
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
一.引言
推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。
主流的大模型强化学习算法,如 DPO、PPO、GRPO 等,通常需要在完整的思维链上进行微调,需要高质量数据、精确的奖励函数、快速反馈和在线迭代、以及大量的算力。当处理复杂任务,如高级数学和编程问题时,模型需要更细粒度的搜索、更精确的推理步骤和更长的思维链,导致状态空间和策略空间的规模急剧扩大,难度大幅上升。
Inference scaling 策略,不依赖训练,通过延长推理时间进一步提高模型的 Reasoning 能力。常见方法,如 Best-of-N 或者蒙特卡洛树搜索(MCTS),允许 LLM 同时探索多条推理路径,扩大搜索空间,朝着更有希望的方向前进。这些方法计算成本高,特别是步骤多或搜索空间大的时候。采样随机性使得确定最佳路径困难,且依赖手动设计的搜索策略和奖励函数,限制了泛化能力。
在此背景下,普林斯顿大学团队联合北京大学团队合作开发了名为 ReasonFlux 的多层次(Hierarchical)LLM 推理框架。

文章链接:https://arxiv.org/abs/2502.06772
开源地址:https://github.com/Gen-Verse/ReasonFlux
(该论文作者特别声明:本工作没有蒸馏或用任何方式使用 DeepSeek R1。)
基于层次化强化学习(Hierachical Reinforcement Learning)思想,ReasonFlux 提出了一种更高效且通用的大模型推理范式,它具有以下特点:
思维模版:ReasonFlux 的核心在于结构化的思维模板,每个模版抽象了一个数学知识点和解题技巧。仅用 500 个通用的思维模板库,就可解决各类数学难题。
层次化推理和强可解释性:ReasonFlux 利用层次化推理(Hierarchical Reasoning)将思维模板组合成思维轨迹(Thought Template Trajectory)、再实例化得到完整回答。模型的推理过程不再是 “黑盒”,而是清晰的展现了推理步骤和依据,这为 LLM 的可解释性研究提供了新的工具和视角,也为模型的调试和优化提供了便利。与 DeepSeek-R1 和 OpenAI-o1 等模型的推理方式不同,ReasonFlux 大大压缩并凝练了推理的搜索空间,提高了强化学习的泛化能力,提高了 inference scaling 的效率。
轻量级系统:ReasonFlux 仅 32B 参数,强化训练只用了 8 块 NVIDIA A100-PCIE-80GB GPU。它能通过自动扩展思维模板来提升推理能力,更高效灵活。

ReasonFlux-32B 在多个数学推理基准测试中表现出色,仅仅用了 500 个基于不同数学知识点的思维模版,就展现了其强大的推理能力和跻身第一梯队的实力。

 ,从而得到 (m=1, n=32, m+n=33)。整个过程逻辑清晰,步骤明确,展示了 ReasonFlux 的规划和推理能力。
,从而得到 (m=1, n=32, m+n=33)。整个过程逻辑清晰,步骤明确,展示了 ReasonFlux 的规划和推理能力。
 。如公式
。如公式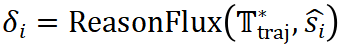 所示,根据评估结果,Navigator 会动态调整模板轨迹
所示,根据评估结果,Navigator 会动态调整模板轨迹 ,例如修改当前步骤的模板、添加或删除步骤等。这种迭代优化的机制使得 ReasonFlux 能够根据问题的具体情况灵活调整推理策略,从而提高推理的准确性和效率。
,例如修改当前步骤的模板、添加或删除步骤等。这种迭代优化的机制使得 ReasonFlux 能够根据问题的具体情况灵活调整推理策略,从而提高推理的准确性和效率。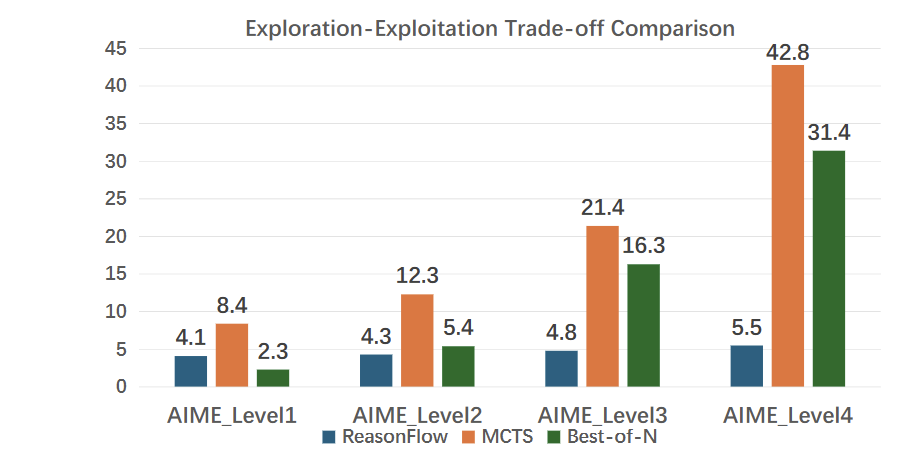


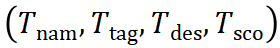 对一个基础 LLM 进行微调,得到模型
对一个基础 LLM 进行微调,得到模型 。训练的目标是让模型能够根据模板的名称和标签,生成对应的描述和适用范围 。通过这个阶段的训练,模型学习到了模板库中蕴含的丰富知识,并具备了初步的模板理解和应用能力。
。训练的目标是让模型能够根据模板的名称和标签,生成对应的描述和适用范围 。通过这个阶段的训练,模型学习到了模板库中蕴含的丰富知识,并具备了初步的模板理解和应用能力。 模型针对输入问题
模型针对输入问题  生成多个候选的 high-level 思维模板轨迹
生成多个候选的 high-level 思维模板轨迹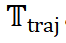 。每个轨迹由一系列步骤
。每个轨迹由一系列步骤  组成,每个步骤都关联到一个特定的模板。为了评估轨迹的质量,我们构建了一组与输入问题
组成,每个步骤都关联到一个特定的模板。为了评估轨迹的质量,我们构建了一组与输入问题 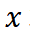 相似的问题集
相似的问题集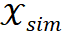 。然后,我们利用 inference LLM
。然后,我们利用 inference LLM 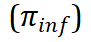 根据模板轨迹对这些相似问题进行具体的解答,并计算平均准确率作为轨迹的奖励
根据模板轨迹对这些相似问题进行具体的解答,并计算平均准确率作为轨迹的奖励 。基于这个奖励信号,我们构建了优化样本对
。基于这个奖励信号,我们构建了优化样本对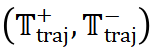 ,其中
,其中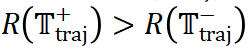 。然后,我们利用这些样本对,通过 DPO 对
。然后,我们利用这些样本对,通过 DPO 对  进行进一步优化,得到最终的 navigator 模型
进行进一步优化,得到最终的 navigator 模型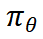 ,也就是我们的 ReasonFlux 模型。
,也就是我们的 ReasonFlux 模型。 
 ,ReasonFlux(即 navigator
,ReasonFlux(即 navigator )首先对其进行分析,并提取出问题的核心数学概念和关系,形成一个抽象表示
)首先对其进行分析,并提取出问题的核心数学概念和关系,形成一个抽象表示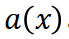 。这一步可以理解为对问题进行 “降维”,提取出问题的本质特征。
。这一步可以理解为对问题进行 “降维”,提取出问题的本质特征。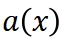 ,ReasonFlux 规划出一个最优的模板轨迹
,ReasonFlux 规划出一个最优的模板轨迹 。这个轨迹可以看作是解决问题的 “路线图”,它由一系列步骤组成,每个步骤都对应一个特定的模板。
。这个轨迹可以看作是解决问题的 “路线图”,它由一系列步骤组成,每个步骤都对应一个特定的模板。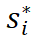 关联的模板名称
关联的模板名称  和标签
和标签 ,ReasonFlux 从结构化模板库
,ReasonFlux 从结构化模板库 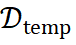 中检索出相关的模板集合
中检索出相关的模板集合  。
。 根据检索到的模板
根据检索到的模板 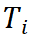 和输入问题
和输入问题  的具体信息,将轨迹中的每个步骤
的具体信息,将轨迹中的每个步骤  实例化为具体的推理步骤
实例化为具体的推理步骤  。这个过程可以理解为将抽象的模板应用到具体的问题中。
。这个过程可以理解为将抽象的模板应用到具体的问题中。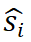 的执行结果,并根据评估结果
的执行结果,并根据评估结果 动态调整模板轨迹。例如,如果发现当前步骤的模板不适用,ReasonFlux 可能会选择另一个模板,或者添加新的步骤。这种迭代优化的机制使得 ReasonFlux 能够根据问题的具体情况灵活调整推理策略,从而提高推理的准确性和效率。
动态调整模板轨迹。例如,如果发现当前步骤的模板不适用,ReasonFlux 可能会选择另一个模板,或者添加新的步骤。这种迭代优化的机制使得 ReasonFlux 能够根据问题的具体情况灵活调整推理策略,从而提高推理的准确性和效率。
杨灵:北大在读博士,普林斯顿高级研究助理,研究领域为大语言模型和扩散模型。
余昭辰:新加坡国立大学在读硕士,北京大学 PKU-DAIR 实验室科研助理,研究领域为大语言模型和扩散模型。
崔斌教授:崔斌现为北京大学计算机学院博雅特聘教授、博士生导师,担任计算机学院副院长、数据科学与工程研究所所长。他的研究方向包括数据库系统、大数据管理与分析、机器学习 / 深度学习系统等。
王梦迪教授:王梦迪现任普林斯顿大学电子与计算机工程系终身教授,并创立并担任普林斯顿大学 “AI for Accelerated Invention” 中心的首任主任。她的研究领域涵盖强化学习、可控大模型、优化学习理论以及 AI for Science 等多个方向。
以上就是8卡32B模型超越o1预览版、DeepSeek V3,普林斯顿、北大提出层次化RL推理新范式的详细内容,更多请关注php中文网其它相关文章!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 508
508




















