
 Technology peripherals
AI
Google's 'sincere work', open source 9B and 27B versions of Gemma2, focusing on efficiency and economy!
Technology peripherals
AI
Google's 'sincere work', open source 9B and 27B versions of Gemma2, focusing on efficiency and economy!
Google's 'sincere work', open source 9B and 27B versions of Gemma2, focusing on efficiency and economy!

Gemma 2 with twice the performance, how to play Llama 3 with the same level?


Excellent performance: The Gemma 2 27B model offers the best performance in its volume category, even competing with models more than twice its size Model competition. The 9B Gemma 2 model also performed well in its size category and outperformed the Llama 3 8B and other comparable open models. High efficiency, low cost: The 27B Gemma 2 model is designed to efficiently run inference at full precision on a single Google Cloud TPU host, NVIDIA A100 80GB Tensor Core GPU, or NVIDIA H100 Tensor Core GPU, while maintaining high performance Dramatically reduce costs. This makes AI deployment more convenient and affordable. Ultra-fast inference: Gemma 2 is optimized to run at blazing speeds on a variety of hardware, whether it’s a powerful gaming laptop, a high-end desktop, or a cloud-based setup. Users can try running Gemma 2 at full precision on Google AI Studio, or use a quantized version of Gemma.cpp on the CPU to unlock local performance, or try it on a home computer using NVIDIA RTX or GeForce RTX via Hugging Face Transformers.

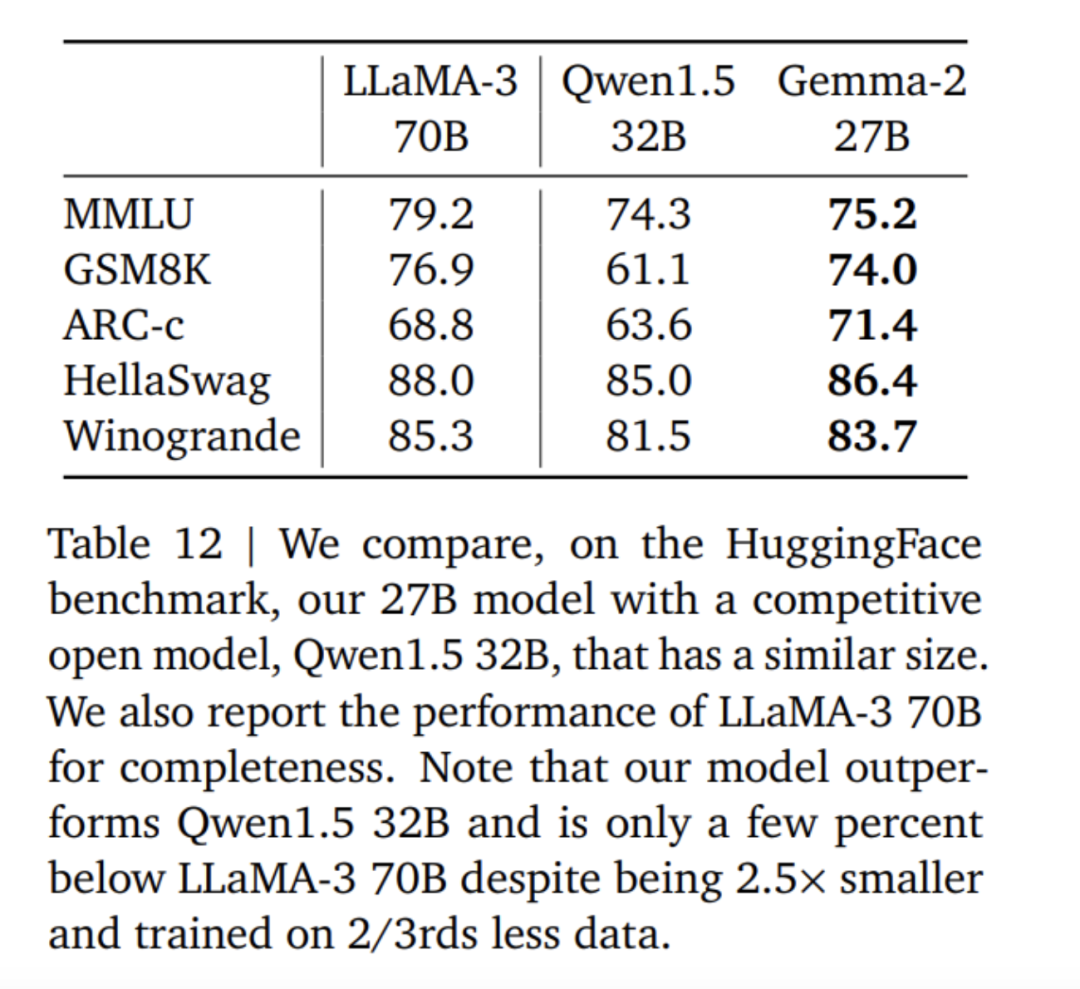
The above is the score data comparison between Gemma2, Llama3 and Grok-1.
In fact, judging from various score data, the advantages of the open source 9B large model are not particularly obvious. The large domestic model GLM-4-9B, which was open sourced by Zhipu AI nearly a month ago, has even more advantages.

Open and accessible: Like the original Gemma model, Gemma 2 allows developers and researchers to share and commercialize innovations. Broad framework compatibility: Gemma 2 is compatible with major AI frameworks such as Hugging Face Transformers, as well as JAX, PyTorch and TensorFlow natively supported through Keras 3.0, vLLM, Gemma.cpp, Llama.cpp and Ollama, making it Easily integrates with user-preferred tools and workflows. In addition, Gemma has been optimized with NVIDIA TensorRT-LLM and can run on NVIDIA accelerated infrastructure or as an NVIDIA NIM inference microservice. It will also be optimized for NVIDIA's NeMo in the future and can be fine-tuned using Keras and Hugging Face. In addition, Google is actively upgrading fine-tuning capabilities. Easy Deployment: Starting next month, Google Cloud customers will be able to easily deploy and manage Gemma 2 on Vertex AI.
In the latest blog, Google announced that it has opened Gemini 1.5 Pro’s 2 million token context window access to all developers. However, as the context window increases, the input cost may also increase. In order to help developers reduce the cost of multiple prompt tasks using the same token, Google has thoughtfully launched the context caching function in the Gemini API for Gemini 1.5 Pro and 1.5 Flash. To solve the problem that large language models need to generate and execute code to improve accuracy when processing mathematics or data reasoning, Google has enabled code execution in Gemini 1.5 Pro and 1.5 Flash. When turned on, the model can dynamically generate and run Python code and learn iteratively from the results until the desired final output is achieved. The execution sandbox does not connect to the Internet and comes standard with some numerical libraries. Developers only need to be billed based on the model's output token. This is the first time Google has introduced code execution as a step in model functionality, available today through the Gemini API and Advanced Settings in Google AI Studio. Google wants to make AI accessible to all developers, whether integrating Gemini models through API keys or using the open model Gemma 2. To help developers get their hands on the Gemma 2 model, the Google team will make it available for experimentation in Google AI Studio.

Paper address: https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf Blog address: https://blog.google/ technology/developers/google-gemma-2/

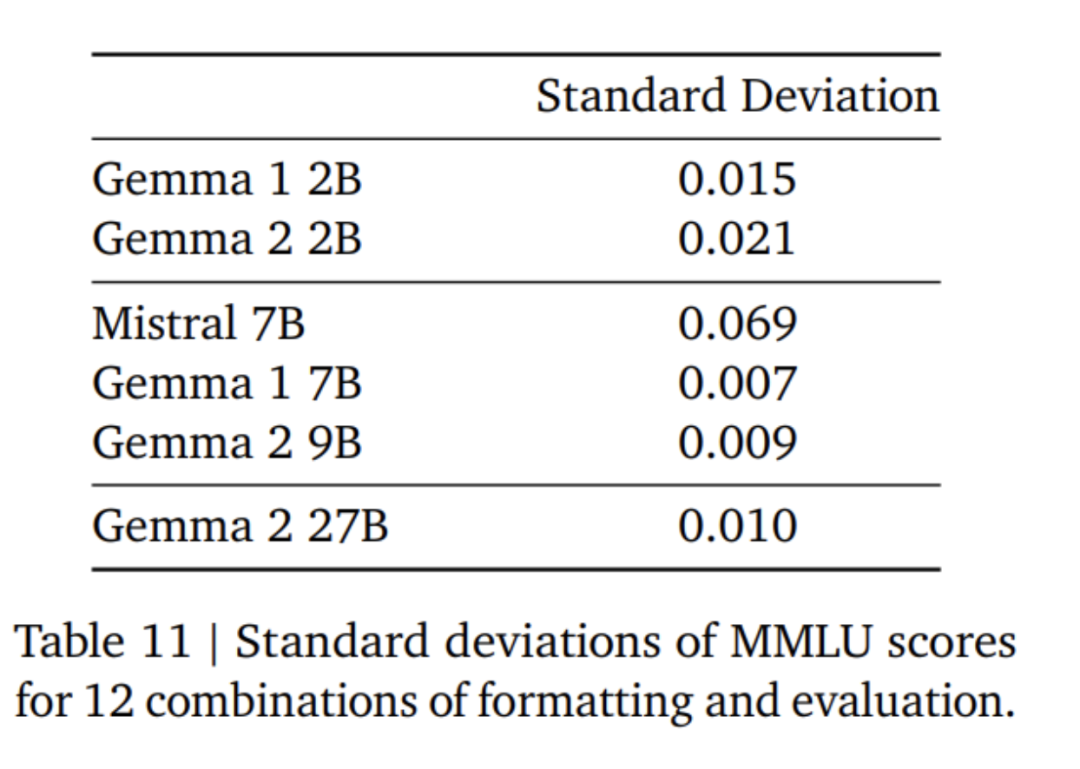
Local sliding window and global attention. The research team alternated using local sliding window attention and global attention in every other layer. The sliding window size of the local attention layer is set to 4096 tokens, while the span of the global attention layer is set to 8192 tokens. Logit soft cap. According to the method of Gemini 1.5, the research team limits logit at each attention layer and the final layer so that the value of logit remains between −soft_cap and +soft_cap. For the 9B and 27B models, the research team set the logarithmic cap of attention to 50.0 and the final logarithmic cap to 30.0. As of the time of publication, attention logit soft capping is incompatible with common FlashAttention implementations, so they have removed this feature from libraries that use FlashAttention. The research team conducted ablation experiments on model generation with and without attention logit soft capping, and found that the generation quality was almost unaffected in most pre-training and post-evaluation. All evaluations in this paper use the full model architecture including attention logit soft capping. However, some downstream performance may still be slightly affected by this removal. Use RMSNorm for post-norm and pre-norm. In order to stabilize training, the research team used RMSNorm to normalize the input and output of each transformation sub-layer, attention layer and feed-forward layer. Query attention in groups. Both 27B and 9B models use GQA, num_groups = 2, and ablation-based experiments show improved inference speed while maintaining downstream performance.

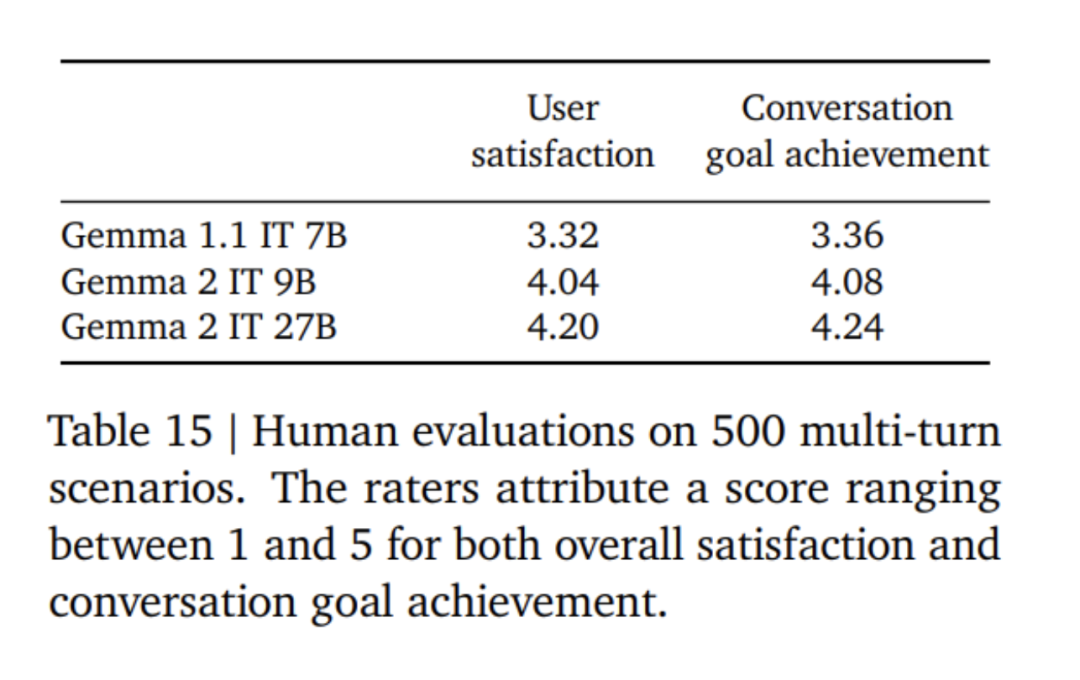
First, apply supervised fine-tuning (SFT) on a mixture of text-only, English-only synthesis, and artificially generated prompt-response pairs. Then, reinforcement learning based on the reward model (RLHF) is applied on these models. The reward model is trained on token-based pure English preference data, and the strategy uses the same prompt as the SFT stage. Finally, improve the overall performance by averaging the models obtained at each stage. The final data mixing and post-training methods, including tuned hyperparameters, are chosen based on minimizing model hazards related to safety and hallucinations while increasing model usefulness.





The above is the detailed content of Google's 'sincere work', open source 9B and 27B versions of Gemma2, focusing on efficiency and economy!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1321
25
1269
29
1249
24
14
1423
52
1321
25
1269
29
1249
24

 Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
This article recommends the top ten cryptocurrency trading platforms worth paying attention to, including Binance, OKX, Gate.io, BitFlyer, KuCoin, Bybit, Coinbase Pro, Kraken, BYDFi and XBIT decentralized exchanges. These platforms have their own advantages in terms of transaction currency quantity, transaction type, security, compliance, and special features. For example, Binance is known for its largest transaction volume and abundant functions in the world, while BitFlyer attracts Asian users with its Japanese Financial Hall license and high security. Choosing a suitable platform requires comprehensive consideration based on your own trading experience, risk tolerance and investment preferences. Hope this article helps you find the best suit for yourself
 Tutorial on how to register, use and cancel Ouyi okex account
Mar 31, 2025 pm 04:21 PM
Tutorial on how to register, use and cancel Ouyi okex account
Mar 31, 2025 pm 04:21 PM
This article introduces in detail the registration, use and cancellation procedures of Ouyi OKEx account. To register, you need to download the APP, enter your mobile phone number or email address to register, and complete real-name authentication. The usage covers the operation steps such as login, recharge and withdrawal, transaction and security settings. To cancel an account, you need to contact Ouyi OKEx customer service, provide necessary information and wait for processing, and finally obtain the account cancellation confirmation. Through this article, users can easily master the complete life cycle management of Ouyi OKEx account and conduct digital asset transactions safely and conveniently.
 Detailed tutorial on how to register for binance (2025 beginner's guide)
Mar 18, 2025 pm 01:57 PM
Detailed tutorial on how to register for binance (2025 beginner's guide)
Mar 18, 2025 pm 01:57 PM
This article provides a complete guide to Binance registration and security settings, covering pre-registration preparations (including equipment, email, mobile phone number and identity document preparation), and introduces two registration methods on the official website and APP, as well as different levels of identity verification (KYC) processes. In addition, the article also focuses on key security steps such as setting up a fund password, enabling two-factor verification (2FA, including Google Authenticator and SMS Verification), and setting up anti-phishing codes, helping users to register and use the Binance Binance platform for cryptocurrency transactions safely and conveniently. Please be sure to understand relevant laws and regulations and market risks before trading and invest with caution.
 How to optimize jieba word segmentation to improve the keyword extraction effect of scenic spot comments?
Apr 01, 2025 pm 06:24 PM
How to optimize jieba word segmentation to improve the keyword extraction effect of scenic spot comments?
Apr 01, 2025 pm 06:24 PM
How to optimize jieba word segmentation to improve keyword extraction of scenic spot comments? When using jieba word segmentation to process scenic spot comment data, if the word segmentation results are ignored...
 Tutorial on using gate.io mobile app
Mar 26, 2025 pm 05:15 PM
Tutorial on using gate.io mobile app
Mar 26, 2025 pm 05:15 PM
Tutorial on using gate.io mobile app: 1. For Android users, visit the official Gate.io website and download the Android installation package, you may need to allow the installation of applications from unknown sources in your mobile phone settings; 2. For iOS users, search "Gate.io" in the App Store to download.
 The latest updates to the oldest virtual currency rankings
Apr 22, 2025 am 07:18 AM
The latest updates to the oldest virtual currency rankings
Apr 22, 2025 am 07:18 AM
The ranking of virtual currencies’ “oldest” is as follows: 1. Bitcoin (BTC), issued on January 3, 2009, is the first decentralized digital currency. 2. Litecoin (LTC), released on October 7, 2011, is known as the "lightweight version of Bitcoin". 3. Ripple (XRP), issued in 2011, is designed for cross-border payments. 4. Dogecoin (DOGE), issued on December 6, 2013, is a "meme coin" based on the Litecoin code. 5. Ethereum (ETH), released on July 30, 2015, is the first platform to support smart contracts. 6. Tether (USDT), issued in 2014, is the first stablecoin to be anchored to the US dollar 1:1. 7. ADA,
 Top 10 recommended for safe and reliable virtual currency purchase apps
Mar 18, 2025 pm 12:12 PM
Top 10 recommended for safe and reliable virtual currency purchase apps
Mar 18, 2025 pm 12:12 PM
Top 10 recommended global virtual currency trading platforms in 2025, helping you to play the digital currency market! This article will deeply analyze the core advantages and special features of ten top platforms including Binance, OKX, Gate.io, BitFlyer, KuCoin, Bybit, Coinbase Pro, Kraken, BYDFi and XBIT decentralized exchanges. Whether you are pursuing high liquidity and rich trading types, or focusing on safety, compliance and innovative functions, you can find a platform that suits you here. We will provide a comprehensive comparison of transaction types, security, special functions, etc. to help you choose the most suitable virtual currency trading platform and seize the opportunities of digital currency investment in 2025
 Okex trading platform official website login portal
Mar 18, 2025 pm 12:42 PM
Okex trading platform official website login portal
Mar 18, 2025 pm 12:42 PM
This article introduces in detail the complete steps of logging in to the OKEx web version of Ouyi in detail, including preparation work (to ensure stable network connection and browser update), accessing the official website (to pay attention to the accuracy of the URL and avoid phishing website), finding the login entrance (click the "Login" button in the upper right corner of the homepage of the official website), entering the login information (email/mobile phone number and password, supporting verification code login), completing security verification (sliding verification, Google verification or SMS verification), and finally you can conduct digital asset trading after successfully logging in. A safe and convenient login process to ensure the safety of user assets.
