
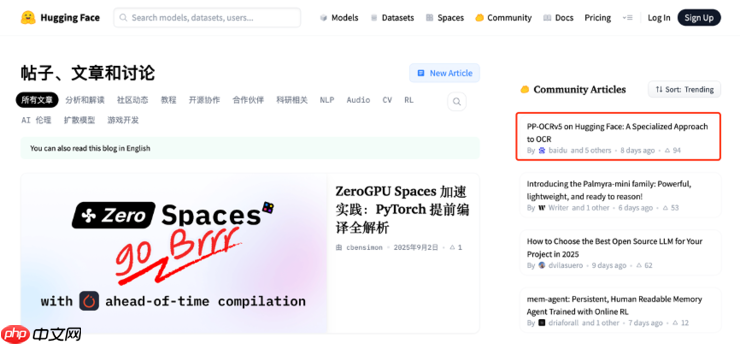
近日,百度通过其海外官方账号发布了最新的轻量级文字识别模型pp-ocrv5。该模型仅含0.07b参数,以千分之一的参数规模实现了与拥有700亿参数的大模型相媲美的ocr精度表现。在多项ocr任务测试中,pp-ocrv5的表现优于gpt-4o、qwen2.5-vl-72b等通用视觉大模型。目前,飞桨团队发布的相关技术博客已连续七天位居hugging face博客热度榜榜首,引发开发者社区广泛关注。
☞☞☞☞点击夸克AI手把手教你,操作像呼吸一样简单!☜☜☜☜☜
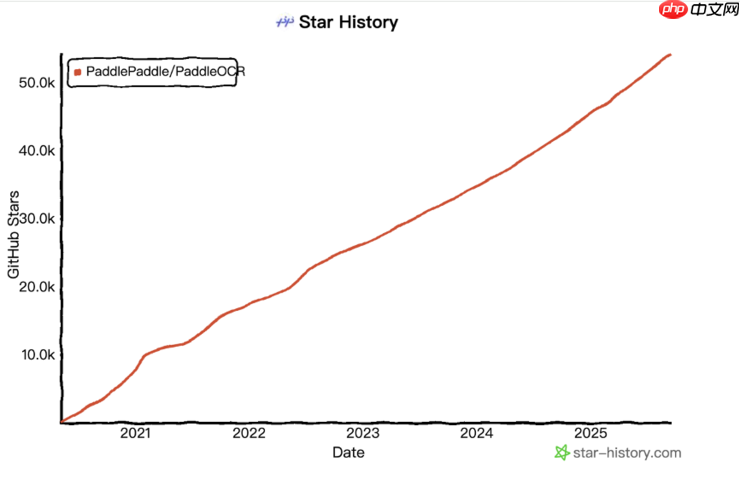
据悉,2025年5月,飞桨团队正式推出PaddleOCR 3.0版本,构建了三大核心能力:文字识别方案PP-OCRv5、通用文档解析方案PP-StructureV3,以及原生兼容文心大模型4.5的智能文档理解工具PP-ChatOCRv4。自2020年开源以来,PaddleOCR累计下载量已突破900万次,被超过5,900个开源项目直接或间接引用,成为GitHub上唯一一个Star数超过5万的中国OCR开源项目。
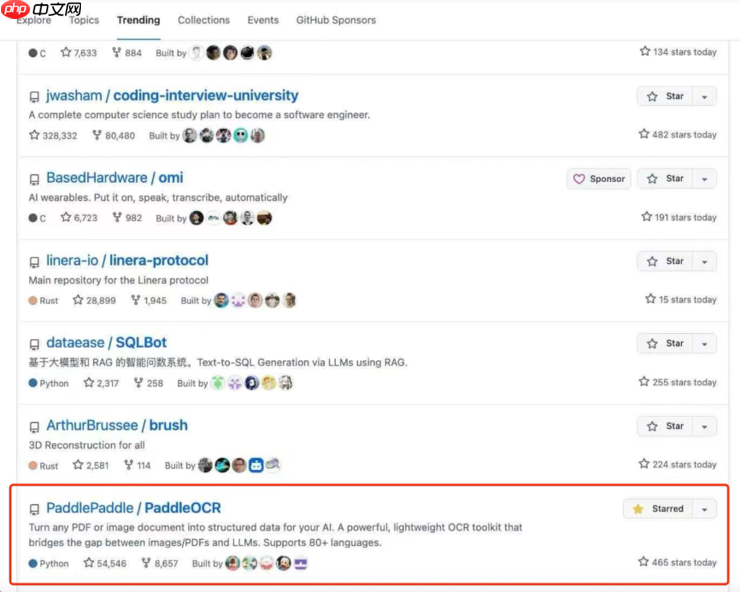
9月18日晚间,PaddleOCR项目成功登上GitHub全球trending总榜,位列Python分类第5名,全类别排名第13位。
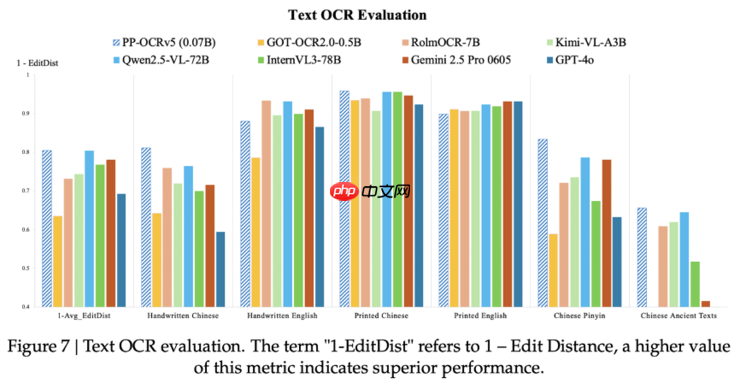
据技术博客介绍,在OCR应用场景下,尽管通用视觉大模型(VLM)具备一定图文理解能力,但在精确文本定位和边界框生成方面仍存在不足,且常伴随高计算成本和“幻觉”问题。相比之下,PP-OCRv5采用模块化双阶段检测与识别架构,能够在保持极低资源消耗的同时,输出更精准的文本边框,实现高效推理。
基准测试结果显示,PP-OCRv5在印刷体中文、英文以及手写英文等关键任务上的识别精度与Qwen2.5-VL-72B这类百亿参数级大模型相当甚至更优;而在手写中文、中文拼音等复杂场景中也始终保持领先水平,展现出强大的泛化能力。
作为百度飞桨团队推出的全场景文字识别解决方案,PP-OCRv5是业内首个单模型支持五种文字类型的超轻量级(
以上就是超越GPT-4o及Qwen2.5-VL,百度超轻量模型PP-OCRv5 Blog持续登顶Hugging Face热度第一的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 435
435
























