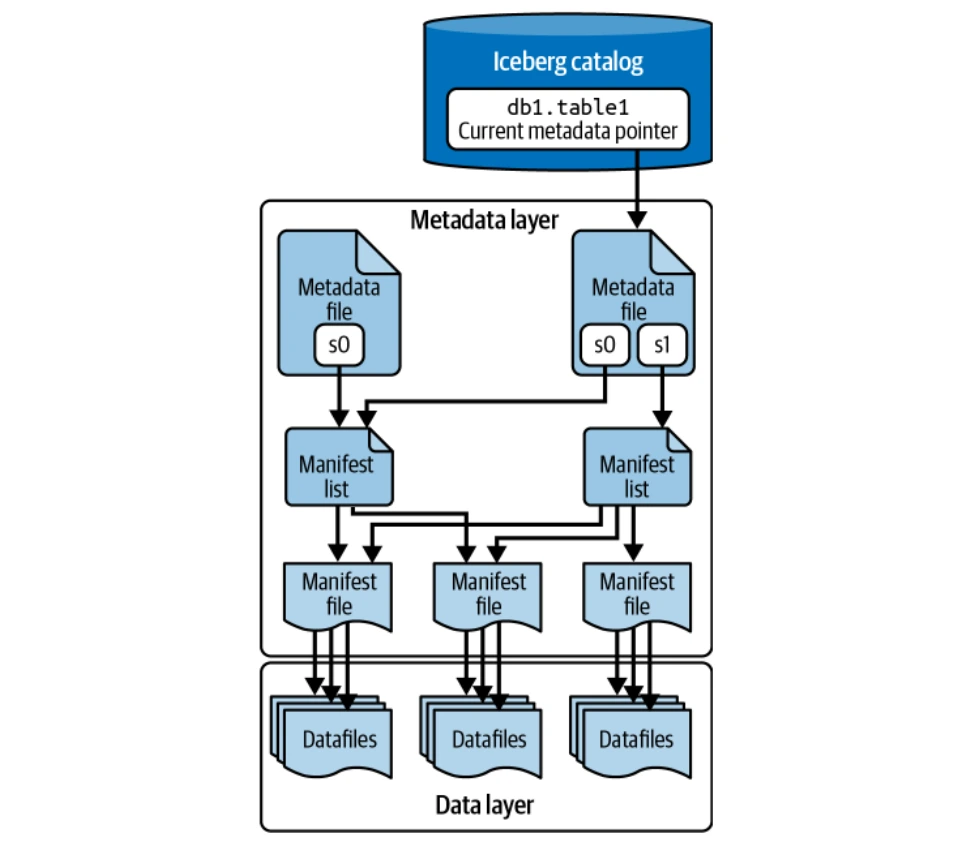
The Data Layer
The data layer stores the actual table data (data files and delete files). It's hosted on distributed filesystems (HDFS, S3, etc.) and supports multiple file formats (Parquet, ORC, Avro). Parquet is commonly preferred for its columnar storage.


The Metadata Layer
This layer manages all metadata files in a tree structure, tracking data files and operations. Key components include manifest files, manifest lists, and metadata files. Puffin files store advanced statistics and indexes for query optimization.
The Catalog
The catalog acts as a central registry, providing the location of the current metadata file for each table, ensuring consistent access for all readers and writers. Various backends can serve as Iceberg catalogs (Hadoop Catalog, Hive Metastore, Nessie Catalog, AWS Glue Catalog).
Iceberg vs. Other Table Formats: A Comparison
Iceberg, Parquet, ORC, and Delta Lake are frequently used in large-scale data processing. Iceberg distinguishes itself as a table format offering transactional guarantees and metadata optimizations, unlike Parquet and ORC which are file formats. Compared to Delta Lake, Iceberg excels in schema and partition evolution.
Conclusion
Apache Iceberg offers a robust, scalable, and user-friendly approach to data lake management. Its features make it a compelling solution for organizations handling large-scale data.
Frequently Asked Questions
Q1. What is Apache Iceberg? A. A modern, open-source table format enhancing data lake performance, consistency, and scalability.
Q2. Why is Apache Iceberg needed? A. To overcome Hive's limitations in metadata handling and transactional capabilities.
Q3. How does Iceberg handle schema evolution? A. It supports schema changes without requiring full table rewrites.
Q4. What is partition evolution in Iceberg? A. Modifying partitioning schemes without rewriting historical data.
Q5. How does Iceberg support ACID transactions? A. Through optimistic concurrency control, ensuring atomic updates.
The above is the detailed content of How to Use Apache Iceberg Tables?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1652
1652
 14
1413
52
1304
25
1251
29
1224
24
14
1413
52
1304
25
1251
29
1224
24

 Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Getting Started With Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: A Leap Forward in Multimodal and Mobile AI Meta recently unveiled Llama 3.2, a significant advancement in AI featuring powerful vision capabilities and lightweight text models optimized for mobile devices. Building on the success o
 10 Generative AI Coding Extensions in VS Code You Must Explore
Apr 13, 2025 am 01:14 AM
10 Generative AI Coding Extensions in VS Code You Must Explore
Apr 13, 2025 am 01:14 AM
Hey there, Coding ninja! What coding-related tasks do you have planned for the day? Before you dive further into this blog, I want you to think about all your coding-related woes—better list those down. Done? – Let’
 AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta's Llama 3.2, Google's Gemini 1.5, and More
Apr 11, 2025 pm 12:01 PM
This week's AI landscape: A whirlwind of advancements, ethical considerations, and regulatory debates. Major players like OpenAI, Google, Meta, and Microsoft have unleashed a torrent of updates, from groundbreaking new models to crucial shifts in le
 Selling AI Strategy To Employees: Shopify CEO's Manifesto
Apr 10, 2025 am 11:19 AM
Selling AI Strategy To Employees: Shopify CEO's Manifesto
Apr 10, 2025 am 11:19 AM
Shopify CEO Tobi Lütke's recent memo boldly declares AI proficiency a fundamental expectation for every employee, marking a significant cultural shift within the company. This isn't a fleeting trend; it's a new operational paradigm integrated into p
 A Comprehensive Guide to Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
A Comprehensive Guide to Vision Language Models (VLMs)
Apr 12, 2025 am 11:58 AM
Introduction Imagine walking through an art gallery, surrounded by vivid paintings and sculptures. Now, what if you could ask each piece a question and get a meaningful answer? You might ask, “What story are you telling?
 GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?
Apr 13, 2025 am 10:18 AM
GPT-4o vs OpenAI o1: Is the New OpenAI Model Worth the Hype?
Apr 13, 2025 am 10:18 AM
Introduction OpenAI has released its new model based on the much-anticipated “strawberry” architecture. This innovative model, known as o1, enhances reasoning capabilities, allowing it to think through problems mor
 Reading The AI Index 2025: Is AI Your Friend, Foe, Or Co-Pilot?
Apr 11, 2025 pm 12:13 PM
Reading The AI Index 2025: Is AI Your Friend, Foe, Or Co-Pilot?
Apr 11, 2025 pm 12:13 PM
The 2025 Artificial Intelligence Index Report released by the Stanford University Institute for Human-Oriented Artificial Intelligence provides a good overview of the ongoing artificial intelligence revolution. Let’s interpret it in four simple concepts: cognition (understand what is happening), appreciation (seeing benefits), acceptance (face challenges), and responsibility (find our responsibilities). Cognition: Artificial intelligence is everywhere and is developing rapidly We need to be keenly aware of how quickly artificial intelligence is developing and spreading. Artificial intelligence systems are constantly improving, achieving excellent results in math and complex thinking tests, and just a year ago they failed miserably in these tests. Imagine AI solving complex coding problems or graduate-level scientific problems – since 2023
 How to Add a Column in SQL? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
How to Add a Column in SQL? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
SQL's ALTER TABLE Statement: Dynamically Adding Columns to Your Database In data management, SQL's adaptability is crucial. Need to adjust your database structure on the fly? The ALTER TABLE statement is your solution. This guide details adding colu
